Clear Sky Science · en
3D Magic Mirror: clothing reconstruction from a single image via a causal perspective
Trying on clothes without the fitting room
Imagine snapping a single full-body photo with your phone and instantly seeing yourself in 3D, able to spin the image, change viewpoints, or even swap outfits with a friend. This paper tackles the core technical problem behind that “3D Magic Mirror”: turning one ordinary 2D picture of a dressed person into a detailed 3D model of their clothing, without relying on expensive 3D scans or controlled studio photos.
Why turning 2D photos into 3D is so tricky
Turning a flat image into a 3D object is a classic puzzle. Existing systems often start from a fixed digital body template and bend it to match the picture. That works fairly well for rigid body parts like arms and legs, but it breaks down for flowing dresses, draped coats, hair, or handbags, which do not follow a simple, standard shape. Another obstacle is data: there are millions of fashion photos on the web, but almost no large collections of precisely measured 3D garments to train on. Finally, a single photo hides important information. A small coat close to the camera can look identical to a larger one farther away, and lighting and fabric patterns can also confuse a learning algorithm. These ambiguities make it hard for a neural network to “guess” the correct 3D structure.
Teaching AI to separate cause from effect
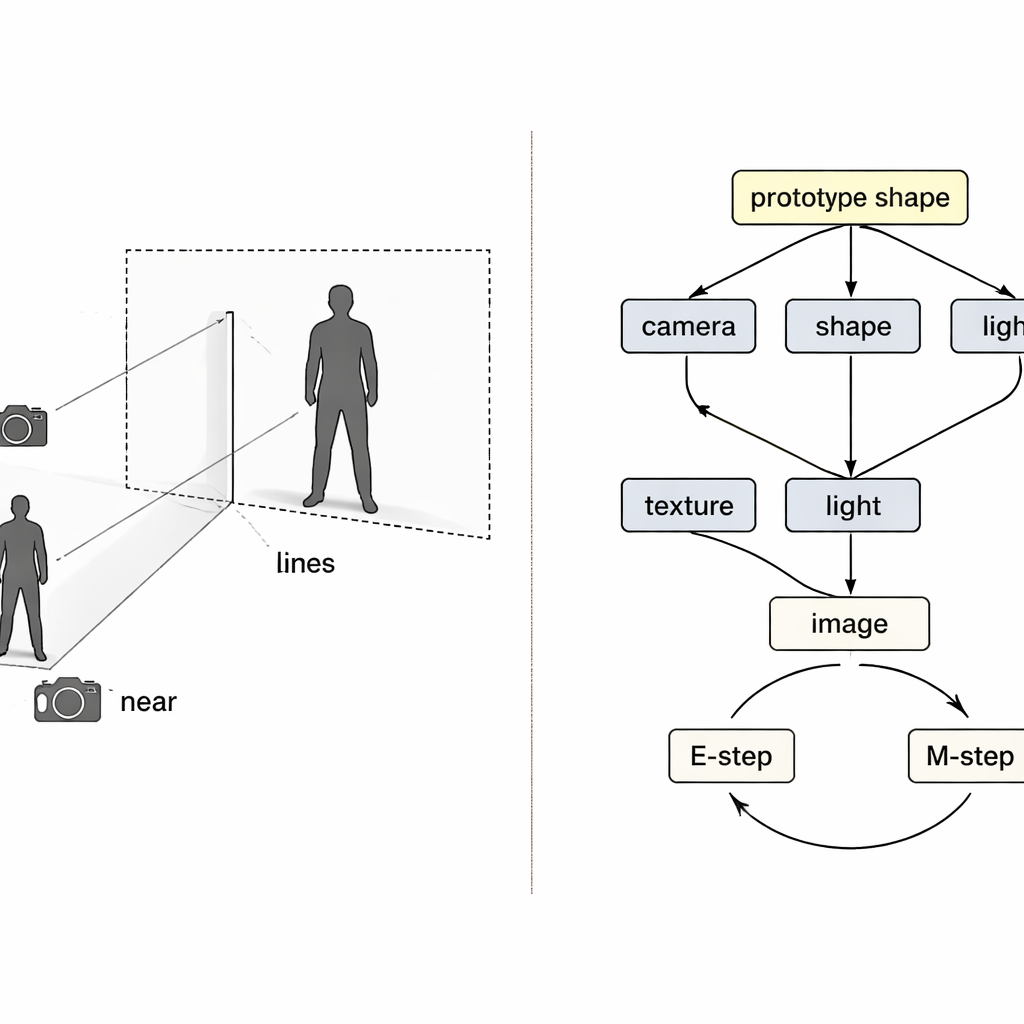
Rather than treating the problem as a black-box mapping from pixels to 3D, the authors borrow ideas from causal reasoning—the mathematics of cause and effect. They view the final image as the outcome of four hidden causes: how the camera is positioned, what the clothing shape is, how it is textured (its colors and patterns), and how it is lit. A special “structural causal map” lays out how these factors combine to produce the observed picture. Guided by this map, the system uses four separate neural encoders, each responsible for one factor. Together with a physics-inspired 3D renderer, they form a loop: image and foreground mask go in, a colored 3D mesh comes out, and then it is projected back to an image that can be compared with the original.
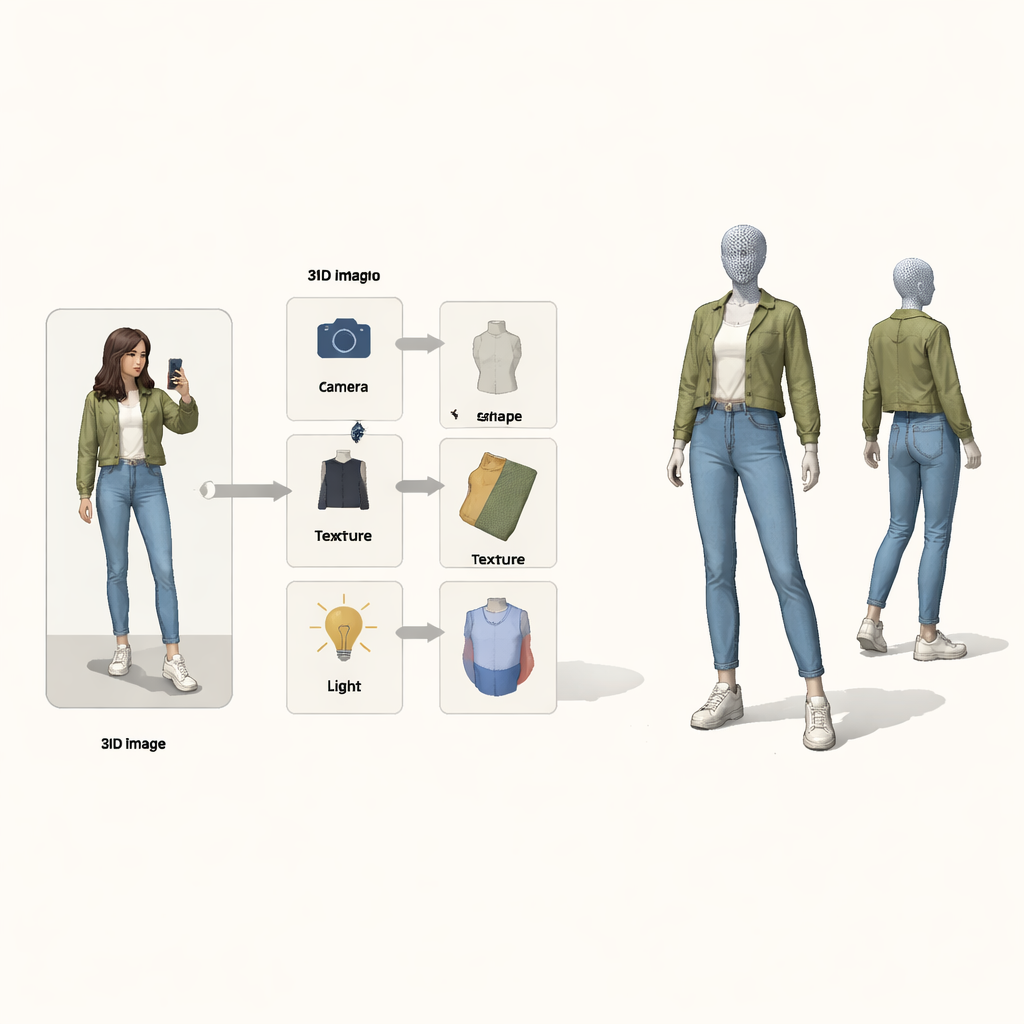
A learning loop that fixes one thing at a time
Even with separate encoders, training can go wrong. If the reconstruction is imperfect, it is unclear which encoder is at fault, and ordinary learning tends to adjust all of them at once. The authors treat this as a classic “collider” problem in causality, where different causes can wrongly compensate for each other. Their solution is to weave two expectation–maximization loops into training. In the first loop, three encoders are temporarily frozen while the fourth alone is updated, so that errors are clearly attributed and that component learns a cleaner role. In the second loop, a shared “prototype” 3D shape—starting as a simple sphere—is slowly updated to become the average human or bird shape in the data. Individual examples only learn small deviations from this prototype, while the camera module takes full responsibility for how large or close the object appears, directly attacking the size-versus-distance confusion.
From fashion photos to birds, and beyond
To test their approach, the researchers train on two large fashion datasets containing ordinary street photos and on a standard collection of bird images. Importantly, they use only 2D foreground masks, not 3D ground-truth meshes. On human clothing, their system outperforms popular body-template methods at matching the true outline of garments and handles non-rigid elements like hair and handbags more faithfully. On birds, it reaches or exceeds the quality of leading single-image 3D reconstruction methods while producing more realistic new viewpoints. The 3D models are flexible enough to support playful applications, such as swapping clothing textures between people or generating synthetic training data to boost person re-identification systems used in surveillance research.
What this means for everyday digital worlds
For non-specialists, the key message is that convincing 3D avatars and virtual try-on tools no longer require costly 3D scanners or rigid templates. By explicitly modeling cause and effect—separating camera, shape, texture, and light, and anchoring them to a shared prototype—the authors show how a system can “explain” a single photo as a 3D scene. While the method still struggles with views it has never seen, such as the back of a person who is only photographed from the front, it marks a significant step toward practical 3D Magic Mirrors that work on the messy, in-the-wild images we actually take.
Citation: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
Keywords: virtual try-on, 3D reconstruction, causal learning, computer vision, fashion AI