Clear Sky Science · en
Human and algorithmic visual attention in driving tasks
Why it matters for everyday driving
As cars become more automated, a key question remains: do self-driving systems actually "see" the road the way humans do? This study looks at how human drivers and artificial intelligence focus their visual attention in traffic, and shows that carefully adding a slice of human-like attention can make driving algorithms both smarter and safer—without needing gigantic, power-hungry AI models.
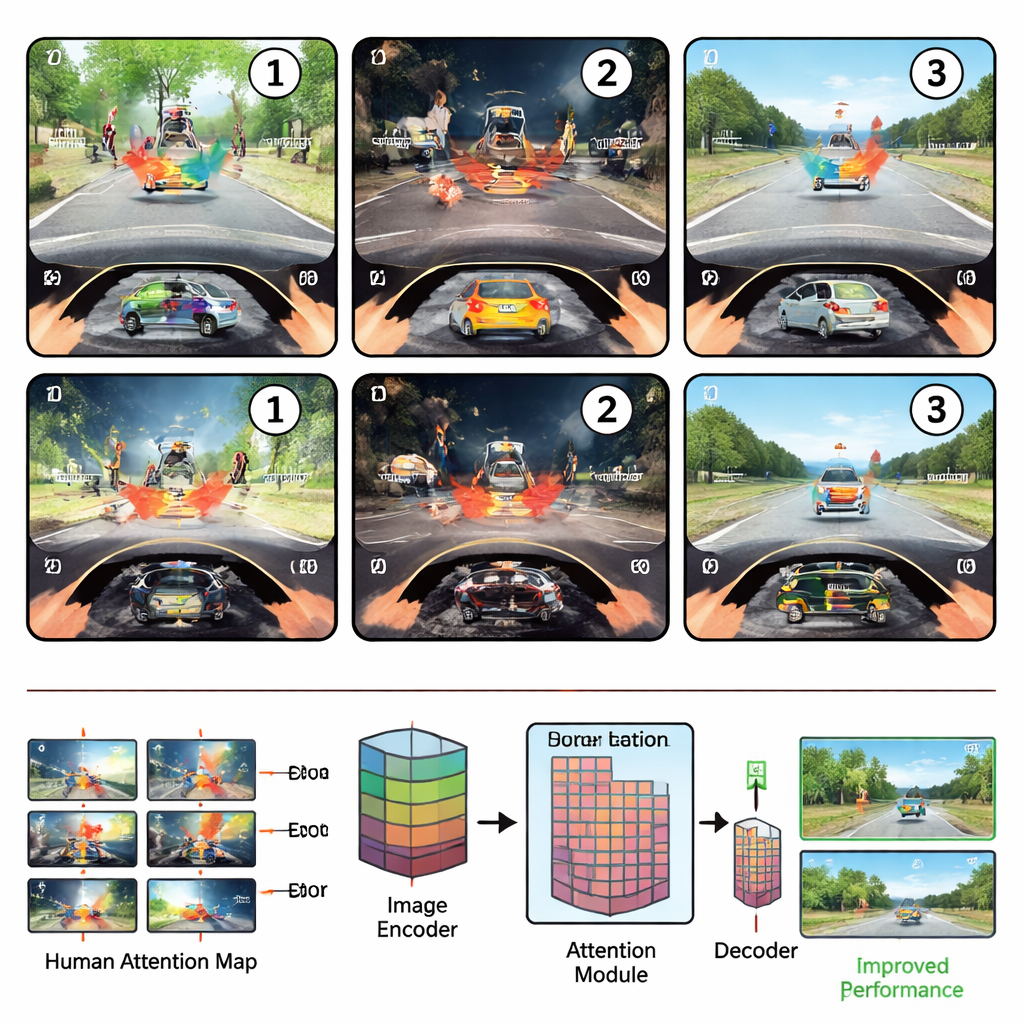
How human eyes move on the road
The researchers first placed novice and experienced drivers in a simulated driving environment and tracked their eye movements while they carried out three common safety tasks: spotting hazards, judging whether it was safe to turn or change lanes, and detecting odd, out-of-place objects. They found that drivers’ attention followed a reliable three-step rhythm. In the scanning phase, right after a scene appears, the eyes sweep broadly across the view, guided mostly by where things are located. In the examining phase, attention locks onto the single most informative region—such as a crossing pedestrian or a blocking car—and studies its details and meaning. Finally, in the reevaluating phase, drivers compare that key object with others, shifting their gaze back and forth to confirm their decision.
Where machines look versus where people look
The team then built an attention-based deep learning model for driving scenes and compared its internal “attention maps” with those from human eye movements. Training the model on general object detection made its attention somewhat more human-like, but fine-tuning it for specific driving tasks often moved it away from human patterns, especially in the rich, meaning-focused examining phase. Overall, correlations between human and algorithmic attention remained modest, suggesting that current driving AI has difficulty discovering the organizing principles behind where humans look and why.
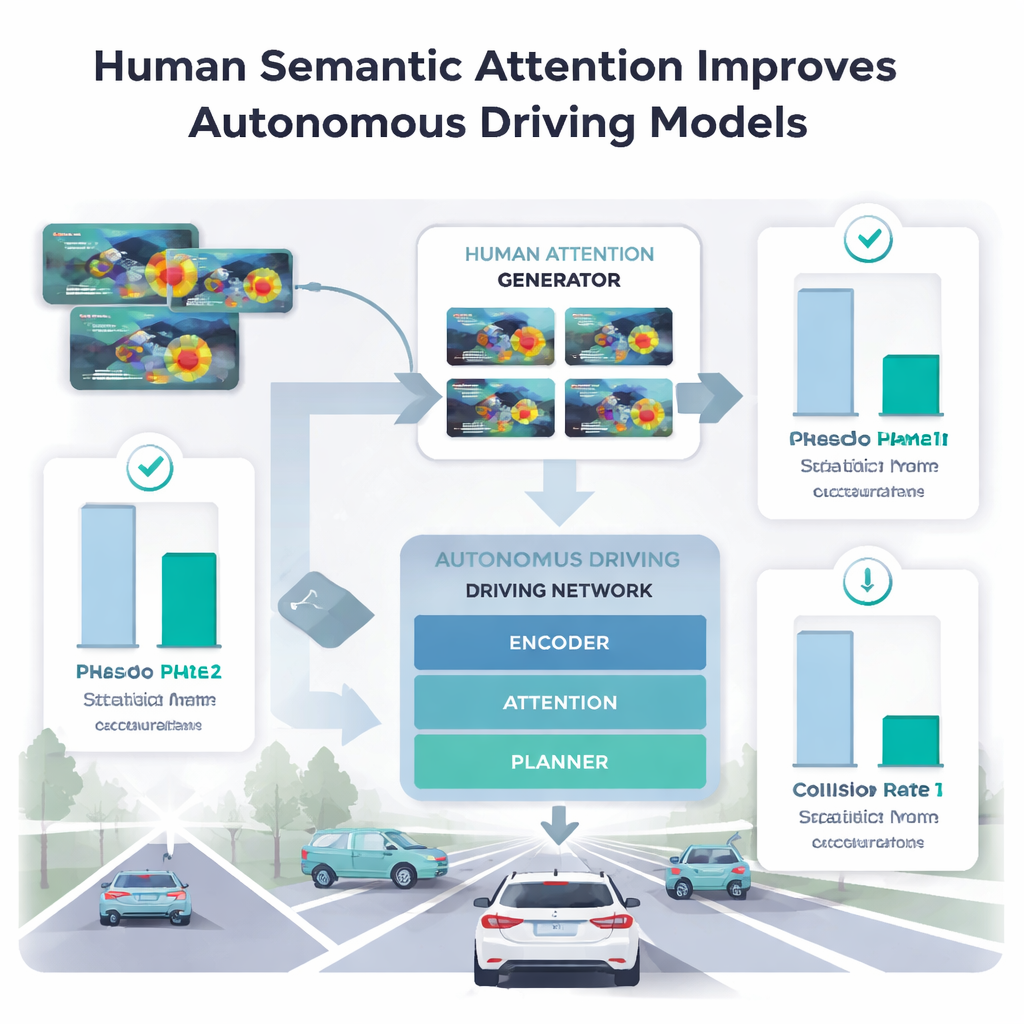
Teaching cars to borrow human focus
To see which parts of human attention actually help machines, the authors fed different phases of human gaze into their driving model. Directly collecting eye-tracking data for millions of images is impractical, so they trained a separate "human attention generator" on a small sample from just five drivers. This generator learned to predict human-like attention heatmaps for new scenes. When the main driving model used only the spatial, early scanning phase, its performance on anomaly detection and trajectory planning often got worse or produced safer-looking paths that were more collision-prone. In contrast, when it used the examining phase—where humans concentrate on the single most meaningful region—accuracy improved beyond previous methods that used full-length gaze, and collision rates in planning tasks dropped.
What big vision-language models still miss
The researchers also tested large vision–language models that answer driving questions or generate dense captions for 3D street scenes. For a question-answering task that emphasizes high-level reasoning, adding human attention barely helped and sometimes hurt, implying that such models already capture much of the needed abstract knowledge. But for a demanding captioning task that requires pinning precise words to precise objects, the human examining-phase attention still delivered large gains. This suggests that big models may reason well in general, yet still stumble when they must tightly link words to the exact spots in a busy visual scene—a gap human gaze can help close.
What this means for safer automated cars
In plain terms, the study argues that what truly separates people from today’s driving AI is not just where we look, but how we instantly judge what matters in a scene. That compact burst of semantic attention—when we scrutinize the one region that makes a situation safe or dangerous—turns out to be exactly the signal many algorithms lack. By learning to mimic this phase from a small amount of eye-tracking data, driving systems can gain human-like understanding of road scenes without relying solely on ever-larger, more expensive AI models. This “semantic shortcut” could be an efficient way to make future automated cars more reliable in the messy, unpredictable conditions of real-world traffic.
Citation: Zheng, C., Li, P., Jin, B. et al. Human and algorithmic visual attention in driving tasks. npj Artif. Intell. 2, 23 (2026). https://doi.org/10.1038/s44387-026-00079-1
Keywords: autonomous driving, visual attention, human eye tracking, vision-language models, traffic safety