Clear Sky Science · en
The role of large language models in emergency care: a comprehensive benchmarking study
Why this matters for anyone who might visit the ER
Emergency rooms are busier than ever, with longer waits and fewer staff to care for growing numbers of critically ill patients. This study asks a question that affects nearly everyone: can modern AI systems, known as large language models, safely help doctors and nurses work faster and smarter in the emergency department? By putting several leading AIs through a series of medical tests and simulated ER cases, the researchers explore how close these tools are to becoming trustworthy "co-pilots" in urgent care.
Emergency rooms under intense pressure
The paper begins by outlining a mounting crisis in emergency care, especially in the United States. An aging population and a rise in chronic illnesses are driving record numbers of ER visits, topping roughly 155 million in 2022 alone. At the same time, hospitals face severe shortages of nurses and physicians, and the number of beds per person has fallen over recent decades. A fragmented health system makes it harder to coordinate care, increasing the risk of delays and errors. Against this backdrop, the authors argue that new tools are urgently needed to help clinicians triage patients, make rapid decisions, and document care without adding to their workload.
How the researchers tested medical AI
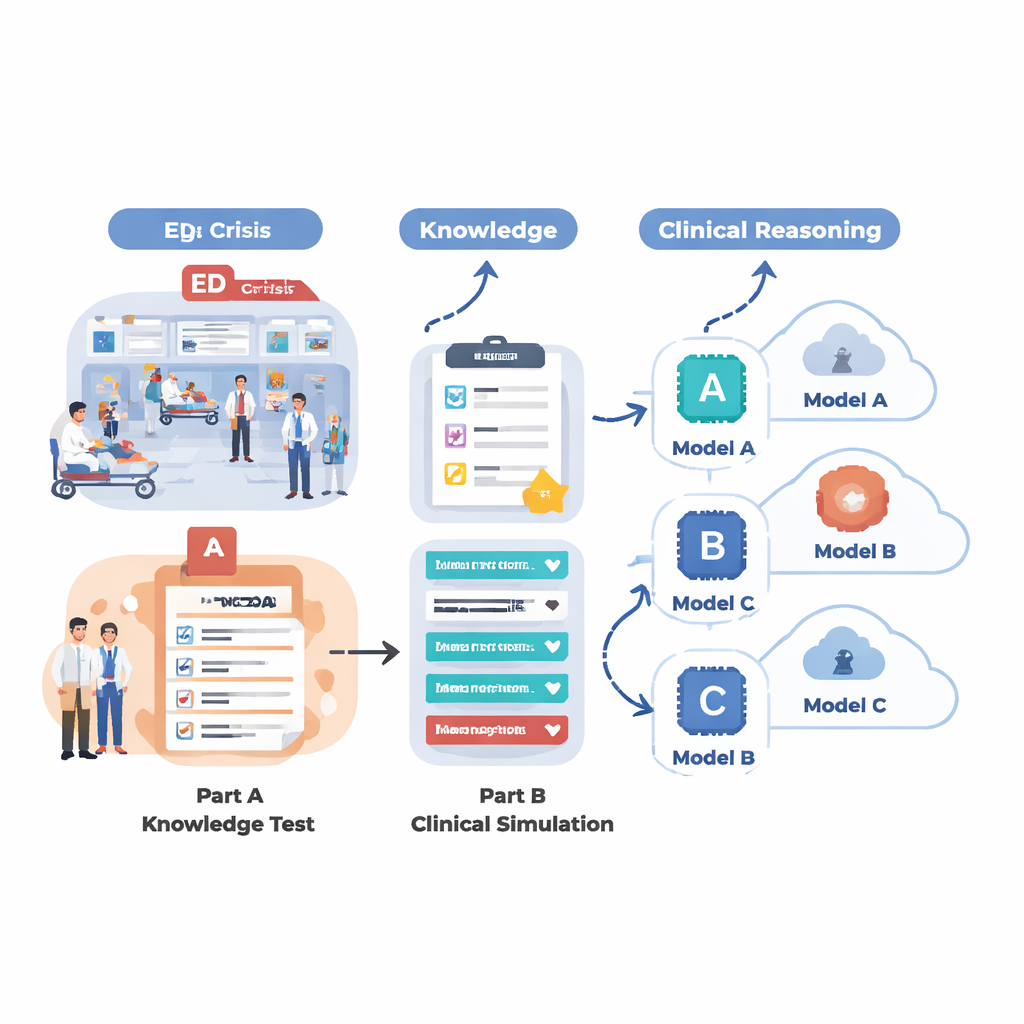
To see what today’s AI systems can really do in an ER-like setting, the team designed a two-part evaluation. First, they tested 18 different language models on a large set of multiple-choice questions drawn from MedMCQA, a medical exam-style dataset covering 12 common ER complaints such as chest pain, shortness of breath, headache, and abdominal pain. This phase measured basic medical knowledge: could the AI pick the right answer from four options across thousands of questions? Second, they took the five strongest models from that round and asked them to work through 12 realistic emergency cases, step by step, just as a doctor would. For each case, the AI had to summarize the patient, assign a triage urgency score, suggest key follow-up questions, propose management steps, and list likely diagnoses as new information (vital signs, history, exam findings, lab and imaging results) was gradually revealed.
Which AI models knew the facts—and which could reason
On pure factual recall, several models performed impressively. A specialized system called LLaMA 4 Maverick scored about 91 percent overall accuracy on the medical questions, closely followed by LLaMA 3.1, GPT-4.5, GPT-5, and Claude 4. These top models were consistently strong across different chief complaints, suggesting that frontier AIs may be nearing a ceiling in textbook-style medical knowledge. Mid-tier systems lagged well behind, with some scoring close to 60 percent and struggling in key areas such as wound care and breathing problems. However, when the task shifted from answering isolated questions to reasoning through rich, evolving patient stories, differences became sharper. In these clinical simulations, GPT-5 clearly stood out: it produced the most accurate and complete summaries, asked the most helpful follow-up questions, recommended sensible and safe next steps, and offered the most thorough and well-ordered lists of possible diagnoses.
Strengths, weaknesses, and safety concerns
Clinicians carefully rated each AI’s output for accuracy, relevance, and safety. GPT-5 not only earned the highest scores overall; it was also the only model whose performance stayed steady or improved as cases became more complex, while still keeping hallucinations and serious errors below about 2 percent. Other models showed distinct patterns of weakness. Some tended to miss secondary diagnoses or place minor problems ahead of dangerous ones. Others became overly cautious or vague, or locked too quickly onto a single diagnosis. Across the board, most systems underestimated how sick patients were when assigning triage levels, a conservative bias that could delay urgent care if not corrected. The findings highlight a key point: knowing medical facts is not the same as reliably weaving those facts into safe, step-by-step decisions when information is incomplete, messy, and changing.

What this could mean for future ER visits
The authors conclude that while several modern AIs now rival one another in medical knowledge, GPT-5 in particular shows a new level of reasoning ability that could make it useful as a decision-support tool in emergency departments. They stress that these systems are not ready to replace clinicians or act on their own. Instead, the most promising near-term role is as a supervised assistant—helping triage nurses estimate urgency, drafting patient summaries, suggesting questions or tests, and checking whether serious diagnoses have been considered. The study also underscores that more research is needed in live clinical settings, with strong safety checks and clear rules for use. For patients, the message is cautious optimism: AI is getting better at thinking through medical problems, but its safe use in the ER will depend on careful design, oversight, and a continued focus on supporting—not substituting—the human judgment of doctors and nurses.
Citation: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
Keywords: emergency medicine, large language models, clinical decision support, triage, medical AI benchmarking