Clear Sky Science · en
Scalable and robust multi-bit spintronic synapses for analog in-memory computing
Why smarter memory matters for everyday AI
From voice assistants to photo apps, modern artificial intelligence leans heavily on deep neural networks—programs that juggle millions of tiny numerical “weights” to make decisions. Moving those weights back and forth between memory and processors costs far more energy than the math itself. This paper explores a new kind of magnetic memory cell that can both store these weights and help perform the calculations directly where the data live, promising faster and more efficient AI hardware.
Bringing brain-like computing into the memory chip
Today’s computers follow the classic “von Neumann” setup, where data constantly shuttle between memory and a separate processor. Neural networks, which boil down to massive numbers of matrix–vector multiplications, hit this bottleneck hard. A promising alternative is in-memory computing, where a large grid (a crossbar array) of memory cells holds the network’s weights and simultaneously turns incoming voltages into output currents that represent the math. Many experimental memory devices have been tried for this role, but they often suffer from noisy behavior and drifting values, which is risky when each cell must represent more than just a 0 or 1.
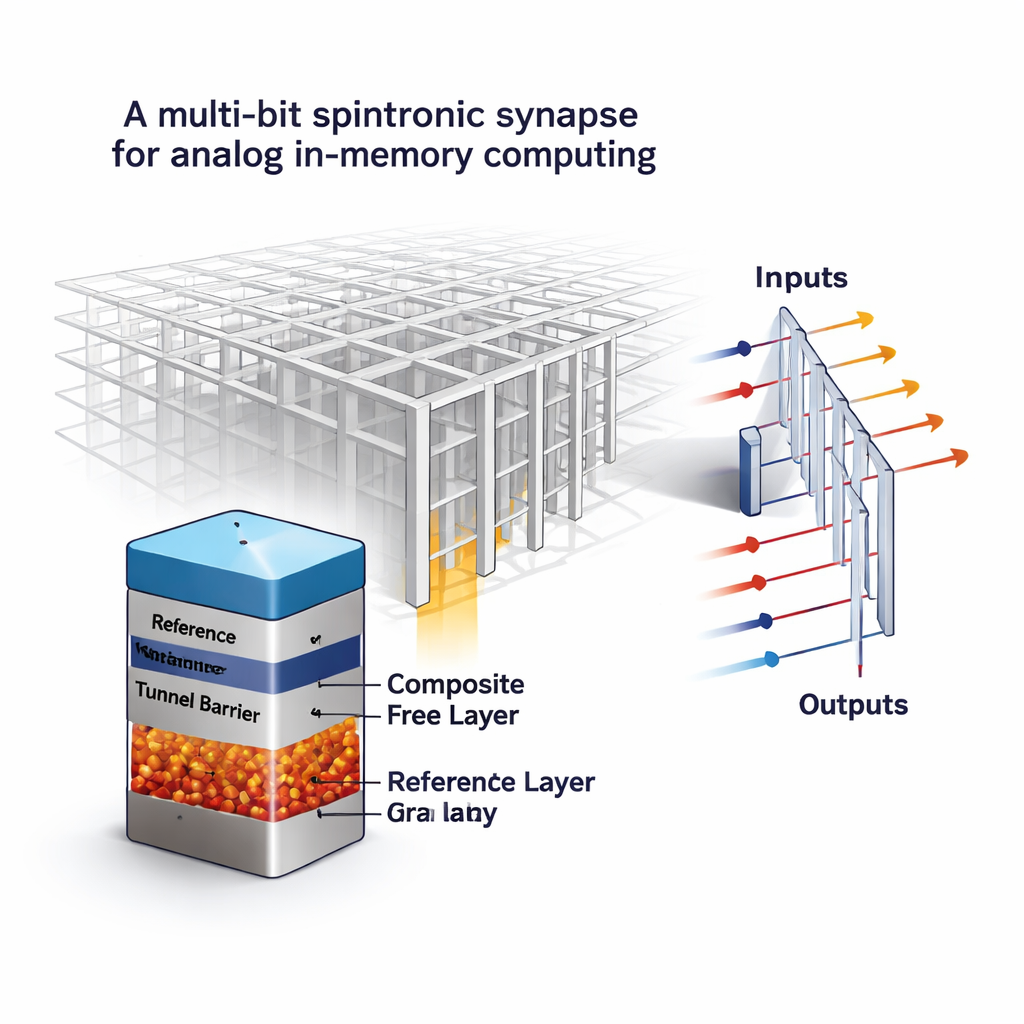
Turning magnetic memory from on–off to “analog”
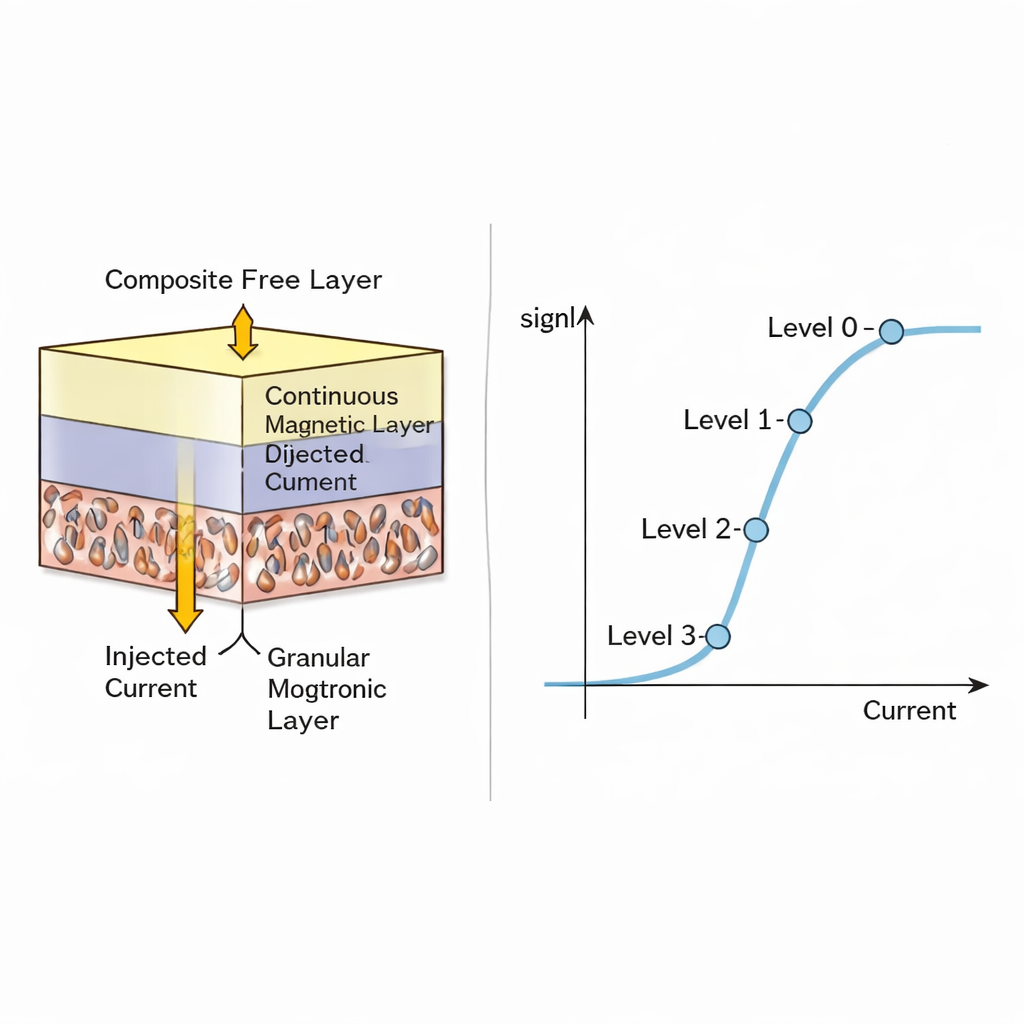
The authors build on magnetic random-access memory (MRAM), a non-volatile technology already valued for speed, durability, and compatibility with standard chip processes. A conventional MRAM cell is a magnetic tunnel junction: two magnetic layers separated by an insulating barrier. Depending on whether the layers line up or oppose each other, the cell’s electrical resistance is low or high, encoding a single bit. The key twist here is to redesign the “free” magnetic layer so it is no longer a uniform block that flips all at once. Instead, the new design combines a very thin continuous film on top of a thicker, granular magnetic layer made up of many tiny magnetic grains. Each grain can flip its direction at slightly different currents, so the overall resistance can settle into several intermediate, stable levels rather than only “low” and “high.”
How many shades of magnetism are useful?
Using detailed computer models of the magnetic dynamics, the team shows that injecting a spin-polarized current into this composite layer causes a gradual, grain-by-grain switching process. As the current is swept, the average magnetization and thus the resistance trace out a smooth S-shaped curve, enabling near-continuous analog states. The authors then examine how manufacturing differences between cells and random thermal effects from one write cycle to the next disturb these levels. They find that while the middle states are somewhat noisier, the extreme states (fully switched one way or the other) remain very tight and robust. For realistically sized devices (around 50–75 nanometers on a side), they conclude that four reliably distinguishable resistance levels—equivalent to 2 bits per cell—are practical without excessive errors.
From single cell to full AI accelerator
To be useful, this multi-level MRAM must be read accurately and integrated into full computing systems. The authors design and simulate a sensing circuit that uses a fast “flash” analog-to-digital converter to distinguish among the four resistance levels of each cell. They explore how the contrast between the highest and lowest conductance states affects read speed, energy use, and the size of the sensing circuitry, showing that better contrast leads directly to faster, more energy-efficient reads. Next, they embed their 2-bit-per-cell MRAM model into a simulated in-memory accelerator running a ResNet-18 neural network on the CIFAR-10 image dataset. Compared to a baseline that uses standard 1-bit MRAM cells, the multi-bit version roughly doubles storage density and cuts the required number of crossbar tiles in half. This translates into up to about 1.8× reductions in chip area, energy, and latency, and more than a 3× improvement in the combined energy–delay metric, all while essentially preserving the network’s recognition accuracy.
How it stacks up against other memory ideas
The study also compares this approach to competing technologies such as resistive RAM and phase-change memory, as well as other magnetic concepts that rely on moving domain walls or skyrmions. While those alternatives can also produce analog-like behavior, they often need larger devices or special shapes and tend to be more unpredictable. In contrast, the granular MRAM cells retain the manufacturing friendliness and endurance of mainstream MRAM while gaining extra storage levels. System-level tests suggest that, under realistic variations, MRAM-based synapses keep neural network accuracy much higher than similar designs built on more variable resistive memories, especially when networks are made sparse to save further energy.
What this means for future everyday AI
In plain terms, the authors have shown a way to teach a proven magnetic memory technology to store not just zeros and ones, but small analog weight values directly inside a compact cell. By carefully engineering a layered structure that splits the magnetic behavior among many tiny grains, they obtain multiple stable resistance levels that are robust enough for real-world AI tasks. When these cells are arranged in large arrays and paired with suitable sensing circuits, they can perform the core computations of deep learning while dramatically cutting down data movement. If realized in hardware, such multi-bit spintronic synapses could make future AI systems—whether in data centers, smartphones, or embedded sensors—faster and more energy-efficient without sacrificing accuracy.
Citation: Gupte, K.K., Mugdho, S.S., Huang, C. et al. Scalable and robust multi-bit spintronic synapses for analog in-memory computing. npj Unconv. Comput. 3, 8 (2026). https://doi.org/10.1038/s44335-026-00055-7
Keywords: in-memory computing, spintronic memory, MRAM, neuromorphic hardware, deep neural networks