Clear Sky Science · en
An evaluation of estimative uncertainty in large language models
Why fuzzy words about risk really matter
When a doctor says a treatment is “likely” to work, or a weather forecaster warns there is “little chance” of a hurricane, we rely on these fuzzy words to make real decisions. Today, large language models (LLMs) such as online chatbots are starting to use the same vocabulary. This study asks a simple but crucial question: when an AI says “probably,” does it mean the same thing we do—and can it reliably turn raw numbers into everyday uncertainty words?
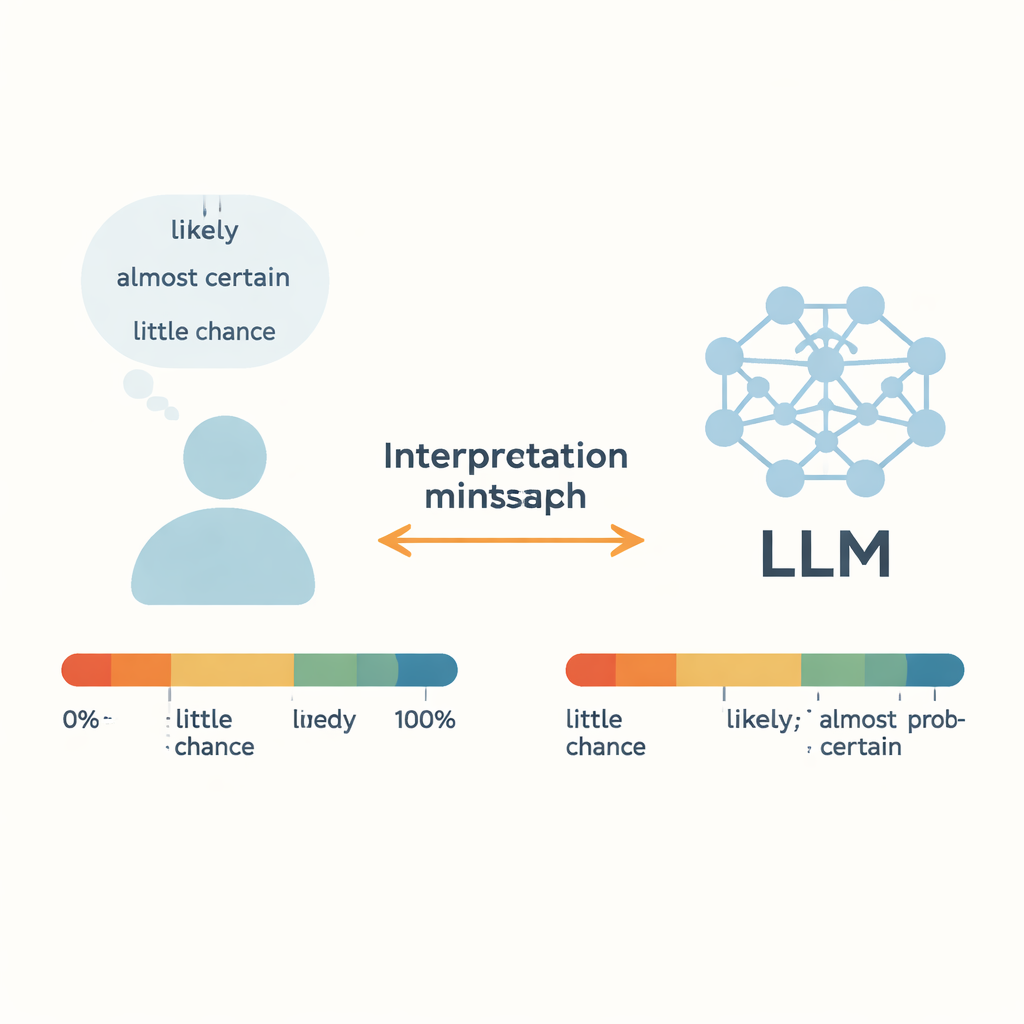
Putting everyday uncertainty under the microscope
The authors focus on “Words of Estimative Probability” (WEPs)—terms like “almost certain,” “likely,” and “little chance” that people use instead of exact percentages. Earlier work, going back to intelligence analysts in the 1960s, tried to link these words to numerical probabilities by surveying people. This study compares those human judgments with the output of five modern LLMs, including GPT-3.5, GPT-4, Meta’s Llama models, and a Chinese system called ERNIE-4.0. For 17 common uncertainty words, each model was given short story-like prompts in English or Chinese and asked to respond with a numeric probability between 0 and 100 percent. By repeating this across many contexts, the authors built full probability distributions for each word and each model, then compared them to human survey data.
Where humans and AIs speak the same language
For the most extreme expressions—such as “almost certain” at the high end and “almost no chance” at the low end—LLMs and humans line up surprisingly well. Both people and models tend to cluster these phrases within narrow, high- or low-probability ranges, suggesting that these strong terms have relatively stable meanings across contexts. The same is true for “about even,” which most humans and the models treat as roughly a 50–50 chance. Statistical tests show little meaningful difference between human and model distributions for these particular words, implying that LLMs can capture clear-cut cases of near-certainty or near-impossibility with human-like precision.
Where meanings quietly drift apart
Ambiguous, middle-of-the-road words tell a different story. For expressions such as “likely,” “probable,” “we doubt,” and “little chance,” the models’ numeric interpretations differ significantly from human judgments. GPT-4, despite being more capable overall than GPT-3.5, often shows larger gaps. The authors suggest that this may be because such words blend two things: a sense of probability and a speaker’s attitude or stance. In real conversations, “likely” can sound cautious or confident depending on tone and context, and “we doubt” may express skepticism rather than a precise probability. Trained on vast, mixed-genre text from the internet, LLMs may average over many conflicting uses, blurring these subtleties. The result is a hidden mismatch: humans and AIs may see the same sentence and quietly attach different numbers to the same word.
Gender, language, and cultural echoes
The researchers also tested how gendered wording and different languages shape these probability words. When prompts referred to “he” or “she” instead of gender-neutral subjects, GPT-3.5 and GPT-4 often produced less variable, more “locked-in” probability estimates, sometimes collapsing to a single point. This suggests that the models may have absorbed rigid patterns from stereotypes in their training data, even though overall averages for male and female prompts were similar. Comparing English and Chinese prompts, GPT models showed noticeable shifts in how they interpreted the same uncertainty words. ERNIE-4.0, trained mainly on Chinese text, was closer to Chinese-speaking humans on many terms but still over- or underestimated certain phrases. These findings highlight that how an AI talks about uncertainty depends not just on the word chosen, but on the language and cultural patterns embedded in its training.
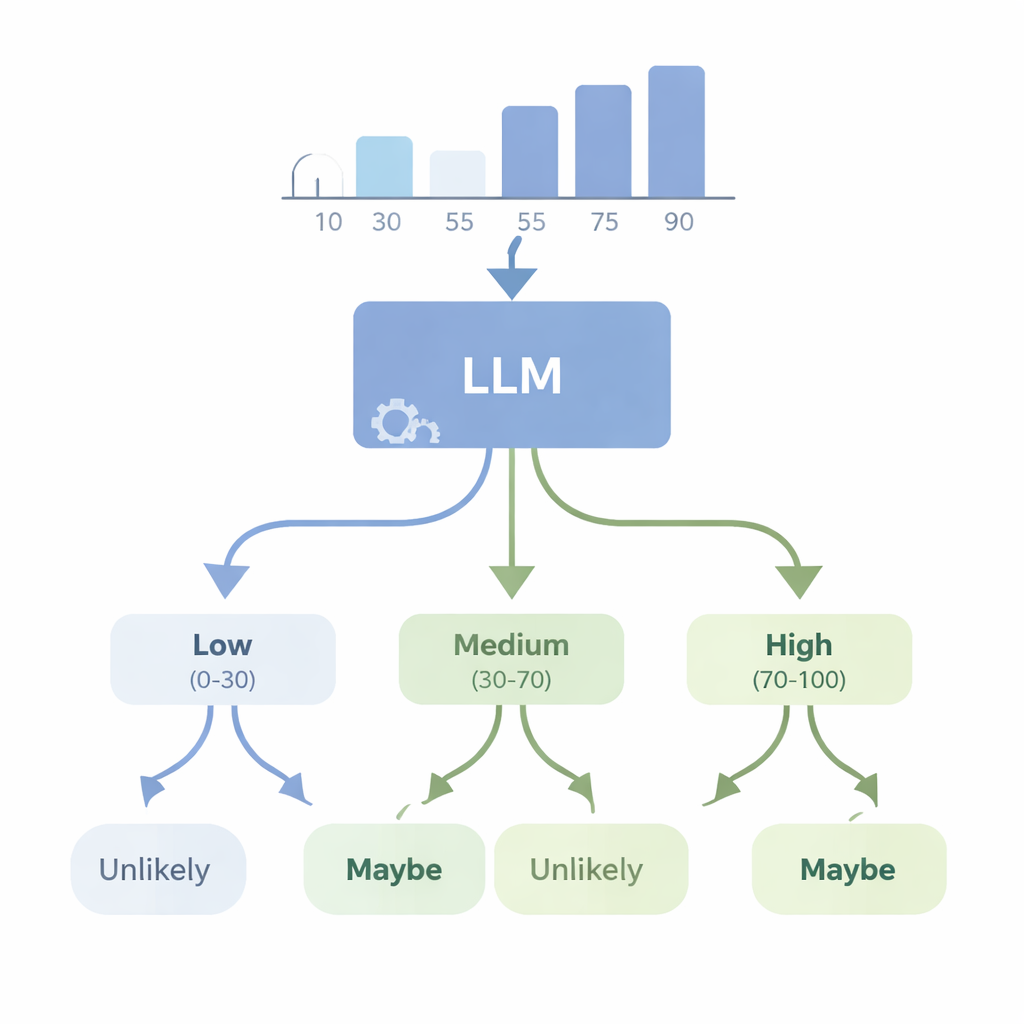
Can AIs turn numbers into plain-language doubt?
In a second set of experiments, the authors looked at the reverse problem: can an advanced model like GPT-4 start from numerical data and choose an appropriate uncertainty word? They fed the model simple datasets—such as lists of heights or test scores—and asked it to pick the best-fitting WEP (for example, “almost certainly,” “likely,” “maybe,” “unlikely,” or “almost certainly not”) for statements about future outcomes. They then evaluated GPT-4 with four new “consistency” scores that check whether its word choices make logical sense when probabilities go up or down, when complementary events are described, and when the underlying numbers change in controlled ways. GPT-4 did much better than random guessing and could often track rough changes in likelihood, but it fell far short of perfect consistency. In some tests it responded almost the same way across different confidence levels, suggesting that it sometimes treats these words as broad labels rather than a finely tuned scale linked to the actual data.
What this means for real-world decisions
For readers, the message is cautionary but not alarmist. LLMs can already mimic our strongest expressions of certainty and impossibility, and they can often summarize data into reasonable “likely” or “unlikely” statements. But this study shows that for many everyday uncertainty words, their internal calibration does not fully match human intuition, and their mapping from numbers to language can be inconsistent. In domains like medicine, policy, or science communication—where small shifts in how we phrase risk or confidence can matter—a model’s “probably” may not be the same as yours. The authors argue that to use these systems safely, we must treat uncertainty words as a shared codebook that still needs careful alignment, testing, and perhaps explicit numerical backing, rather than assuming that human and machine mean the same thing by default.
Citation: Tang, Z., Shen, K. & Kejriwal, M. An evaluation of estimative uncertainty in large language models. npj Complex 3, 8 (2026). https://doi.org/10.1038/s44260-026-00070-6
Keywords: uncertainty language, large language models, probability words, human-AI communication, risk interpretation