Clear Sky Science · en
Fairness analysis of machine learning predictions of aggression in acute psychiatric care
Why this matters for real people
Hospitals are turning to artificial intelligence to spot which patients might become aggressive, hoping to prevent harm without resorting to traumatic restraints. But if these prediction tools are unfair, they can worsen the very inequities that already shape who is seen as “dangerous.” This study asks a pressing question: when a machine helps decide who is high risk in a psychiatric unit, does it treat all patients equally?
Using hospital data to flag short-term risk
Researchers analyzed records from more than 17,000 patients treated on acute psychiatric units at a large Canadian mental health hospital between 2016 and 2022. For each of up to three days during a hospital stay, staff recorded a standard bedside checklist called the Dynamic Appraisal of Situational Aggression (DASA), which rates behaviors like irritability or verbal threats that might signal imminent aggression. The team combined these scores with information collected at admission, such as diagnosis, age, gender, race or ethnicity, housing situation, and how the person came to the hospital, to train a machine-learning model that predicted whether the patient would be involved in an aggressive incident (including use of restraints or seclusion) in the next 24 hours.
How the prediction tool performed overall
The best-performing system used a popular machine-learning method called a random forest. On held-out test data it correctly ranked higher-risk days much of the time, achieving an “area under the curve” of about 0.81, comparable to similar tools in psychiatry. However, aggression was rare—there were roughly 33 days without incidents for every day with one—so the model still missed many true events and generated some false alarms. Measures of importance showed that moment-to-moment clinical factors, especially DASA items like irritability and prior recent incidents, contributed most strongly to predictions, rather than demographics alone. This means the model was picking up on clinically meaningful warning signs, but performance metrics alone did not reveal whether it was equally trustworthy for everyone.
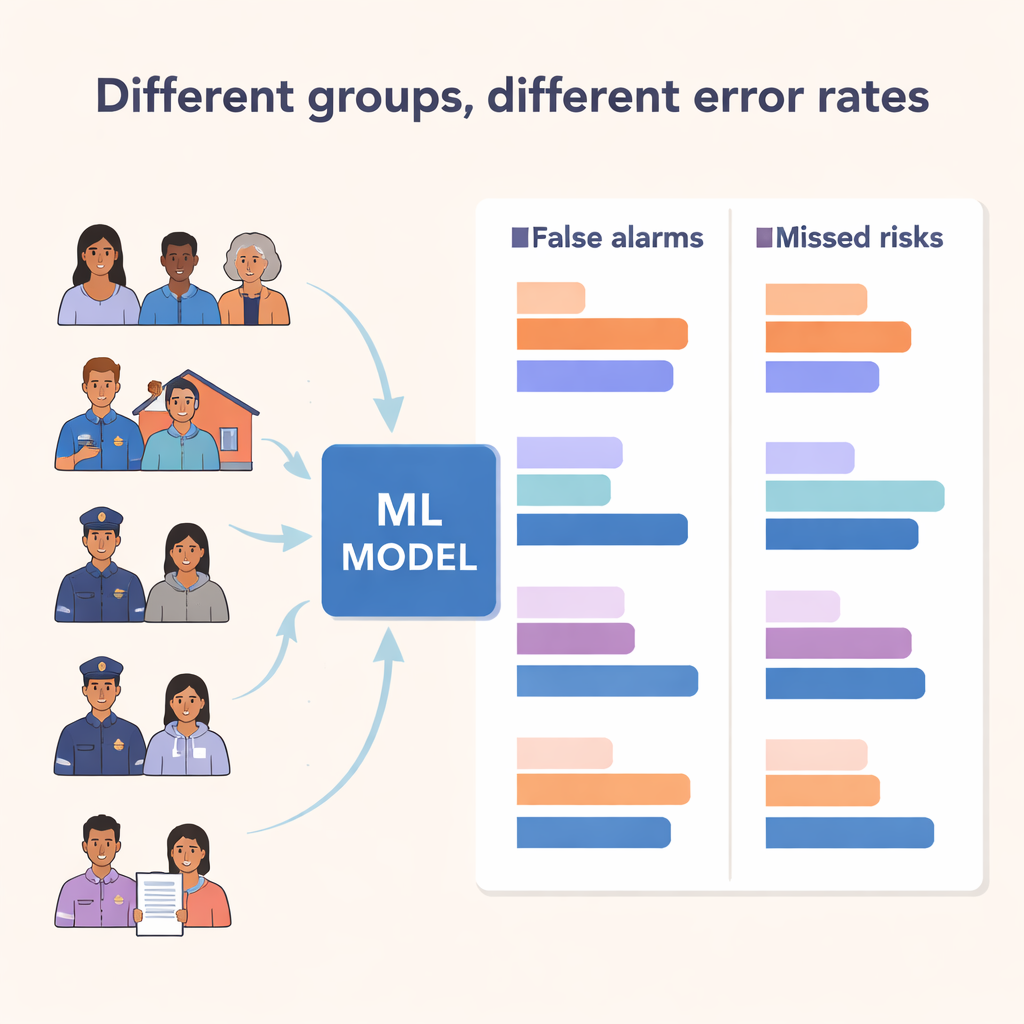
Unequal errors across different groups
The heart of the study was a fairness check. The team focused on two types of errors: false positives, where the model flags risk but nothing happens, and true positives, where it correctly anticipates an incident. A fair model, by one commonly used standard called “equalized odds,” should have similar false positive and true positive rates across groups. Instead, the researchers found large differences. False positives were higher for Middle Eastern and Black patients, men, people brought to the hospital by police, and those who were unhoused or in supportive housing. Some groups—such as patients admitted by police or those with unstable housing—had both higher detection rates and higher false alarms, suggesting the model was tuned to be extra sensitive for them. Others, like Black patients, experienced a concerning combination: more false alarms and poorer ability to correctly identify true risk.
When identities intersect, gaps widen
Because people’s experiences are shaped by more than one characteristic at a time, the researchers also examined overlapping identities, particularly the combination of race or ethnicity and gender. Here, the biggest red flag emerged for Middle Eastern men, who had the highest false positive rate of any group, while Middle Eastern women did not. Black and Indigenous men also faced elevated false positives compared with women of the same background. These patterns echo well-documented inequalities in mental health care, such as higher rates of police involvement, involuntary admission, and misdiagnosis among certain racialized groups and men. The machine-learning system did not create those inequities, but it learned from data steeped in them—and risked amplifying them in clinical decisions.
What this means for future AI in psychiatry
The authors argue that fairness analysis must be treated as a core safety check, not an optional extra, before any predictive tool is put into practice. They note that technical “debiasing” methods—such as adjusting training data or setting different alert thresholds for different groups—can help, but they are limited if the underlying records already reflect unequal treatment and coercive practices. Ultimately, deciding what counts as a “fair” model is not just a math problem; it is a social and ethical question that requires input from patients, clinicians, and communities. This study shows that while machine learning can help identify short-term aggression risk, it can also silently reproduce structural racism, sexism, and housing inequities unless fairness is rigorously measured, debated, and addressed.
Citation: Wang, Y., Sikstrom, L., Xiao, R. et al. Fairness analysis of machine learning predictions of aggression in acute psychiatric care. npj Mental Health Res 5, 16 (2026). https://doi.org/10.1038/s44184-026-00194-6
Keywords: algorithmic fairness, psychiatric aggression, machine learning in healthcare, health inequities, risk prediction models