Clear Sky Science · en
Preconditioned inexact stochastic ADMM for deep models
Smarter Training for Smarter AI
Modern artificial intelligence systems, from chatbots to image generators, are powered by massive neural networks that are notoriously difficult and expensive to train. As companies and researchers spread data across many devices and servers, today’s standard training methods often slow down, become unstable or simply fail to cope with the messiness of real-world data. This article introduces a new family of training algorithms, centered on a method called PISA, that promises faster, more reliable learning for a wide range of deep models while making fewer mathematical assumptions about the data.
Why Current Training Methods Struggle
Most deep learning models are trained with variants of stochastic gradient descent, an approach that repeatedly nudges model parameters in the direction that reduces error. Over the years, many refinements—such as Adam, RMSProp and others—have tried to make these nudges smarter by adapting step sizes or adding momentum. However, these methods usually assume that training data are neatly shuffled and statistically similar across machines, and that certain mathematical quantities remain bounded. In practice, especially in settings like federated learning where phones or edge devices hold very different data, these assumptions are often violated, leading to slow convergence or poor performance.
A New Way to Coordinate Many Learners
The authors build on a different optimization framework known as the alternating direction method of multipliers (ADMM), which is good at splitting a large problem into many smaller ones that can be solved in parallel. Their main contribution, PISA (preconditioned inexact stochastic ADMM), keeps the strengths of ADMM while avoiding its usual drawbacks—such as the need to compute full gradients over all data or perform expensive matrix inversions. Instead, PISA lets each client or worker node update its own copy of the model using only a mini-batch of data, then coordinates these updates through a central variable. Carefully designed "preconditioning" matrices reshape the update directions so that learning progresses more smoothly and efficiently. 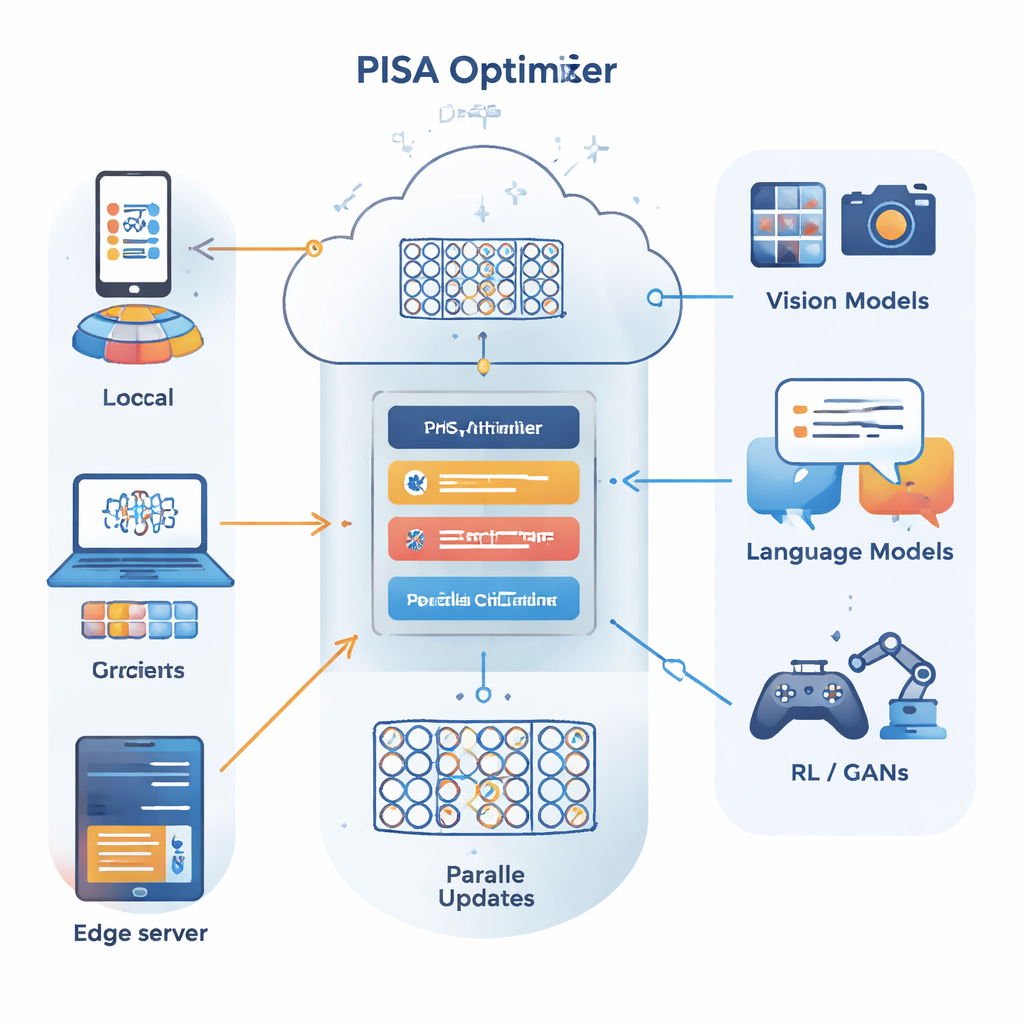
Stronger Guarantees with Milder Assumptions
A distinctive feature of PISA is its theoretical foundation. The authors prove that their algorithm converges under a single, relatively mild assumption: that the gradient of the loss function is Lipschitz continuous within a bounded region, a condition satisfied by many standard neural network losses. Unlike most stochastic methods, PISA does not require gradients to be unbiased, to have bounded variance, or to be drawn from perfectly mixed data. Despite this relaxed setup, the method achieves a linear convergence rate in terms of how fast function values and parameter updates stabilize, placing it among the best-performing algorithms in the comparison table provided. This makes PISA especially attractive for heterogeneous, non-uniform data distributions that are common in real-world deployments.
Practical Variants for Real Deep Networks
To make the framework practical for large neural networks, the authors introduce two efficient variants, SISA and NSISA. SISA uses second-moment information—essentially tracking how large past updates have been in each parameter direction—to form simple diagonal preconditioners, akin to ideas behind Adam and RMSProp but embedded inside the ADMM structure. NSISA goes a step further by incorporating a technique known as Newton–Schulz orthogonalization, inspired by the Muon optimizer, to better align momentum with useful directions in parameter space. Both variants retain PISA’s convergence guarantees while keeping computation lightweight enough for modern GPUs and large models.
Performance Across Vision, Language and Generative Models
The authors test SISA and NSISA across a broad set of deep learning tasks. In federated learning experiments with deliberately skewed label distributions—a tough setting where each client sees only a subset of classes—SISA dramatically outperforms popular methods like FedAvg, FedProx, FedNova and Scaffold, achieving much higher test accuracy on benchmarks such as MNIST and CIFAR-10. For standard image classification with models like ResNet and DenseNet on CIFAR-10 and ImageNet, SISA matches or exceeds strong optimizers including SGD with momentum, AdaBelief and AdamW. When fine-tuning GPT2 language models of increasing size, NSISA delivers lower validation loss in less wall-clock time than specialized optimizers such as Shampoo, SOAP, Adam-mini and Muon, with the advantage becoming more pronounced for the largest model. It also stabilizes training of generative adversarial networks, achieving lower Fréchet inception distance scores, which measure the visual quality and diversity of generated images. 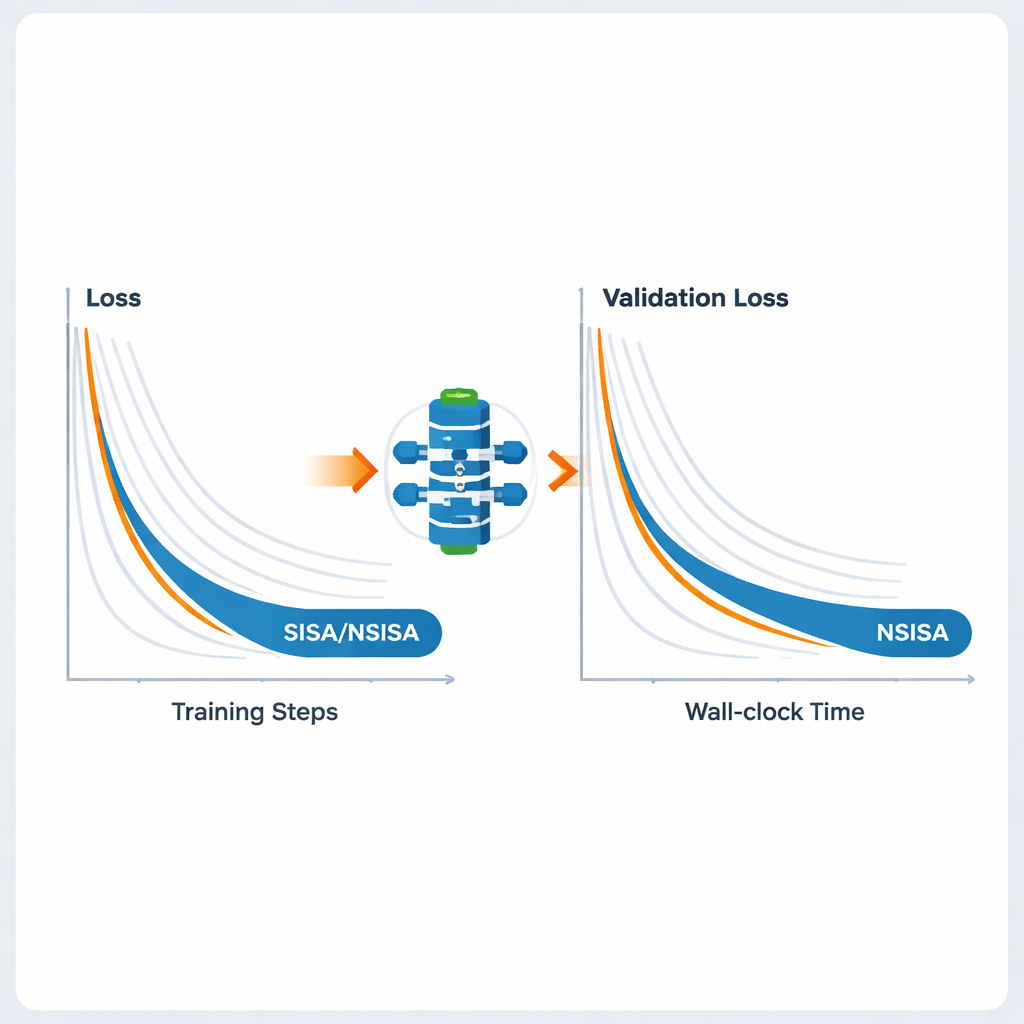
What This Means for Everyday AI
In plain terms, this work shows that it is possible to train powerful AI models more quickly and reliably, even when data are messy, imbalanced or scattered across many devices. By redesigning the underlying optimization process rather than just tweaking learning rates, PISA and its variants provide a unified tool that works well for vision, language, reinforcement learning and generative tasks. For end users, the payoff could be smarter personalization on phones, more capable language and image models and more efficient use of computing resources in large data centers—all enabled by a training algorithm that better matches the realities of modern AI systems.
Citation: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
Keywords: deep learning optimization, federated learning, stochastic ADMM, large language models, heterogeneous data