Clear Sky Science · en
When large language models are reliable for judging empathic communication
Why Machine Empathy Matters to You
More and more, people turn to chatbots and digital assistants when they are stressed, lonely or facing tough decisions. These systems can sound caring and understanding—but can they also judge whether a message is truly supportive and kind? This article explores when large language models (LLMs), the technology behind many chatbots, can reliably evaluate how empathic a written response feels, and what that means for everyday tools like wellness apps, virtual therapists and customer-service bots. 
Studying Supportive Conversations
The researchers analysed 200 real text-based conversations in which one person described a personal problem—such as work stress, family conflict, money worries or mental health struggles—and another person tried to respond supportively. These conversations came from four existing datasets, each tied to a different set of questions for judging empathy. Some focused on whether the responder showed understanding or offered emotional comfort; others asked whether they gave practical advice, encouraged the speaker to say more, or instead centred the conversation on themselves. Together, these frameworks break down “being empathic” into 21 specific behaviours that can be rated on scales, much like a customer satisfaction survey.
Experts, Crowds and Machines
To see how well LLMs can rate empathy, the team compared three kinds of judges: communications experts, online crowdworkers and modern language models. Three seasoned scholars in empathic communication independently rated every conversation on all 21 behaviours. Crowdworkers—everyday internet users—had already provided ratings for the same messages through earlier studies. Finally, three leading language models were carefully prompted with plain-language guidelines and example ratings from the experts, then asked to score each conversation on the same scales. This set-up allowed the authors to measure how closely each group agreed, not just with a “correct” answer, but with one another. 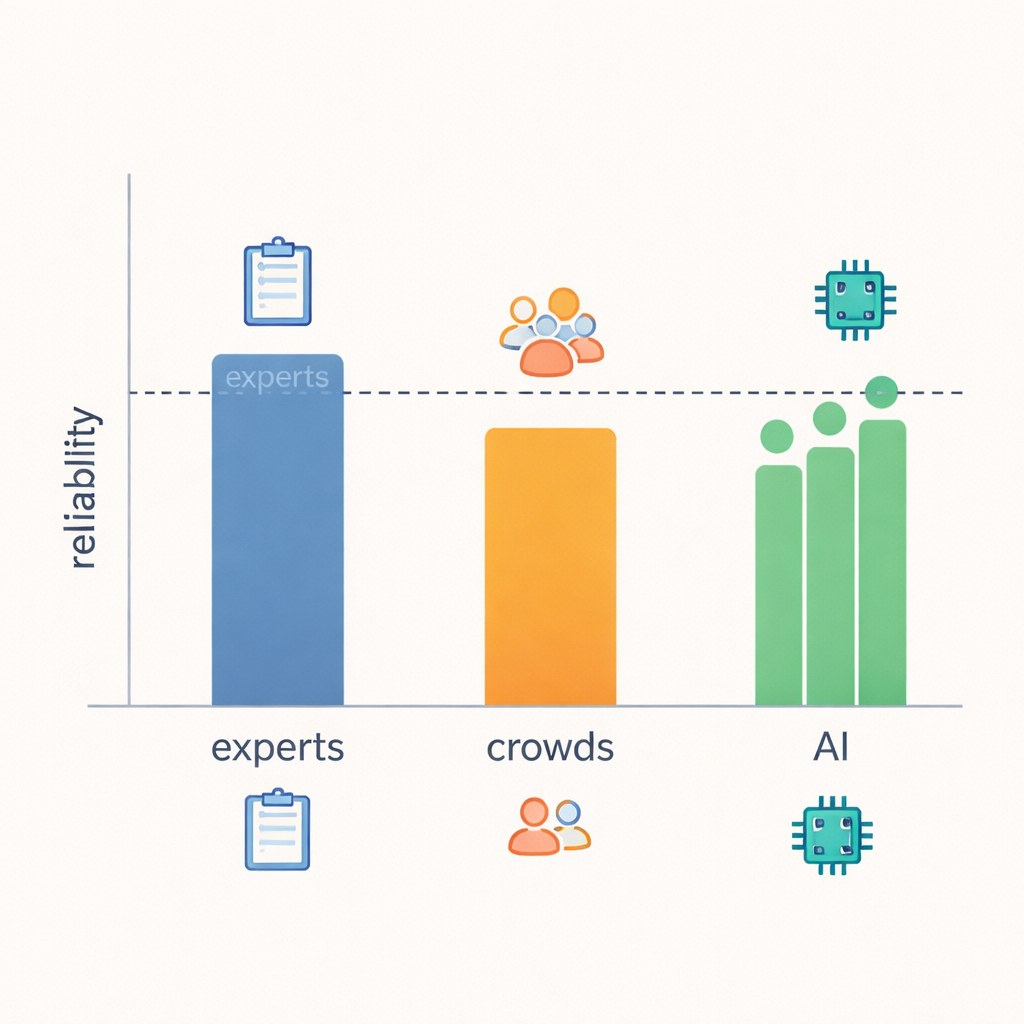
How Closely Do They Agree?
The core finding is that LLMs came surprisingly close to expert-level reliability. When the researchers measured how often ratings lined up and how big the disagreements were, the models matched or nearly matched the experts in most of the 21 behaviours, and they clearly outperformed the crowdworkers. In areas with clear, observable signals—such as whether a response gave practical advice, asked follow-up questions, or shifted attention back to the speaker—experts, LLMs and even crowds tended to agree more. But when judging fuzzier ideas, like whether a response truly “demonstrated understanding” or what the responder’s intentions were, even experts disagreed more often, and LLM reliability dropped along with theirs. This suggests that some aspects of empathy are simply harder to pin down from text alone, regardless of who is doing the judging.
Why Simple Scores Can Mislead
Many AI studies report success using familiar classification scores—treating each expert rating as unquestioned truth and measuring how often a model matches it. The authors show that this approach can paint a distorted picture when dealing with subtle human judgements. For example, a system can score well by mostly guessing the majority rating on an unbalanced scale, even if it struggles on rarer but important cases. Likewise, a method that mostly gives “almost right” scores—off by just one point—can look poor on a strict match metric, even though it behaves much like a human expert. By focusing on interrater reliability—how consistently different judges score the same thing—the study offers a more honest view of what both humans and machines can reliably assess.
What This Means for Everyday AI
For a layperson, the takeaway is both hopeful and cautionary. Well-configured LLMs can now help check whether written responses—from human helpers or other bots—meet expert standards of empathic communication, and they often do so more consistently than untrained human raters. That could make it easier to monitor and improve chatbots used in health care, education and customer service. At the same time, the study warns that not all “empathy tests” are created equal: vague or overlapping questions lead to shaky human agreement and, in turn, shaky machine judgements. Before trusting AI to grade something as delicate as emotional support, we should first ensure that experts themselves can agree on what “good” looks like—and use that benchmark to decide where machines can safely assist and where human judgement remains essential.
Citation: Kumar, A., Poungpeth, N., Yang, D. et al. When large language models are reliable for judging empathic communication. Nat Mach Intell 8, 173–185 (2026). https://doi.org/10.1038/s42256-025-01169-6
Keywords: empathic communication, large language models, AI companions, mental health support, human–AI interaction