Clear Sky Science · en
A deep learning model integrating structured data and clinical text for predicting atrial fibrillation recurrence
Why this matters for people with irregular heartbeats
Atrial fibrillation, a common heart rhythm problem, often returns even after patients undergo catheter ablation, an invasive procedure meant to restore a normal heartbeat. Many people and their doctors are left wondering: who is most likely to have the problem come back, and who can safely relax? This study shows how modern artificial intelligence can sift through both numbers and doctors’ notes in the medical record to more accurately forecast the chance that atrial fibrillation will recur, potentially guiding follow-up care and preventing repeat procedures.
A tough heart rhythm problem that often comes back
Catheter ablation is widely used to treat atrial fibrillation by burning or freezing tiny areas inside the heart that trigger or sustain abnormal rhythms. Yet 30–50% of patients experience a return of irregular heartbeats within a year, sometimes needing another procedure. Existing risk scores, based mostly on a handful of measurements such as heart chamber size and type of atrial fibrillation, give only a partial picture. They usually ignore rich details about how the procedure was done, what the heart looked like on ultrasound, and nuances of the patient’s overall condition that end up buried in text reports. As a result, physicians still struggle to identify who truly needs especially close monitoring or extra preventive treatment.
Turning routine hospital data into a smarter prediction tool
Researchers in China gathered information from 2,508 patients who underwent atrial fibrillation ablation at five hospitals between 2015 and 2024. The typical patient was 65 years old, and about one in five had a recurrence of abnormal rhythm over a median follow-up of nearly three years. For each person, the team collected structured data—such as age, blood pressure, blood test results, heart chamber size, and existing risk scores—as well as unstructured text, including 24‑hour heart monitor summaries, ultrasound reports, and detailed procedure notes written by electrophysiologists. They then built a dual-branch deep learning model: one branch processed the numerical and categorical data, while the other used large language models to transform free‑text reports into quantitative features that could be combined with the numbers.
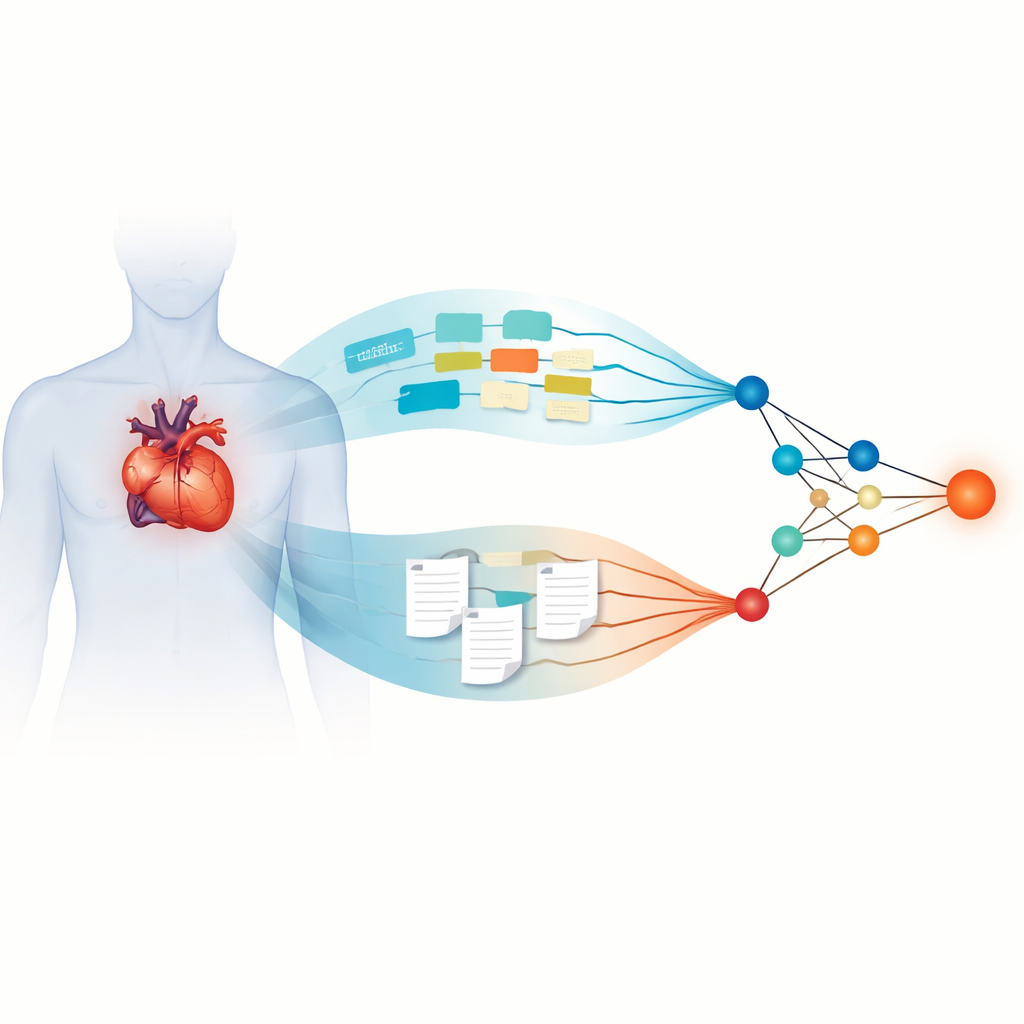
How advanced language models read doctors’ notes
The text branch of the system relied on four modern large language models, originally trained on huge collections of written material, and then adapted to medical language. These models were fine‑tuned on de‑identified hospital reports so they could better grasp specialized terms and patterns. The study compared different language models to see which produced text features that best predicted recurrence. The standout performer was MedGemma, a model specifically optimized for medical content. When its text features were fused with the structured data branch, the resulting “MedGemma‑Fusion” model showed striking accuracy, with areas under the receiver‑operating curve above 0.90 in training, validation, and independent test hospitals. This meant the model could reliably distinguish patients who would remain free of arrhythmia from those who would not.
Peeking inside the black box of AI
To understand what the model was actually using to make predictions, the researchers applied interpretability tools that estimate the influence of each input. In the structured data, familiar clinical factors like how long the patient had lived with atrial fibrillation, the size of the left atrium, and whether the rhythm was intermittent or persistent carried the most weight. From the text side, key concepts associated with ablation procedures—such as descriptions of pulmonary veins and electrical potentials—rose to the top, reflecting steps that are central to successful treatment. Terms related to heart motion in ultrasound reports also mattered, consistent with the idea that changes in how the atria move signal long‑standing damage. In contrast, summaries from 24‑hour heart monitors contributed relatively little, likely because many patients with intermittent atrial fibrillation show normal rhythms during short monitoring windows.
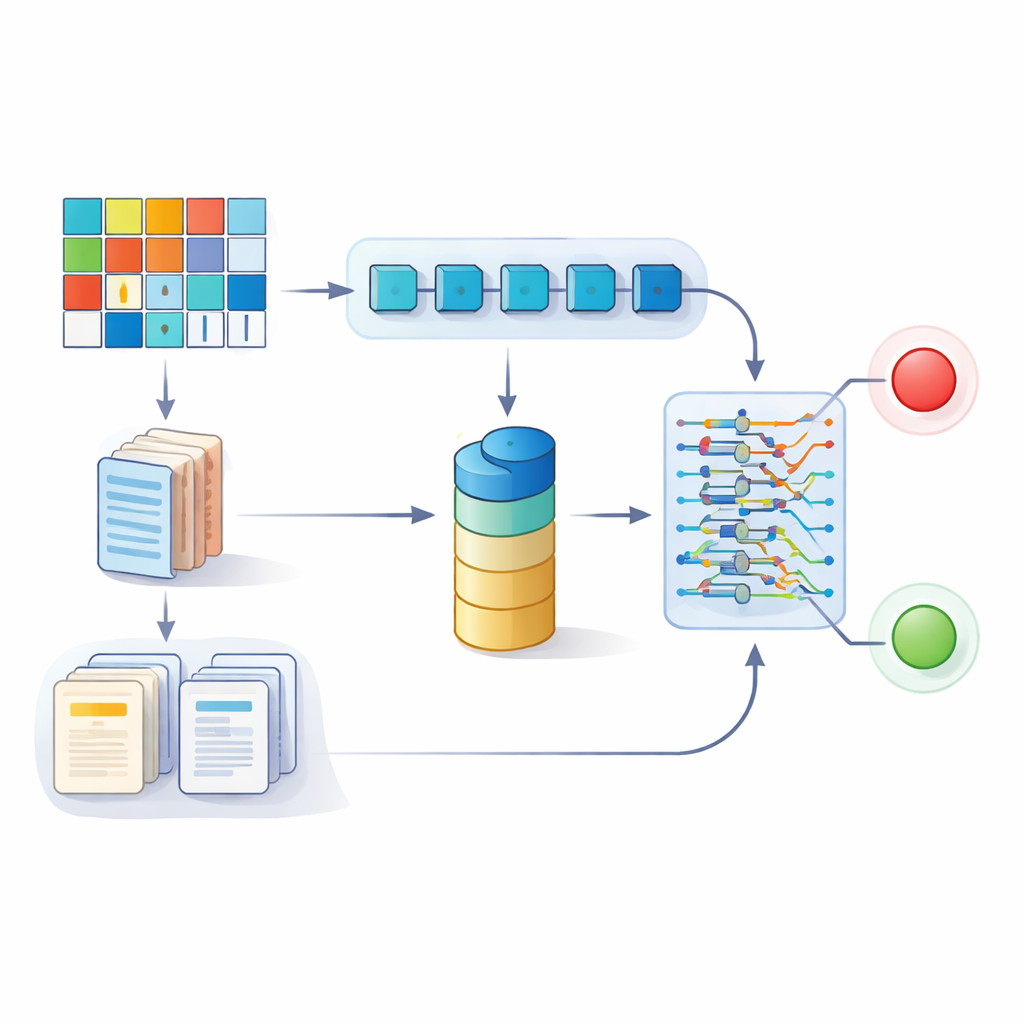
From research model to bedside decisions
Beyond raw accuracy, the team tested how well their tool separated people into high‑ and low‑risk groups using survival analyses. Patients flagged as high risk by MedGemma‑Fusion had clearly higher rates of recurrence over time. Decision curve analysis suggested that, across many reasonable thresholds, using the model to guide care would provide more net benefit than relying on traditional scores or single measurements alone. Still, the authors stress important caveats: the study is retrospective, sample sizes—while large for a single project—are modest for deep learning, and reporting styles differed across hospitals. Future versions of large language models and wider testing in other health systems will be needed before such tools are routine. Nonetheless, this work illustrates how combining everyday numbers in the chart with the nuance hidden in narrative reports can sharpen predictions and may eventually help tailor follow‑up and treatment intensity for people living with atrial fibrillation.
Citation: Jia, S., Yin, Y., Guan, Y. et al. A deep learning model integrating structured data and clinical text for predicting atrial fibrillation recurrence. npj Digit. Med. 9, 253 (2026). https://doi.org/10.1038/s41746-026-02436-5
Keywords: atrial fibrillation, catheter ablation, deep learning, clinical text mining, risk prediction