Clear Sky Science · en
Large-scale self-supervised video foundation model for intelligent surgery
Smarter Help in the Operating Room
Modern surgeons increasingly rely on cameras and computers to guide their work, but today’s artificial intelligence still struggles to fully understand what is happening during an operation. This paper presents a new way to train AI on thousands of surgery videos so it can better follow the steps of a procedure, recognize instruments and tissues, and assess how safely and skillfully the operation is progressing. In the long run, this kind of technology could support surgeons in real time, improve training, and help make surgery safer for patients.
Why Teaching Machines About Surgery Is Hard
Teaching computers to understand surgery is not as simple as feeding them a few labeled pictures. Every procedure involves moving cameras, changing viewpoints, smoke, blood, and hands and tools that constantly block one another. On top of this, there are thousands of different kinds of operations, many of which are rare. Carefully labeling video data frame by frame requires scarce expert time and quickly becomes too expensive. Earlier AI systems tried to ease this burden with tricks that learn from unlabeled images, but they mostly looked at still frames and only later tried to add a sense of time. As a result, they often missed the unfolding story of an operation: what came before, what is happening now, and what is likely to happen next.
Learning Directly From Surgical Movies
The authors argue that an AI meant to assist in surgery should be trained on videos rather than on isolated images. To do this, they assembled one of the largest collections of endoscopic surgery videos to date: 3,650 recordings with 3.55 million frames, drawn from public research datasets and a broad sweep of online surgical footage. These videos span more than 20 kinds of procedures and over 10 anatomical regions, from gallbladder removal to liver surgery and gynecologic operations. This diversity lets the AI see many ways a procedure can look in real life, including different hospitals, tools, and camera styles.
A New Video-Focused Learning Blueprint
Building on this data treasure, the team designed SurgVISTA, a “foundation model” tuned specifically for surgery videos. Instead of trying to label each frame, SurgVISTA learns by filling in what is missing. During training, parts of each video clip are hidden, and the model must reconstruct the missing regions. This forces it to pay attention to how tissues, instruments, and motions change over time. At the same time, a second branch of the system is taught to match the detailed visual cues captured by a strong image-based expert model that already knows a lot about surgical scenes. This combination helps SurgVISTA grasp both the fine details within each frame and the broader flow of the whole operation, all within a single, unified network.
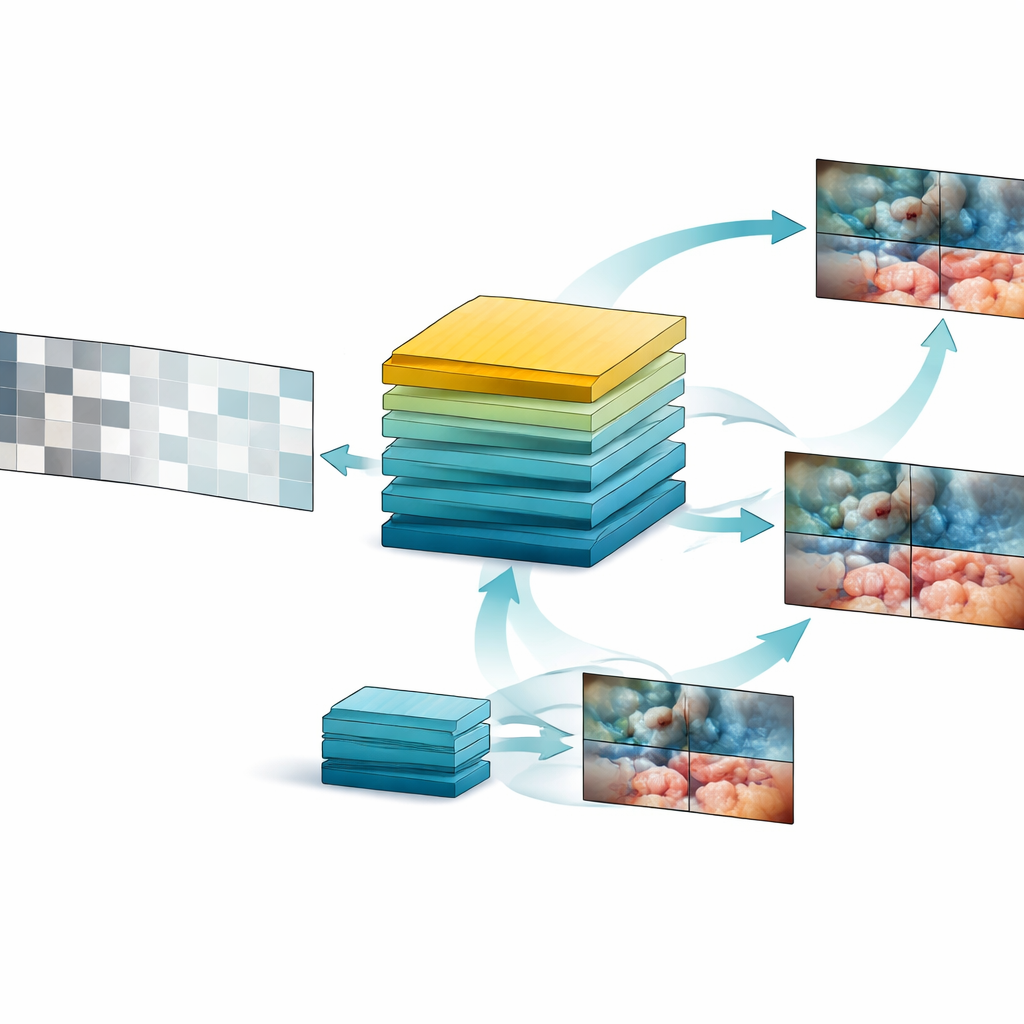
Putting the Model to the Test
To see whether this approach truly pays off, the authors tested SurgVISTA on 13 different datasets involving six types of surgery and four practical tasks. These tasks included recognizing which phase of an operation is underway, identifying specific surgical actions, capturing the three-way relationship between instrument, action, and target tissue, and judging how safely key steps have been performed. Across the board, SurgVISTA beat leading models that had been trained on everyday videos, as well as the best existing surgery-focused systems that were based mainly on still images. It performed strongly even on procedures it had never seen during training, showing that the patterns it learned were not tied to a single organ, tool set, or hospital.
Why More and Richer Video Data Matters
The study also probed how performance changed as more training data were added. As the authors gradually expanded the size and variety of the video pool, SurgVISTA’s results improved almost everywhere, including on procedures that did not appear in the training set at all. Interestingly, the model benefited not only from more examples of the same operation, but also from different kinds of surgeries: exposure to varied surgical “stories” helped it spot general visual and motion patterns that transfer across specialties. Additional experiments showed that the extra guidance from the image-based expert further sharpened the model’s ability to preserve fine anatomical detail, which is crucial for telling, for example, a vital structure from surrounding tissue.
What This Means for Future Surgery
In plain terms, this work shows that an AI trained on large amounts of real surgery video, with both space and time in mind, can build a much deeper understanding of what happens in the operating room. SurgVISTA is not yet a tool that makes decisions on its own, but it provides a powerful backbone that other applications can plug into—whether to track surgical progress, flag risky moments, support training, or compare techniques across hospitals. The authors note that broader data and clinical testing are still needed, but their results suggest that video-based foundation models could become a key ingredient in future intelligent surgical systems aimed at making procedures safer, more consistent, and better tailored to each patient.
Citation: Yang, S., Zhou, F., Mayer, L. et al. Large-scale self-supervised video foundation model for intelligent surgery. npj Digit. Med. 9, 220 (2026). https://doi.org/10.1038/s41746-026-02403-0
Keywords: surgical video AI, self-supervised learning, operative workflow, computer-assisted surgery, spatiotemporal modeling