Clear Sky Science · en
Machine learning models for drug-drug interaction prediction from computational discovery to clinical application
Why combining medicines can be risky
Modern medicine often relies on taking several drugs at once—for cancer, heart disease, infections, or simply managing the many conditions that come with age. But when medicines meet inside the body, they can change each other’s effects, sometimes making treatment less effective or even dangerous. This review looks at how artificial intelligence, especially modern machine-learning methods, is being used to predict these drug–drug interactions in advance, so doctors can choose safer combinations and tailor treatments to individual patients.
From trial-and-error to data-driven safety
Traditionally, worrisome drug combinations have been discovered the hard way—during late-stage clinical trials or after a medicine is already on the market and patients are harmed. Laboratory tests on cells, animals, and volunteers remain the gold standard, but they are slow, expensive, and impossible to apply to the enormous number of potential drug pairs. The authors argue that computational prediction offers a way out of this bottleneck. By learning from huge digital collections of drug information—such as chemical structures, targets in the body, known side effects, and real-world reports of adverse reactions—machine-learning systems can flag risky pairs long before they reach large numbers of patients.
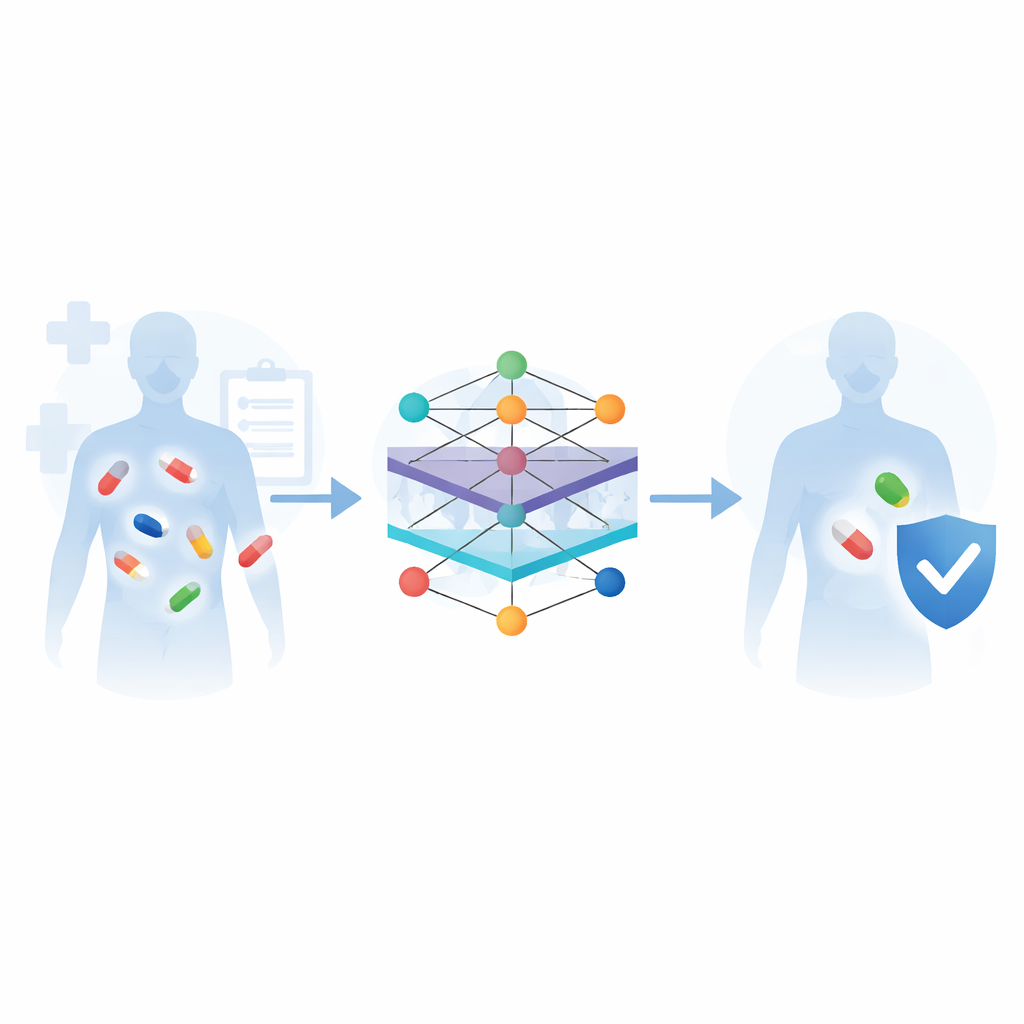
How machines learn from many kinds of drug data
The review explains a common workflow for these prediction systems. First, information is gathered from major biomedical databases: chemical libraries that describe what each molecule looks like, pathway maps that show how drugs are processed in the body, and curated lists of known interactions and side effects. Next, algorithms convert this raw information into numeric patterns that computers can understand—for example, by measuring how similar two drugs are, or by representing each drug as a node in a network linked to its targets, pathways, and past reactions. Different machine-learning models are then trained to recognize which pairs of drugs tend to cause problems, and their performance is checked against benchmark datasets using standard accuracy measures.
Different algorithm families tackle the problem in their own way
Because drug interactions are complex, no single model type is best for all situations. Some approaches rely on traditional classifiers that work with hand-crafted features, while others learn directly from the structure of molecules or the web of connections between drugs and biological entities. Graph-based and deep-learning methods have been especially successful: they treat drugs and their relationships as a network, allowing the algorithm to "reason" over chains of connections that might be invisible to simpler models. Other strategies share information across related tasks, such as predicting both whether two drugs interact and what kind of effect they produce, which helps when data are scarce. The paper also highlights new directions such as large language models that read scientific texts and clinical notes, and generative models that explore possible interaction patterns in very large, sparse datasets.
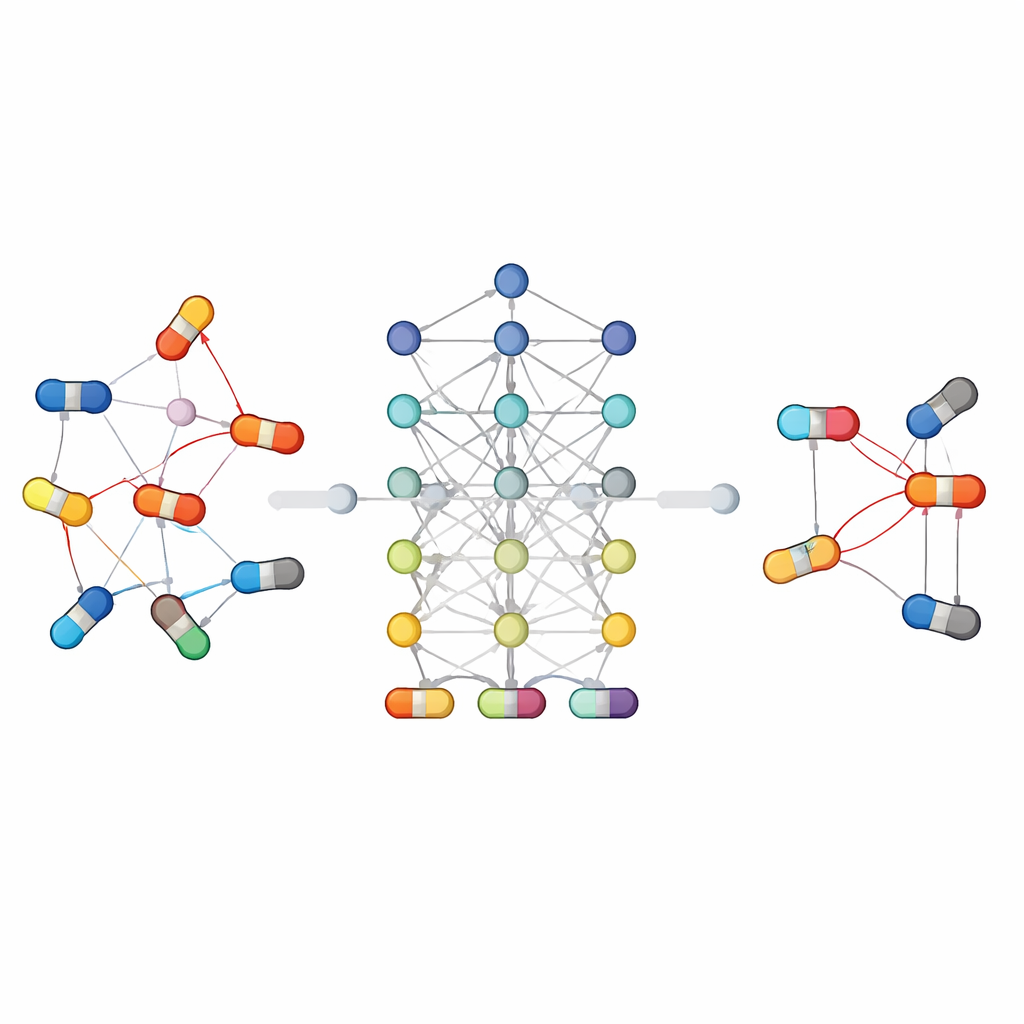
Linking computer predictions to real patients
Beyond methods, the article emphasizes how these tools can support real-world care. The authors discuss how models trained on curated databases and clinical records can alert clinicians to dangerous combinations at the bedside, help design safer multi-drug regimens in cancer, cardiology, and infectious disease, and prioritize which predicted interactions deserve laboratory testing. They also survey classic clinical examples—such as antibiotics altering the levels of cholesterol-lowering drugs, pain medicines blocking each other’s effects, or fruit juices unexpectedly boosting drug concentrations—to show the many pathways through which interactions arise. Machine-learning systems that capture these patterns can thus act as early warning devices, especially in older patients who take many medications.
Challenges on the road to trustworthy AI for medicines
Despite impressive accuracy on test datasets, the authors stress that current models still face important hurdles before they can be widely trusted in clinics. Many are "black boxes" that offer little insight into why a specific pair is judged risky, making it hard for doctors to evaluate or explain the recommendation. Models can stumble when data are noisy or unbalanced—for instance, when harmful interactions are rare compared with safe pairs. Integrating information across chemistry, genetics, electronic health records, and published literature is technically difficult, and regulatory frameworks require strong evidence before such tools can influence prescribing. Future work, the authors argue, must focus on more interpretable models, better handling of biased and incomplete data, and systems that can continually learn from new clinical experience while respecting privacy and safety rules.
What this means for everyday treatment
In plain terms, this review shows that artificial intelligence is becoming a powerful ally in keeping drug combinations safe. By sifting through mountains of digital data far beyond what any human expert could manage, machine-learning models can spotlight dangerous pairs, suggest safer alternatives, and support more personalized prescriptions. These tools will not replace clinical judgment or careful lab testing, but they can help ensure that the growing complexity of modern therapy does not come at the cost of patient safety.
Citation: Lu, Y., Chen, J., Fan, N. et al. Machine learning models for drug-drug interaction prediction from computational discovery to clinical application. npj Digit. Med. 9, 198 (2026). https://doi.org/10.1038/s41746-026-02400-3
Keywords: drug–drug interactions, machine learning in medicine, graph neural networks, clinical pharmacology, artificial intelligence safety