Clear Sky Science · en
Evaluation of large language models for diagnostic impression generation from brain MRI report findings: a multicenter benchmark and reader study
Why smarter MRI reports matter for patients
When you get a brain scan, a radiologist must turn thousands of shades of gray into a clear statement of what is wrong—or that everything looks normal. This final “impression” guides crucial decisions about stroke care, brain tumors, infections, and more. But reading brain MRI scans is complex and time‑consuming, and overloaded doctors can make mistakes, especially in busy hospitals. This study explores whether advanced artificial intelligence language models can reliably help radiologists turn written MRI findings into accurate, fast, and consistent diagnostic impressions.
Turning raw scan descriptions into clear answers
Brain MRIs produce a series of images that radiologists describe in a written “findings” section, noting things like where a lesion sits, how bright it looks, and whether there is swelling. The real challenge is then to combine all those details into a diagnostic impression, such as “acute infarct” or “brain abscess.” The researchers collected 4293 brain MRI reports from three hospitals in China, spanning 16 diagnostic categories that cover more than 95% of everyday brain conditions. They then tested 10 different large language models—advanced text‑based AI systems—to see how well each could turn the written findings into the correct diagnoses.
Big, well‑fed AI models came out on top
The team compared models ranging from about 8 billion to 671 billion internal parameters, roughly analogous to moving from a medical student’s knowledge to that of an expert team. The largest model, called DeepSeek‑R1, consistently delivered the best performance when it was given both structured versions of the findings and key clinical information such as patient age, symptoms, or history of trauma. Under these conditions, DeepSeek‑R1 correctly identified the presence or absence of specific brain conditions with high sensitivity and specificity, and achieved patient‑level accuracy above 87%. Smaller models, especially those under 10 billion parameters, struggled badly, often getting only about 30% of cases right—far below what would be acceptable in real clinical work.
Why structure and context make AI smarter
The researchers did not just feed the models free‑form text. They also used another AI system to restructure the reports into clear, standardized elements: where each lesion was located, how many there were, and what they looked like on different MRI sequences. Adding this structure, and combining it with short clinical notes, made a striking difference. For DeepSeek‑R1, shifting from raw free‑text findings to structured findings plus clinical context boosted sensitivity, overall accuracy, and summary performance measures. In simple terms, the AI did much better when it was given cleaner, more organized information and a bit of patient background—mirroring how human radiologists work best when reports are tidy and the clinical question is clear.
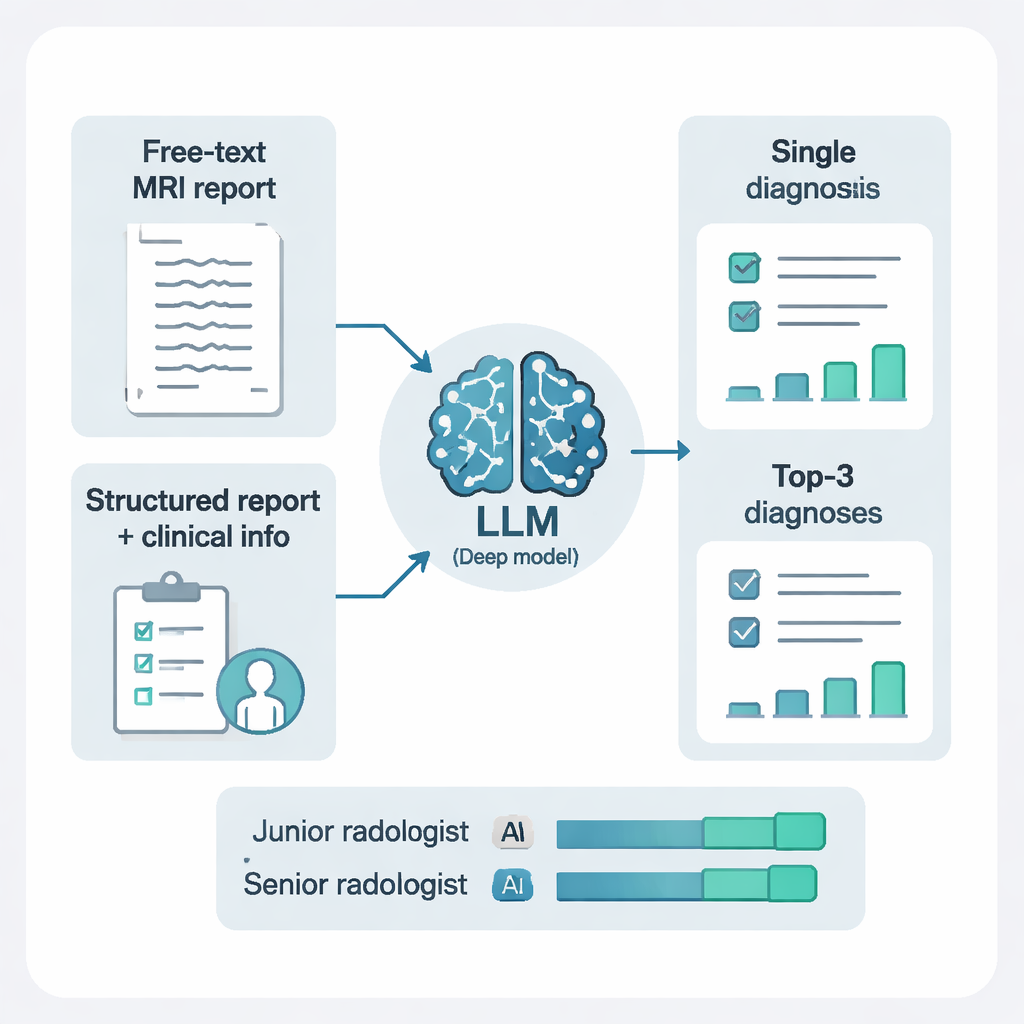
From a single guess to a ranked short list
In real life, radiologists often offer more than one possible diagnosis for tricky cases. The study tested two prompting styles: asking the AI for just one diagnosis, or asking for its top three possibilities, each with a brief explanation. Allowing three ranked diagnoses dramatically improved performance. With this “differential diagnosis” approach, the correct answer appeared somewhere in the top three suggestions for more than 97% of patients. This was especially helpful in complex cases like tumors, hemorrhages, or inflammatory diseases, where a single forced guess can be misleading but a short, reasoned list can effectively guide further testing and treatment.
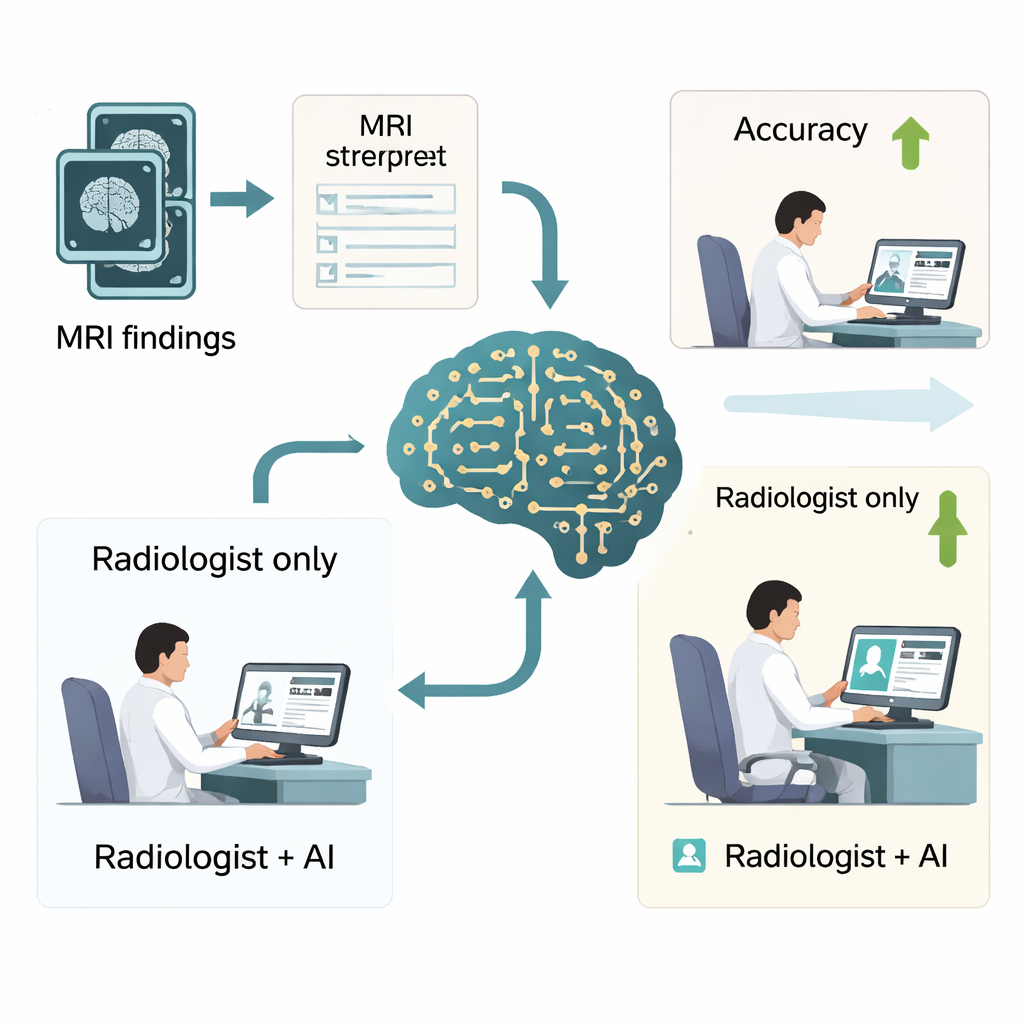
Real‑world impact on busy radiologists
To see whether these gains matter in practice, the authors ran a reader study with six radiologists—three junior and three senior—who interpreted 500 brain MRI reports with and without DeepSeek‑R1’s help. With AI assistance, overall diagnostic accuracy jumped from about three‑quarters of cases to more than 90%, and a key quality measure of precision and recall also improved substantially. Reading time dropped as well, from about a minute per case to under a minute, which could translate into dozens of hours saved per radiologist each year. The biggest benefits were seen in junior radiologists, whose performance moved closer to that of seasoned experts, though the study also highlighted that doctors must remain cautious and not blindly trust AI, particularly for very subtle conditions such as certain types of brain hemorrhage.
What this means for future brain scan reports
For patients, the main takeaway is that powerful language‑based AI systems can already help radiologists turn complex MRI descriptions into clearer, more accurate diagnostic impressions, especially when they are fed well‑structured information and key clinical details. These tools are not replacements for human expertise but can act as a second set of careful eyes, offering reasoned suggestions and saving time. If validated more broadly and integrated safely into hospital systems, such AI support could help make brain scan reports faster, more reliable, and more consistent—ultimately improving care for people with strokes, tumors, infections, and many other brain conditions.
Citation: Wang, ML., Zhang, RP., Wu, WJ. et al. Evaluation of large language models for diagnostic impression generation from brain MRI report findings: a multicenter benchmark and reader study. npj Digit. Med. 9, 187 (2026). https://doi.org/10.1038/s41746-026-02380-4
Keywords: brain MRI diagnosis, radiology artificial intelligence, large language models, clinical decision support, DeepSeek-R1