Clear Sky Science · en
Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review
Why Sharing Medical Insights Without Sharing Data Matters
Modern medicine increasingly relies on artificial intelligence to spot disease earlier, choose the right treatment, and predict who is at highest risk. Yet the best AI tools need huge amounts of patient data, and hospitals cannot simply pool their records because of strict privacy laws and ethical concerns. This article reviews more than a decade of research on “decentralized” learning—ways for hospitals to train AI together without ever sharing raw patient data—and asks a practical question: how well do these privacy‑preserving methods actually perform compared with traditional approaches?
New Ways to Learn From Patients While Protecting Privacy
In traditional centralized learning, hospitals copy all their data into one big database and train a single model there. In local learning, each institution builds its own model on its own data, with no collaboration. Decentralized learning offers a middle path. In federated learning, for example, each hospital trains a model locally, then only the model’s settings (like the “knobs” in a neural network) are sent to be combined into a shared model; patient records never leave the site. Swarm learning removes the central coordinator and lets institutions exchange model updates directly. Other decentralized approaches combine predictions from multiple local models, or split the model across sites. These methods have been tested on problems ranging from cancer detection and COVID‑19 diagnosis to heart disease, diabetes, brain disorders, and psychiatric conditions.
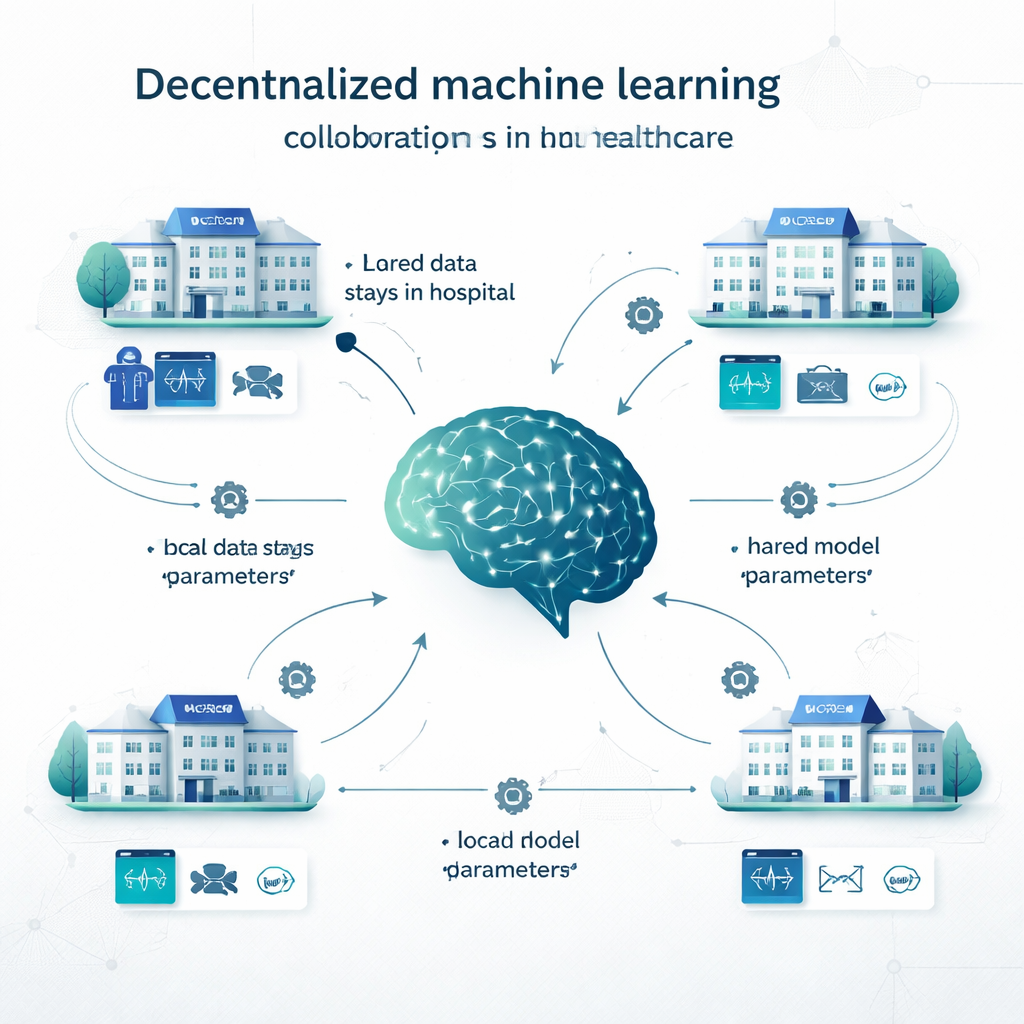
What the Researchers Examined
The authors systematically searched 11 major databases and screened 165,010 studies published between 2012 and March 2024. After removing duplicates and studies that did not involve real clinical decisions, 160 articles remained. Together, these papers reported 710 decentralized models and 8,149 direct performance comparisons against centralized or local models. Most studies focused on diagnosis, but there were also many on image segmentation (for example, outlining tumors), predicting future outcomes such as survival or complications, and combined tasks. The data types covered almost every major source used in medicine: electronic health records, CT and MRI scans, X‑rays, digital pathology slides, heart and brain signals, and even genetic data.
How Privacy‑Preserving Models Stack Up Against Centralized AI
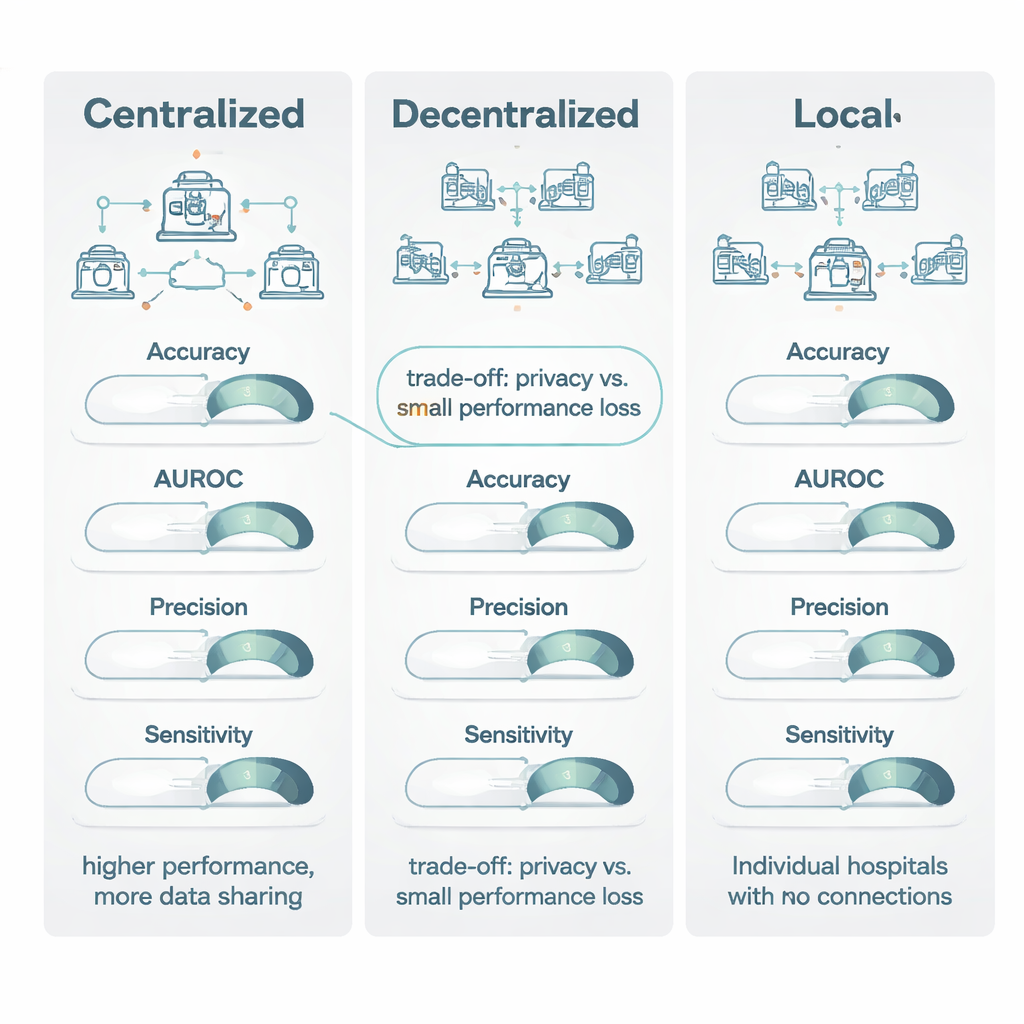
When decentralized models were compared with centralized ones trained on pooled data, centralized learning usually came out slightly ahead. It did especially well on “threshold‑based” measures like accuracy and a common imaging score called the Dice coefficient, winning around three‑quarters of the time and by enough to be considered a moderate to large advantage. However, for ranking‑style measures—such as the area under the ROC curve (AUROC), which captures how well a model orders patients from lower to higher risk—decentralized and centralized models were much closer, with only a small edge for centralized training. Importantly, when both models reached what the authors call “clinically viable” performance (a score of at least 0.80), the centralized model’s typical gain was modest: often less than 1–1.5 percentage points. In many situations this amounted to “excellent versus acceptable,” not “usable versus useless.”
Why Decentralized Learning Beats Going It Alone
The strongest signal in the review emerged when comparing decentralized models with purely local ones. Across all major metrics—accuracy, AUROC, F1 score, sensitivity, specificity, and especially precision—decentralized methods almost always did better, often by a wide margin. In head‑to‑head tests, decentralized learning outperformed local models in more than 80% of comparisons for key measures such as accuracy, precision, and AUROC. In many cases, local models failed to reach the 0.80 threshold for clinical usefulness, while the corresponding decentralized model cleared it comfortably, improving sensitivity by as much as 27 percentage points. The authors attribute this to the broader experience that multi‑site models gain: by “seeing” patterns from many hospitals, they become less fooled by hospital‑specific quirks in scanners or record‑keeping and more attuned to disease features that truly generalize.
Balancing Performance, Privacy, and Practical Use
The review concludes that centralized learning remains the gold standard when privacy rules and logistics allow data to be combined and when every fraction of a percentage point in performance matters, such as with very rare diseases. However, decentralized learning offers a powerful and clinically acceptable alternative for situations where data sharing is restricted by laws like the GDPR and the EU AI Act, or by institutional policies. Compared with keeping models entirely local, decentralized approaches provide large gains in both accuracy and reliability while maintaining data within hospital walls. The authors argue that future work should report privacy techniques and computational costs more clearly, so that health systems can make informed choices about when slight performance trade‑offs are worth the substantial benefits in privacy and collaboration.
Citation: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
Keywords: federated learning, healthcare AI, medical data privacy, decentralized machine learning, clinical prediction models