Clear Sky Science · en
Uncertainty modeling in multimodal speech analysis across the psychosis spectrum
Listening for Hidden Clues in Everyday Speech
Psychosis is often thought of as sudden and dramatic—voices, visions, and a break from reality. But long before a crisis, subtle changes can surface in how people talk: their tone of voice, their choice of words, even the rhythm of their sentences. This study explores whether computers can pick up those faint signals in speech and, crucially, say how confident they are in what they hear. By doing so, the work points toward future tools that might help clinicians track mental health more objectively and personalize care across the full range from mild risk to full-blown illness.
From Casual Talk to Clinical Interviews
The researchers recorded speech from 114 German-speaking volunteers spanning the psychosis spectrum: people with early psychotic disorders and people without diagnoses but with low or high levels of psychosis-like traits (known as schizotypy). Each person completed four kinds of speech tasks, from structured clinical interviews to more free-flowing autobiographical stories, picture-based storytelling, and everyday conversation. These different settings matter because a tightly guided interview can bring out certain symptoms, like emotional flatness, while open narratives may reveal wandering thoughts or unusual perceptions. By sampling across contexts, the team could see how reliably speech signaled symptoms in real-world–like situations.
Hearing Both How We Talk and What We Say
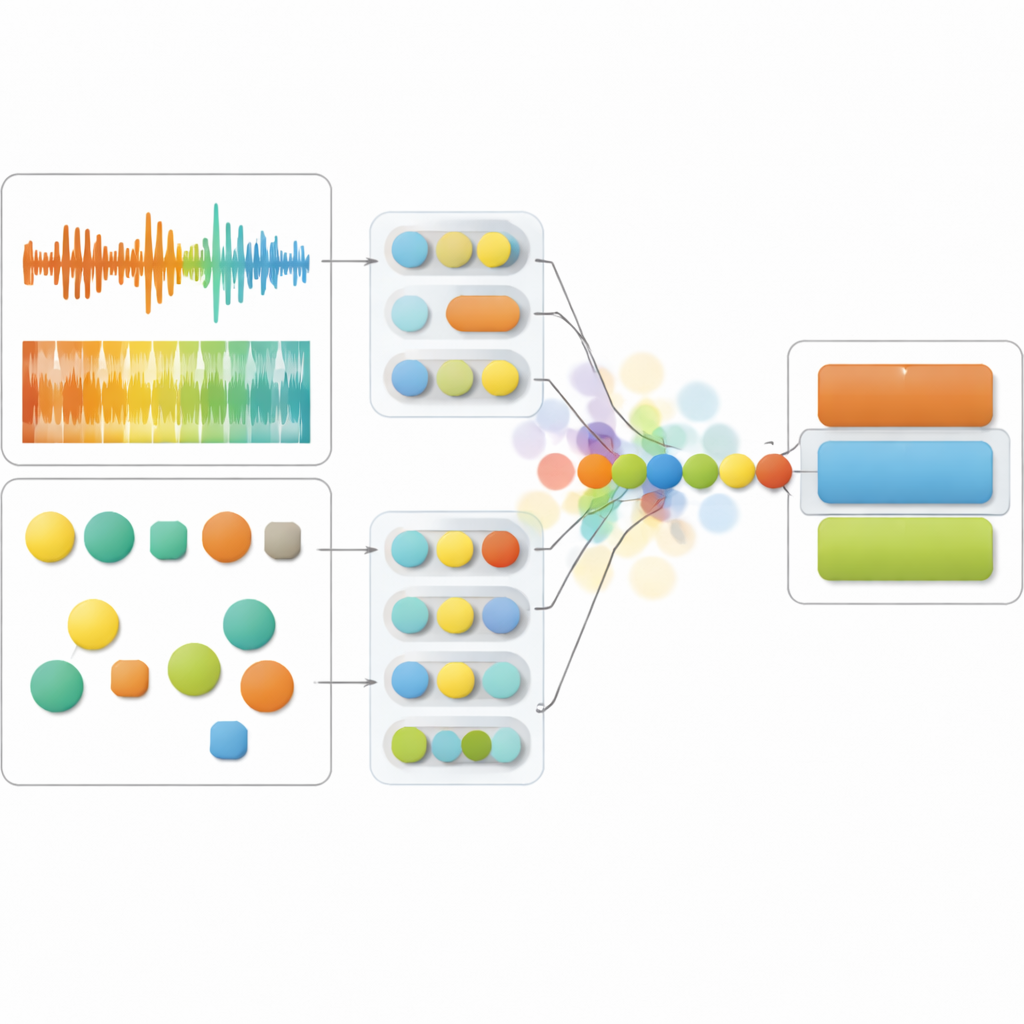
The study’s system listens to two sides of speech at once. On the sound side, it tracks features such as pitch changes, loudness, and the fine structure of the voice, which together capture expressiveness, tension, and fluency. On the language side, it analyzes the words themselves—how emotional they are, whether they focus on perceptions or social connections, and how coherent they seem. Advanced neural networks, originally trained on vast audio and text collections, turn these raw signals into compact numerical fingerprints. The core model then fuses these fingerprints over time so that it can judge, moment by moment, which channel—sound or language—provides the more trustworthy clue about a person’s mental state.
Teaching the Model to Admit When It Is Unsure
What sets this work apart is that the model does not just output a prediction; it also estimates its own uncertainty. Instead of treating the audio and text streams as fixed, it represents them as probability clouds that can expand when the data are noisy or unusual. If the voice recording is distorted or the person is mumbling, the system downplays the sound and leans more on the words. If the transcription is unreliable or the speech is extremely fragmented, it does the reverse. This uncertainty-aware fusion, called Temporal Context Fusion, achieved strong performance: it distinguished low schizotypy, high schizotypy, and early psychosis groups with an F1-score of 83% and showed well-calibrated confidence, meaning its stated certainty closely matched how often it was actually correct.
Speech Patterns that Mirror Different Symptom Types
By probing the model’s inner workings, the researchers identified which aspects of speech most consistently tracked different symptom dimensions. People with more intense positive symptoms—such as unusual experiences or delusional ideas—tended to show higher and more variable pitch, rapid shifts in the spectrum of their voice, and greater loudness swings, especially in open-ended storytelling. Their language also contained many perception words (linked to seeing, hearing, or sensing) and emotionally charged terms. In contrast, people with stronger negative symptoms—such as social withdrawal and emotional blunting—spoke in a more monotonous way, with restricted pitch and less flexible articulation, and used fewer positive emotion and social words. Disorganized traits, both in patients and in high-schizotypy volunteers, showed up as unstable loudness, hesitations, and fragmented language filled with risk and cognitive-process words, hinting at mental effort without clear structure.
Why This Matters for Future Mental Health Care
Taken together, the findings show that speech carries measurable traces of psychosis-related traits even in people who are not clinically ill, and that these traces shift depending on the speaking situation. The uncertainty-aware model was able to harness both sound and language to track positive, negative, and disorganized features along a continuum, while openly signaling when its evidence was shaky. For a layperson, the key idea is that careful listening—amplified by AI that knows its own limits—could eventually help clinicians monitor mental health more objectively, reduce guesswork, and spot meaningful changes earlier. Rather than replacing human judgment, such tools could serve as a second set of ears, highlighting patterns in everyday speech that deserve closer attention.
Citation: Rohanian, M., Hüppi, R., Nooralahzadeh, F. et al. Uncertainty modeling in multimodal speech analysis across the psychosis spectrum. npj Digit. Med. 9, 218 (2026). https://doi.org/10.1038/s41746-025-02309-3
Keywords: psychosis, speech analysis, machine learning, mental health assessment, multimodal AI