Clear Sky Science · en
IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation
Why Sharing Can Be Safe and Fair
Modern artificial intelligence feeds on data, yet most of our data sits on personal phones, hospital servers, or company clouds that cannot simply be copied and shared. Federated learning offers a way for many devices to train a shared model without exposing their raw data, but today’s systems still struggle with privacy leaks, central points of failure, and unfair rewards for people who contribute the most. This paper introduces a new framework, IMFLKD, that combines three powerful ideas—blockchain, knowledge distillation, and reputation scoring—to make this kind of collective learning more private, more robust, and more fair over the long term.
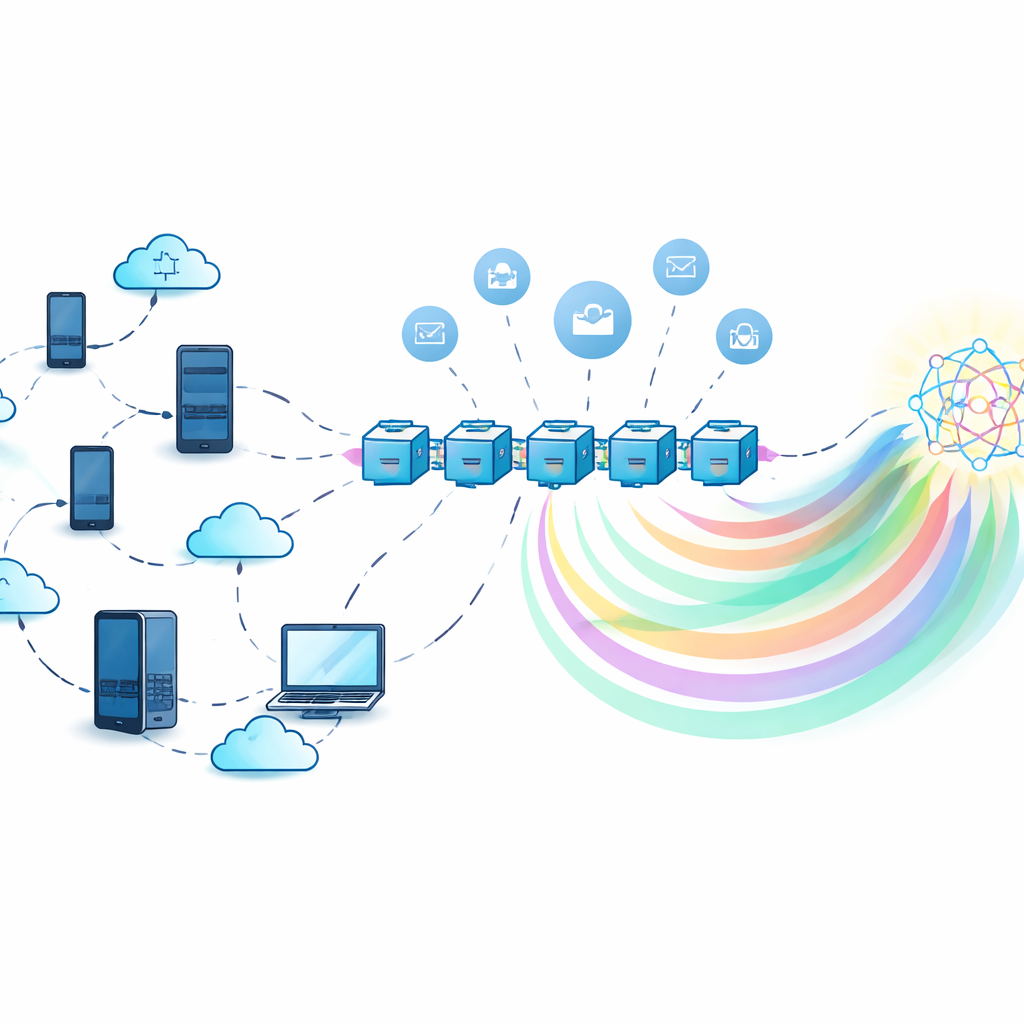
Training Together Without Sharing Secrets
In classic federated learning, a central server collects model updates from many participants and combines them. This saves raw data from traveling, but the server itself becomes a tempting target: if it fails, the whole system stalls, and if it is untrustworthy, it can misuse or leak information hidden in model updates. The authors instead use a decentralized blockchain ledger to coordinate training. Each participant trains a local model on its own data and then interacts with smart contracts on the blockchain that record contributions, aggregate information, and distribute rewards, all without relying on a single central authority.
Sharing Knowledge, Not Heavy Models
To reduce communication costs and protect privacy further, the framework relies on knowledge distillation. Rather than shipping full model parameters, each participant sends only “soft labels” – the model’s predicted probabilities for a set of shared inputs – which are much lighter and reveal less about any single person’s data. Because a real shared dataset may not exist, the system uses a generative model called a conditional variational autoencoder to create a synthetic “pseudo-public” dataset that roughly matches the overall label distribution without exposing any original records. Participants train on their own data, make predictions on this synthetic dataset, and then refine their models using an aggregated signal derived from everyone’s combined knowledge.
Measuring Who Really Helps
A central challenge in any collaborative system is deciding who deserves credit. IMFLKD tackles this with a two-stage contribution evaluation method based on label aggregation. First, a lightweight Bayesian algorithm examines the predictions from all participants and infers both the most likely true label for each sample and a quality score for each model, updating these scores as more tasks arrive. This approach works online, without storing past data, and handles noisy or malicious contributors by down-weighting models that often disagree with the emerging consensus. Experiments show that this label aggregation improves accuracy by about 10 percent compared with simple majority voting, while remaining fast enough for large-scale, resource-limited environments.
Turning Quality Into Rewards and Reputation
Once contribution quality is known, IMFLKD uses an incentive scheme called a weighted peer truth serum to turn it into rewards. Participants are compared against a quality-weighted peer consensus: those whose predictions align with high-quality peers earn more, while those who deviate or frequently disagree are penalized. This makes honest reporting the most profitable long-term strategy, even in the face of collusion. On top of this, the system builds a multi-dimensional reputation score for each participant, combining data quality, activity level, and behavioral stability, and adjusting older behavior with a time-decay factor. Reputation then feeds back into later rounds by influencing how much weight a participant’s predictions carry and whether they are selected for future tasks.
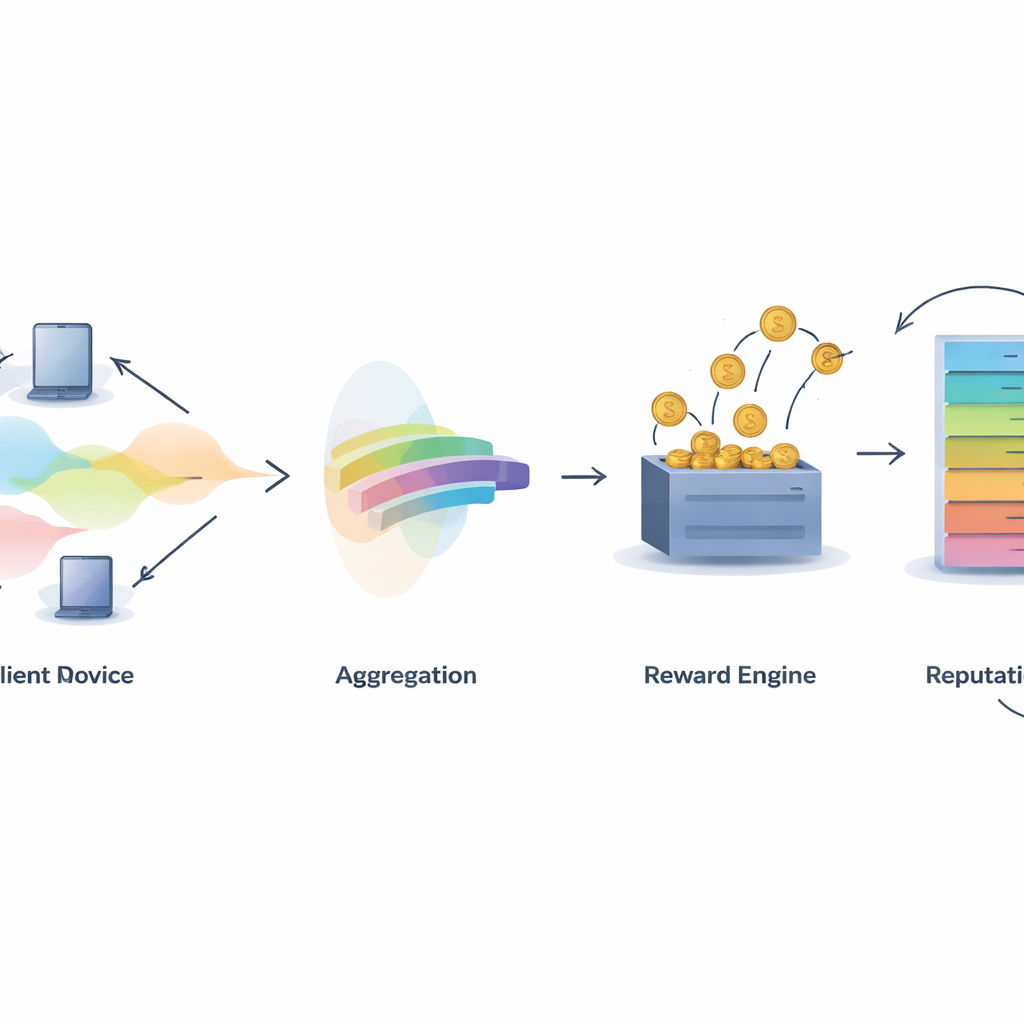
Building Trust in Collective Intelligence
Overall, the IMFLKD framework shows that it is possible to coordinate learning across many independent devices in a way that is efficient, privacy-aware, and resistant to freeloaders and attackers. By blending synthetic data generation, rigorous contribution scoring, game-theoretic rewards, and dynamic reputation tracking on a blockchain, the system encourages participants to behave honestly and consistently over many training rounds. For a layperson, the takeaway is that we can tap into the collective power of distributed data—such as medical records, sensor readings, or personal devices—without handing everything to a single company or server, while still ensuring that those who provide the most useful information are the ones who benefit the most.
Citation: Ying, X., Yan, K., Gao, X. et al. IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation. Sci Rep 16, 10567 (2026). https://doi.org/10.1038/s41598-026-46234-1
Keywords: federated learning, blockchain, knowledge distillation, incentive mechanisms, reputation systems