Clear Sky Science · en
Hybrid evolutionary-gradient training improves long-term time series forecasting
Why better long‑range predictions matter
From electricity demand and highway traffic to exchange rates and local weather, our lives are shaped by systems that evolve over time. Accurately forecasting these patterns days or weeks ahead can save energy, reduce congestion, and make businesses more resilient. But the farther we look into the future, the harder it becomes for today’s artificial intelligence tools to cope with shifting conditions, noisy measurements, and limited computing budgets. This paper introduces a new way to train forecasting models so they stay accurate and stable even when the world refuses to sit still.
Learning from many models instead of just one
Most modern time‑series forecasters rely on a single deep neural network trained with gradient descent, the standard method that nudges model parameters step by step to reduce error. That works well when data behave consistently, but it can fail when conditions drift, measurements are noisy, or training time is tight. Instead of inventing a new network design, the authors propose Evolutionary‑Guided Module Fusion with Gradient Refinement (EGMF‑GR), a training framework that can wrap around existing architectures. The key idea is to maintain a small “population” of models that all share the same structure but start from different random settings. During training, these models explore different ways to fit the data, and the best‑performing one at any moment is used to guide improvements in the others.
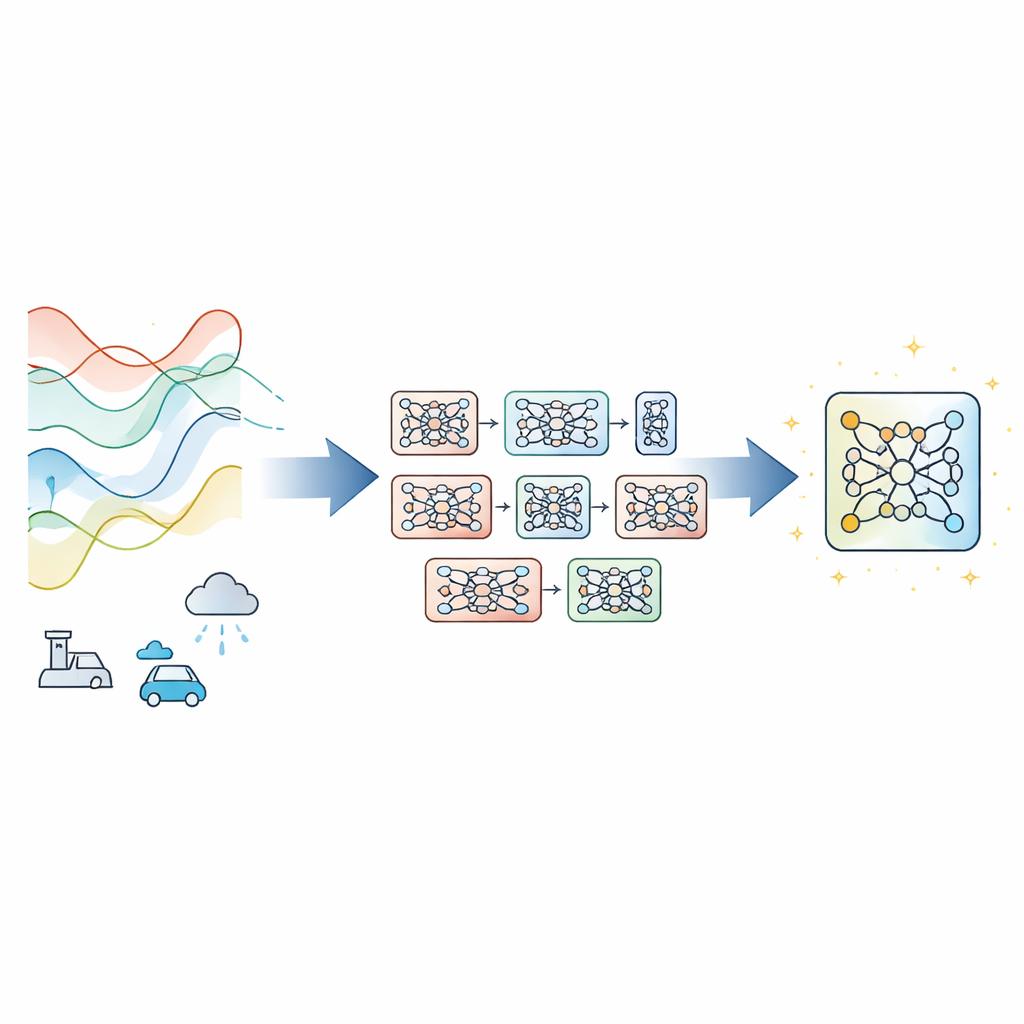
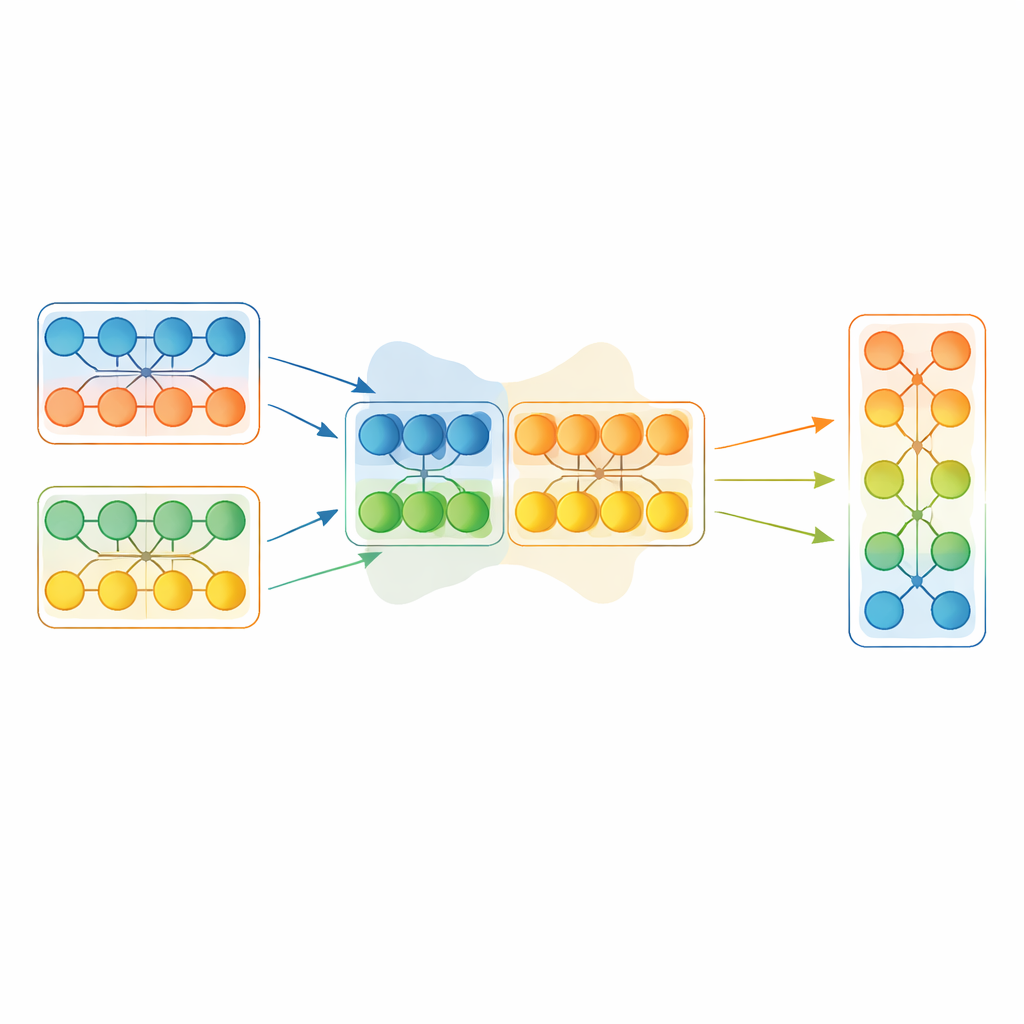
Borrowing good parts while keeping useful diversity
Rather than copying an entire winning model wholesale, EGMF‑GR operates at the level of modules—repeated building blocks inside a network, such as stacks of layers. For each model in the population, the framework aligns corresponding modules with those in the current best model and compares their internal signals as they process the same input batch. It uses several simple measures of difference, capturing both how the patterns of activity are shaped and how large they are. These module‑wise discrepancies are then summarized, and only modules whose behavior looks like strong outliers relative to their peers are considered for updating. When that happens, the lagging module is nudged toward the corresponding module in the best model through a weighted blend of their parameters, plus a small random shake to preserve diversity.
Letting gradients tidy up after the big moves
Blending parts from different networks can introduce abrupt changes. To avoid destabilizing training, each fused model then undergoes a short, conventional gradient‑descent phase on the training data. This refinement step lets the network re‑adapt smoothly to its new internal configuration while keeping the benefits of the borrowed knowledge. The overall procedure alternates: select the current best model based on a held‑out slice of data, selectively fuse modules from that leader into the rest of the population, and briefly fine‑tune everyone with gradients. Crucially, the method also synchronizes internal bookkeeping states, such as running averages used by certain layers, which are often ignored in simpler model‑merging schemes but can greatly affect stability.
Proving the gains across many real‑world signals
To test the framework, the authors applied EGMF‑GR to several popular forecasting backbones, including Transformer‑style models and a recent convolution‑based design, without changing their core structures. They evaluated performance on eight public benchmarks spanning energy usage, traffic flow, exchange rates, and weather, and on multiple forecasting horizons ranging from a few hours to several days ahead. Under a strictly matched budget of expensive backward‑pass updates, the hybrid training consistently reduced prediction errors and smoothed training behavior for most model–dataset combinations, especially in high‑dimensional or noisy settings. The team also compared their approach with common single‑model tricks such as exponential moving averages and stochastic weight averaging, and found that population‑based module fusion brought additional benefits beyond simple weight smoothing.
Staying reliable when conditions go bad
Real systems rarely behave like clean textbook examples, so the authors also tested robustness under tougher scenarios: artificially corrupted inputs, missing chunks of data, and periods where the underlying dynamics change abruptly. EGMF‑GR clearly helped when inputs were noisy or partially missing, suggesting that borrowing stable module behavior from the current best model can counteract local glitches. During sudden regime shifts, the advantage was smaller, hinting that too much alignment may sometimes slow adaptation to new patterns. This points to future refinements where the strength of fusion is dialed back when the environment becomes highly volatile.
What this means for everyday forecasting tools
In simple terms, the study shows that training many cooperating versions of the same forecasting model, and letting them share only the parts that truly stand out as better, can make long‑range predictions more accurate and more stable without redesigning the models themselves. EGMF‑GR works like a disciplined team sport: members occasionally adopt each other’s strongest moves, then practice a bit on their own to fit the current game. For practitioners, this offers a plug‑in training strategy that can bolster existing forecasting systems in finance, energy, transportation, and climate applications, especially when data are messy and compute budgets are tight.
Citation: Zhao, L., Chen, Z., Wu, N. et al. Hybrid evolutionary-gradient training improves long-term time series forecasting. Sci Rep 16, 10697 (2026). https://doi.org/10.1038/s41598-026-45017-y
Keywords: time series forecasting, evolutionary training, neural networks, model fusion, distribution shift