Clear Sky Science · en
Detection of sample swapping in anti-doping investigations using machine learning
Why catching clever cheats matters
Elite sports rely on trust: when an athlete wins, we want to believe the result is clean. Modern drug tests are very sensitive, yet some athletes try to outsmart them by secretly swapping urine samples. This study shows how machine learning can spot when an athlete reuses a previously collected “clean” sample, a trick that is extremely hard to catch with today’s routine checks. The work points to new ways of protecting fair play by quietly scanning huge testing databases for hidden evidence of tampering.
A hidden loophole in current testing
Anti-doping laboratories usually test urine, because many banned drugs and their breakdown products stay detectable there for a long time. Athlete profiles of natural steroid hormones are tracked over years in the Athlete Biological Passport, so a sudden jump in these values can trigger an investigation. Swapping in someone else’s urine disrupts this long-term pattern and is often detectable. The real blind spot arises when an athlete secretly reuses their own earlier, drug-free urine. In that case, the steroid pattern fits perfectly into their history, and if the sample is tested in a different lab or long after the original, there is currently no automatic way to notice that two samples are essentially the same.
Turning urine chemistry into searchable patterns
The authors tackled this problem by focusing on the detailed “fingerprint” formed by a set of natural steroids and their ratios in urine. They gathered 67,651 steroid profiles from a World Anti-Doping Agency (WADA)–accredited lab collected between 2021 and 2023, covering both male and female athletes. Each profile contains key hormones such as testosterone and several related compounds, plus ratios between them. Because true cases of sample reuse are rare and confidential, the team combined this real-world data with carefully crafted synthetic pairs of profiles: some pairs were made “similar” by adding small, realistic measurement noise, and others were made “dissimilar” by randomly pairing samples from different athletes. This provided balanced training material for a computer model to learn what “almost identical” really looks like in practice.
How the smart detector works
The core of the system is a type of artificial neural network known as a convolutional network, widely used in image recognition. Here, instead of pictures, the input is a pair of steroid profiles arranged side by side. The network scans across the features to pick up subtle local relationships, such as how two hormones and their ratio move together. To make the data more manageable and interpretable, the researchers also used a technique called principal component analysis to project all profiles into a three-dimensional space, where simple distance measures can highlight close matches. During training, the network learns to output a probability that two profiles come from the same underlying urine, distinguishing real similarity from the normal biological differences seen across athletes and over time.
Putting the method to the test
The team evaluated their approach on several fronts. First, they tested it on held-out data from each year, using profiles that had not been seen during training but were perturbed within the expected 15% measurement uncertainty. The convolutional network consistently achieved very high accuracy, correctly identifying similar pairs while keeping false alarms low, and it outperformed more traditional methods such as logistic regression, support vector machines and tree-based models. Next, they challenged the system with more than 800 “confirmation” samples—real urine specimens that laboratories had reanalyzed under slightly different procedures. These provide a realistic stand-in for repeated or reused samples. Again, the network performed extremely well for both men and women, with excellent sensitivity (catching true matches) and specificity (avoiding spurious ones), suggesting it can cope with real laboratory noise and biological variation.
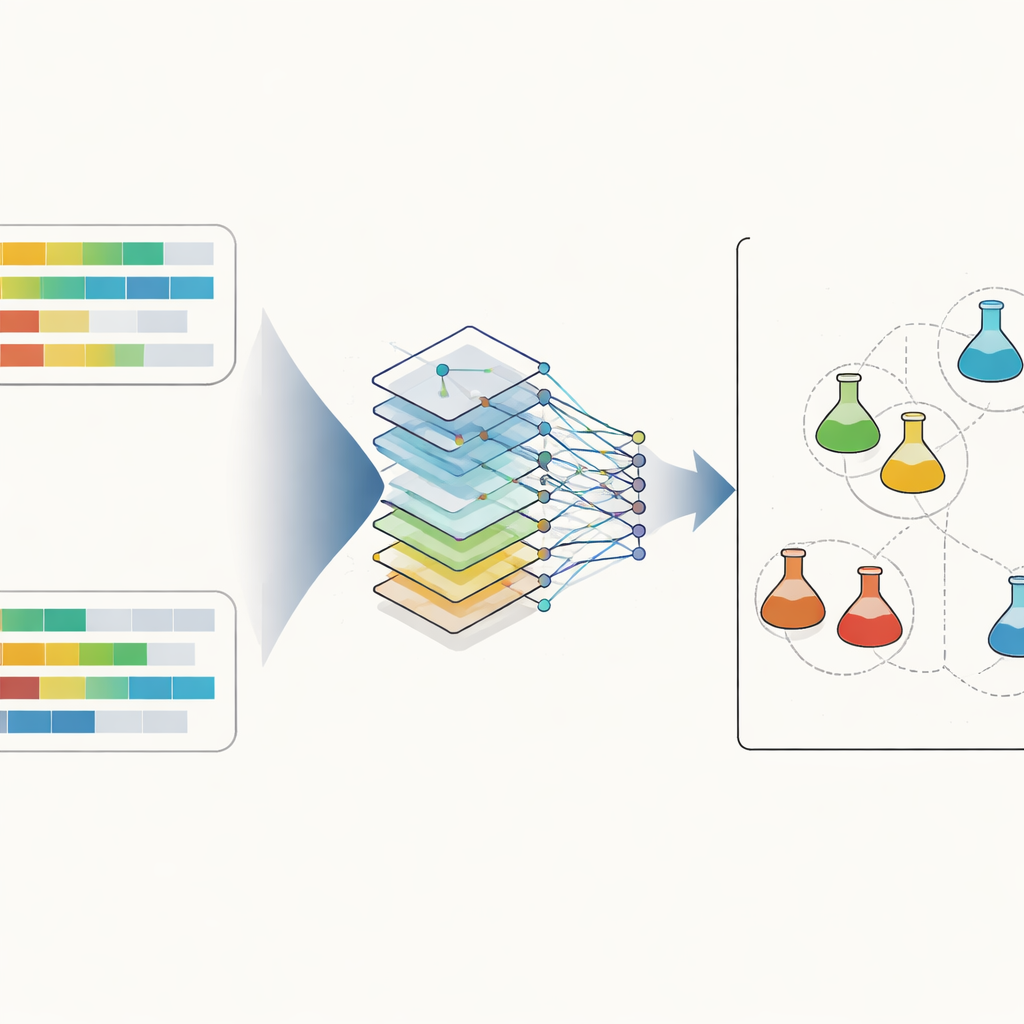
What this means for clean sport
For non-specialists, the key takeaway is that it is now becoming feasible to automatically scan vast anti-doping databases for signs that a supposedly new urine sample is, in fact, a near-perfect copy of an older one. The proposed machine learning framework does not replace existing tests for banned substances; instead, it adds a powerful background check that can flag suspiciously similar samples for closer forensic review. While the method depends partly on simulated data and uses complex “black-box” models that are not fully transparent, it still offers sports authorities a practical new tool. If integrated into current Athlete Biological Passport systems, it could make the once-undetectable trick of reusing clean urine far riskier, strengthening confidence that medals are earned on merit rather than manipulation.
Citation: Rahman, M.R., Piper, T., Thevis, M. et al. Detection of sample swapping in anti-doping investigations using machine learning. Sci Rep 16, 9230 (2026). https://doi.org/10.1038/s41598-026-43502-y
Keywords: anti-doping, urine steroid profiles, sample swapping, machine learning, sports integrity