Clear Sky Science · en
Rethink context engineering using an attention-based architecture
Why Smarter Software Helpers Matter
Every click you make in a business app—logging in, uploading a file, running a report—leaves a trail. If software could reliably predict your next move, it could pre-load data, suggest shortcuts, and respond almost instantly. This paper explores a new way to teach computers to understand these trails of actions so well that digital assistants can anticipate what you will do next, what you are trying to achieve, and when you are about to sign off.
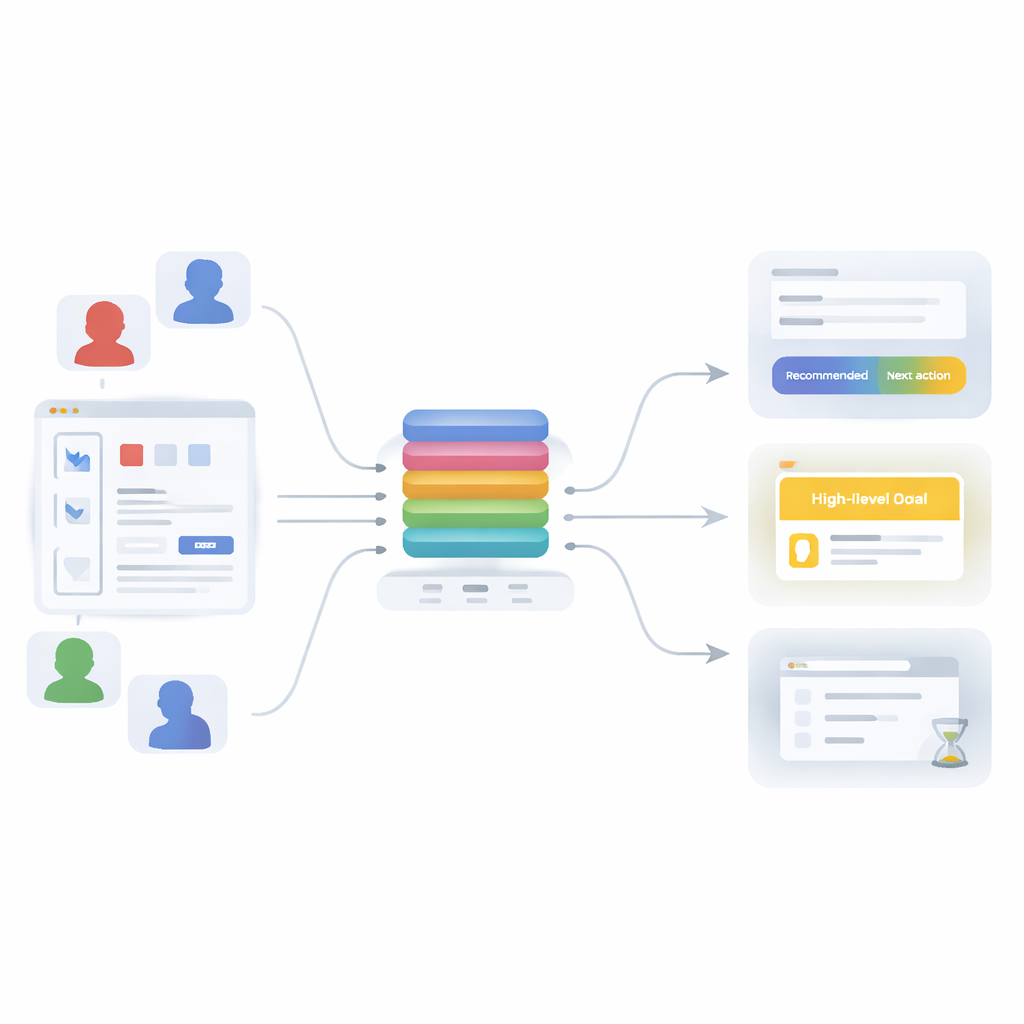
From Simple Chains to Rich Patterns
Many existing systems that guess a user’s next step rely on Markov chains, a classic mathematical tool that looks only at the most recent action to predict the next one. While fast and convenient, this “one-step memory” approach breaks down in real workplaces, where tasks like building a machine learning pipeline or preparing a dashboard unfold over many steps and involve different tools. The authors argue that such simple models miss long-range structure, can handle only one prediction goal at a time, and are hard to compare across studies because they usually depend on private logs and opaque data cleaning choices.
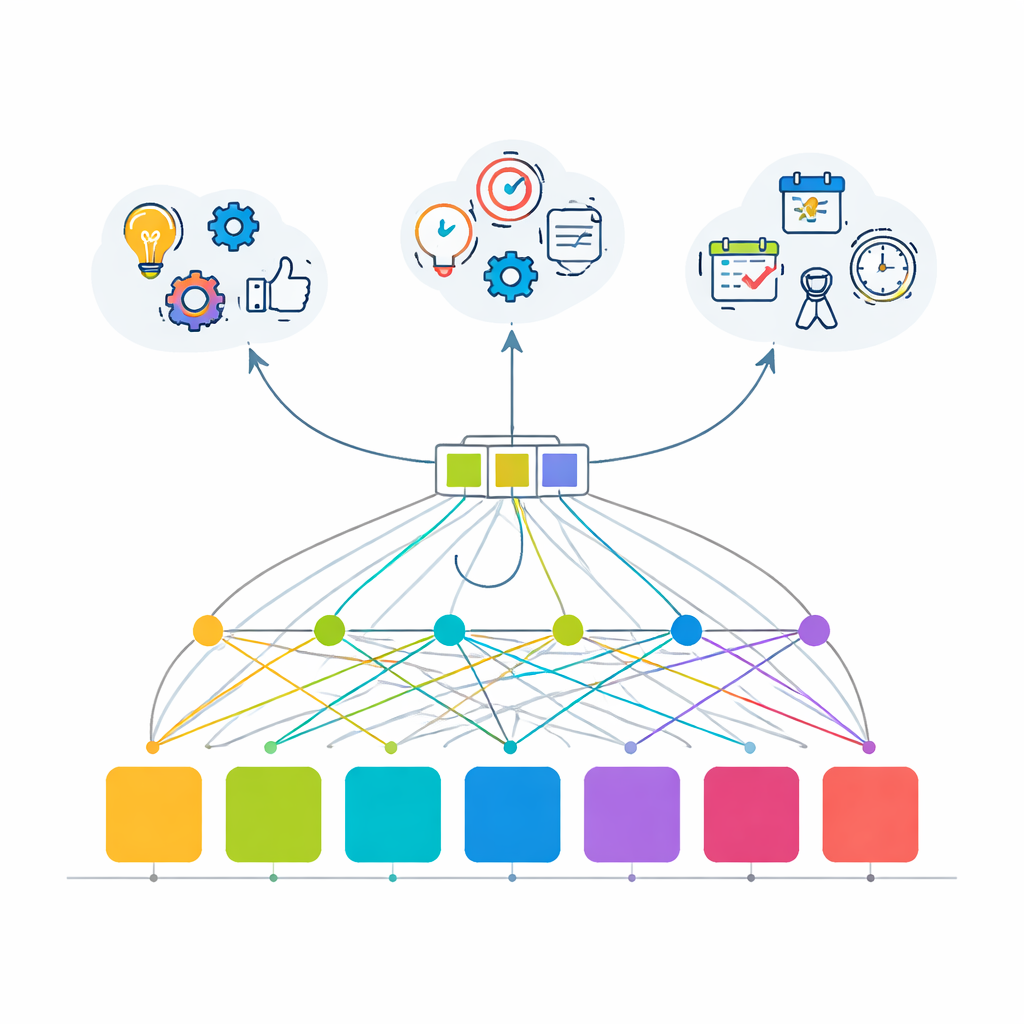
A New Multi-Task Learning Blueprint
To overcome these limits, the paper introduces an attention-based transformer model—the same family of techniques behind modern language tools—reimagined for user behavior. Instead of learning just one thing, the model is trained to solve three related tasks at once: predicting the next action (which API a user will call), inferring the overall goal of the session (such as running a machine learning workflow, doing data analysis, managing users, or creating quick visualizations), and deciding whether the current step is likely to be the last one in the session. All three tasks share a common “backbone” that turns a short history of recent actions into a single, rich representation of what is going on, which is then fed into three small prediction modules.
Building a Realistic Testbed in Silico
Because real enterprise activity logs are often sensitive and hard to share, the authors construct a sophisticated simulated environment that mimics how data professionals use a large internal platform. They define 100 distinct APIs grouped into 10 functional areas, including authentication, data input, processing, model training, visualization, export, and administration. Four user personas—data scientists, business analysts, developers, and power users—follow characteristic but imperfect workflows, with probabilities that reflect both routine behavior and occasional detours. The resulting dataset contains 2,000 user sessions and 20,000 API calls, with session goals like “machine learning pipeline” and “quick visualization” producing recognizable paths such as logging in, loading data, processing it, making a chart, and exporting the result.
How Well the Model Learns to Anticipate
Trained on this structured yet varied environment, the transformer model shows that attention-based learning can capture the hidden regularities in user behavior much better than older methods. For the main task—guessing the very next API call among 100 choices—it gets the answer exactly right almost 80% of the time, and places the correct choice in its top five suggestions more than 99.9% of the time, a jump of more than fourfold over a basic Markov chain. At the same time, it correctly identifies the user’s overall session goal in about 82% of cases and almost perfectly detects when a session is about to end. The authors also emphasize that the model is relatively compact and efficient, making real-time use feasible for live assistants that must respond without noticeable delay.
Tools for Others to Reuse and Extend
To make their approach more than a one-off experiment, the authors release an open-source software package, called context-engineer, along with the full simulated dataset. With these resources, other researchers and practitioners can reproduce the reported results, test alternative models on a shared benchmark, or plug in their own internal logs by mapping actions and session labels into a simple numeric format. This openness addresses a major hurdle in the field, where many past systems could not be fairly compared or re-used because their data and code were unavailable.
What This Means for Everyday Users
For a non-specialist, the key takeaway is that the paper offers a practical recipe for making digital tools feel more “one step ahead.” By jointly learning what people are trying to do, what they are likely to click next, and when they are wrapping up, the proposed transformer-based system turns user histories into a form of context awareness. In real applications, this could mean chatbots that ready the next report before you ask, analytics platforms that suggest sensible follow-up actions, and enterprise dashboards that quietly trim waiting time. Although the current study is based on simulated data and needs testing on real logs, it lays a clear, reproducible foundation for building smarter, more anticipatory software helpers across many kinds of digital platforms.
Citation: Yin, Y. Rethink context engineering using an attention-based architecture. Sci Rep 16, 8851 (2026). https://doi.org/10.1038/s41598-026-43111-9
Keywords: user behavior prediction, sequential recommendation, attention-based transformer, proactive digital assistants, context engineering