Clear Sky Science · en
Integrating machine learning techniques for critical node identification in complex networks
Why finding key points in networks matters
From social media and airline routes to power grids and email systems, many parts of modern life can be thought of as networks. In these webs of connections, some points – people, airports, power stations, or computers – matter far more than others. Spotting those crucial points can help us slow epidemics, protect infrastructure, and spread information efficiently. This paper explores how modern machine learning can outperform traditional methods at detecting those critical spots, especially when something is actively spreading through the network.
Old ways to spot important points
For decades, researchers have used simple structural scores, called centrality measures, to decide which nodes in a network are most important. These scores look at features such as how many direct links a node has, how close it is to all others, or how often it lies on shortest routes between pairs of nodes. While useful, these measures have drawbacks. Some focus only on a node’s immediate neighborhood and miss the big picture. Others consider the whole network but become expensive to compute as the network grows. Most importantly, they assume that a node’s structural position alone tells us how strongly it will influence a real spreading process, such as a disease outbreak or a viral message.
Adding spreading behavior to the picture
To bridge this gap, the authors explicitly model how something spreads across a network and use those results to teach machine learning models what truly influential nodes look like. They rely on two common epidemic-style models. In one, each node can be susceptible, infected, or recovered, and infection travels along links with a given probability. In the other, each newly infected node gets one chance to infect its neighbors. By repeatedly simulating these processes from each starting node, the authors measure how big an outbreak each node can trigger. These outbreak sizes are then turned into a set of labels that group nodes into several influence levels, from weak spreaders to very strong ones.
Teaching machines to recognize power nodes
Once every node has a label, the authors build a feature profile that mixes structural information with spreading conditions. For each node, they gather standard centrality scores – capturing local connectivity, global position, and the strength of neighbors – and also include the infection rate used in the simulations. These values are normalized so the method can adapt to networks of very different sizes. With this labeled dataset in hand, they train a range of off‑the‑shelf machine learning models, including decision trees, random forests, support vector machines, logistic regression, k‑nearest neighbors, and neural networks. They also design a hybrid method that first groups nodes with similar features into clusters using K‑means, then trains a support vector classifier separately within each cluster. This hybrid approach aims to capture subtle, nonlinear patterns without being overwhelmed by the full complexity of the network.
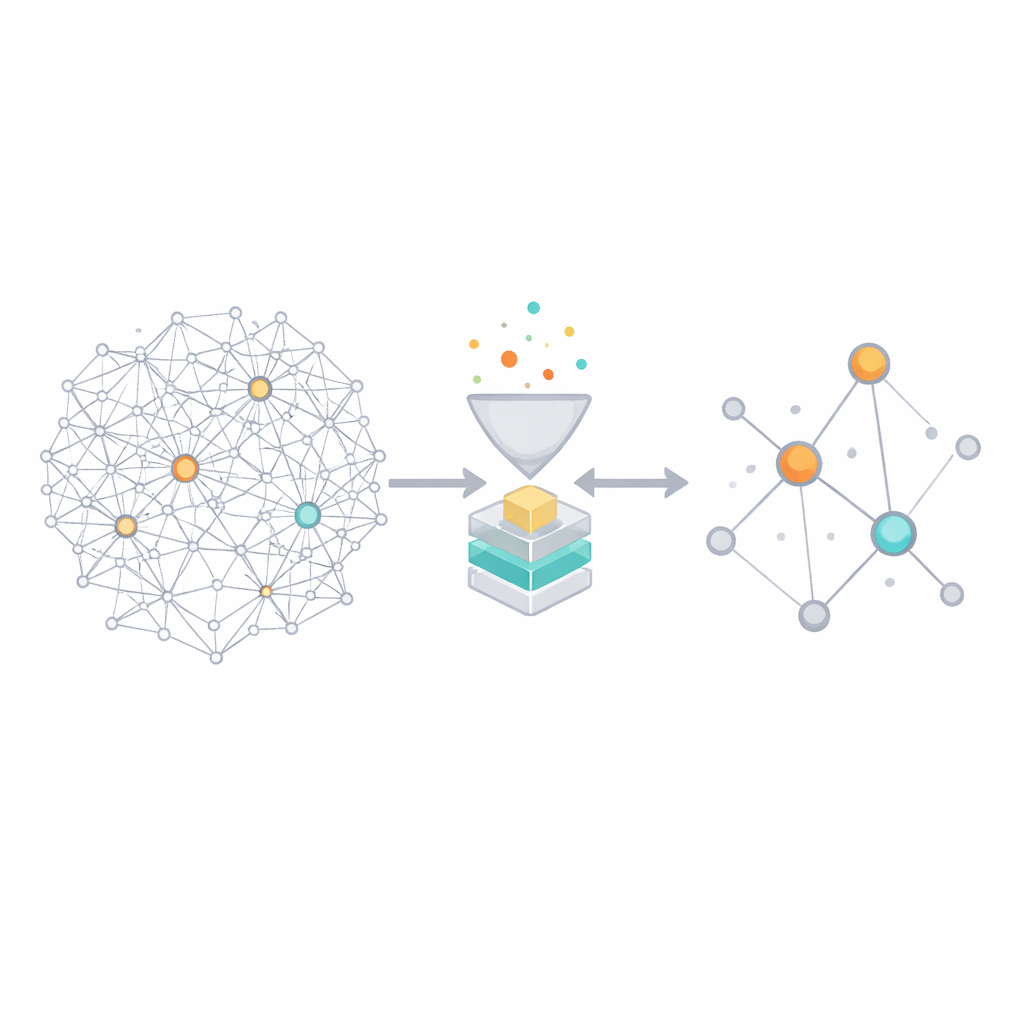
Putting the methods to the test
The authors evaluate their framework on seven real-world networks, covering airline routes, road systems, scientific collaborations, biological networks, and email exchanges. They compare their machine learning models against classical centrality scores in two main settings. In the first, the models are trained and tested on different parts of the same network. Here, the hybrid clustering‑plus‑classification method consistently achieves the highest accuracy, precision, recall, and F1‑score, often beating traditional centrality by 15–45 percentage points when classifying nodes into influence levels. In the second setting, models are trained on one network and tested on a different one. In this tougher cross‑network scenario, classic betweenness-based scores tend to outperform the machine learning models, highlighting that patterns learned in one structure do not always transfer cleanly to another.
What this means in practice
For situations where we can afford to run detailed simulations on a given network – such as a specific power grid, a social platform, or a transportation system – the proposed machine learning framework offers a more accurate and scalable way to pinpoint the most influential nodes than relying on structure alone. By combining how nodes are wired with how contagion actually flows, and by using a smart hybrid of clustering and classification, the method can more reliably flag the few elements whose failure or activation would make the biggest difference. At the same time, the results remind us that no single model works best everywhere: simple, structure-based scores may still be preferable when we must generalize from one network to another without fresh simulations.
Citation: ReddyPriya, M., Enduri, M.K., Hajarathaiah, K. et al. Integrating machine learning techniques for critical node identification in complex networks. Sci Rep 16, 8929 (2026). https://doi.org/10.1038/s41598-026-40778-y
Keywords: influential nodes, complex networks, machine learning, epidemic spreading, network centrality