Clear Sky Science · en
Dynamic machine learning approach for workload prediction in cloud environments
Why smart traffic prediction matters
Every time you stream a video, follow a big sports event online, or shop during a flash sale, thousands of others may be clicking at the same moment. Behind the scenes, cloud data centers scramble to keep websites fast without wasting money on idle machines. This paper tackles a simple question with huge practical impact: how can cloud systems anticipate sudden waves of web traffic well enough to turn servers on and off just in time, instead of guessing and overpaying?
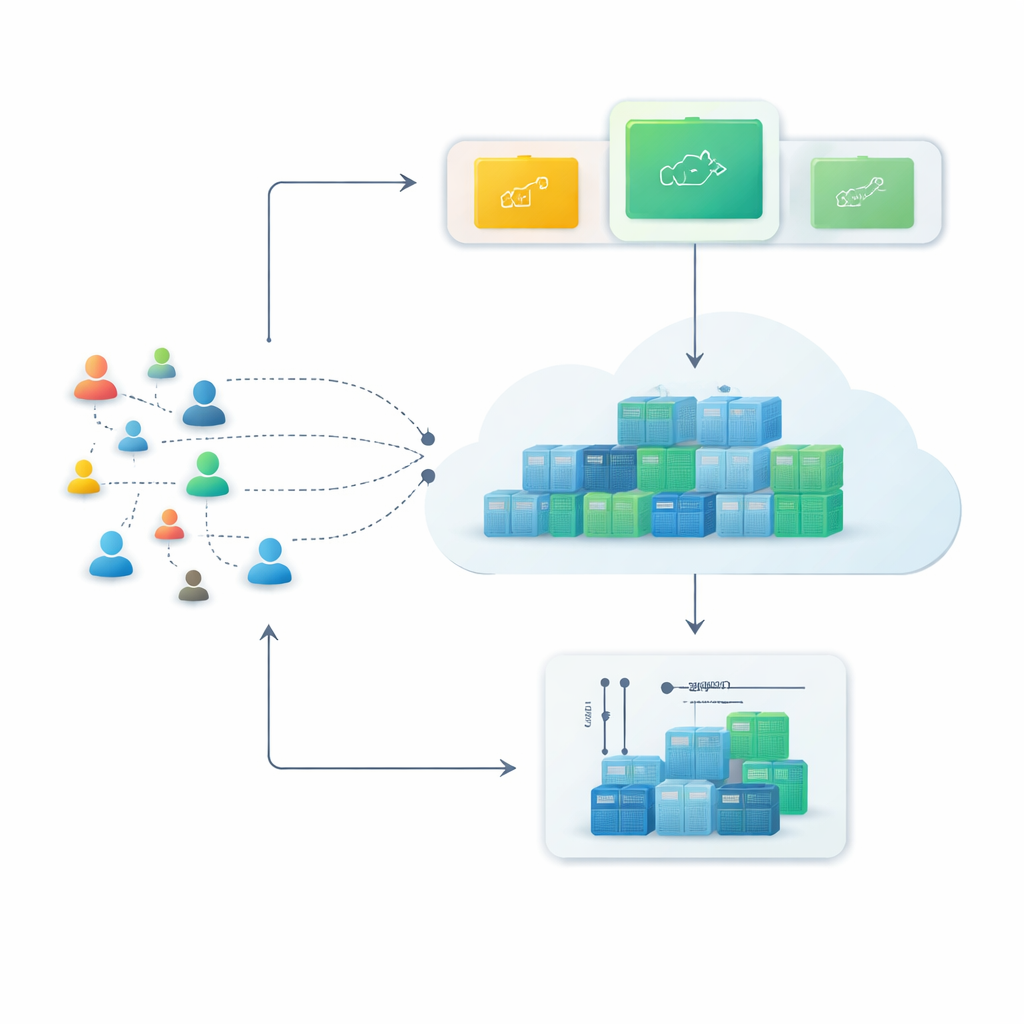
From rigid servers to flexible containers
Modern cloud platforms increasingly rely on containers, small software packages that can be started or stopped in seconds. Compared with traditional virtual machines, containers are lighter and can be packed more densely, making them perfect for services that must grow quickly during busy hours and shrink again afterward. Yet this flexibility only pays off if the system can see trouble coming—if it can predict how many web requests will arrive in the next few minutes and prepare the right number of containers in advance.
Why one-size-fits-all prediction fails
Earlier research has tried many different ways to forecast web traffic, from classical statistics to deep neural networks. Some work well when demand changes smoothly over the day; others are better when traffic jumps unpredictably, as during a match in the World Cup. The problem is that no single method is best all the time. If operators pick one favorite model and stick with it, accuracy can drop sharply whenever user behavior changes, leading either to sluggish sites or to rows of underused machines quietly burning money and energy.
A learning loop that never stops adapting
To overcome this, the authors propose a closed-loop framework they call Monitor–Train–Test–Deploy. The idea is to treat prediction itself as a living process. First, the system continuously records incoming web requests into a time-stamped history. Next, it trains several different forecasting methods in parallel, each trying to learn patterns in that recent history. Then it tests these candidate models on the latest data and scores them according to how far their guesses stray from reality. Only the best-performing model is put in charge of making live predictions, which guide how many containers to run. As fresh traffic arrives, the loop repeats: if prediction errors grow beyond a tolerated level for two cycles in a row, the system automatically retrains and may hand control to a different model.
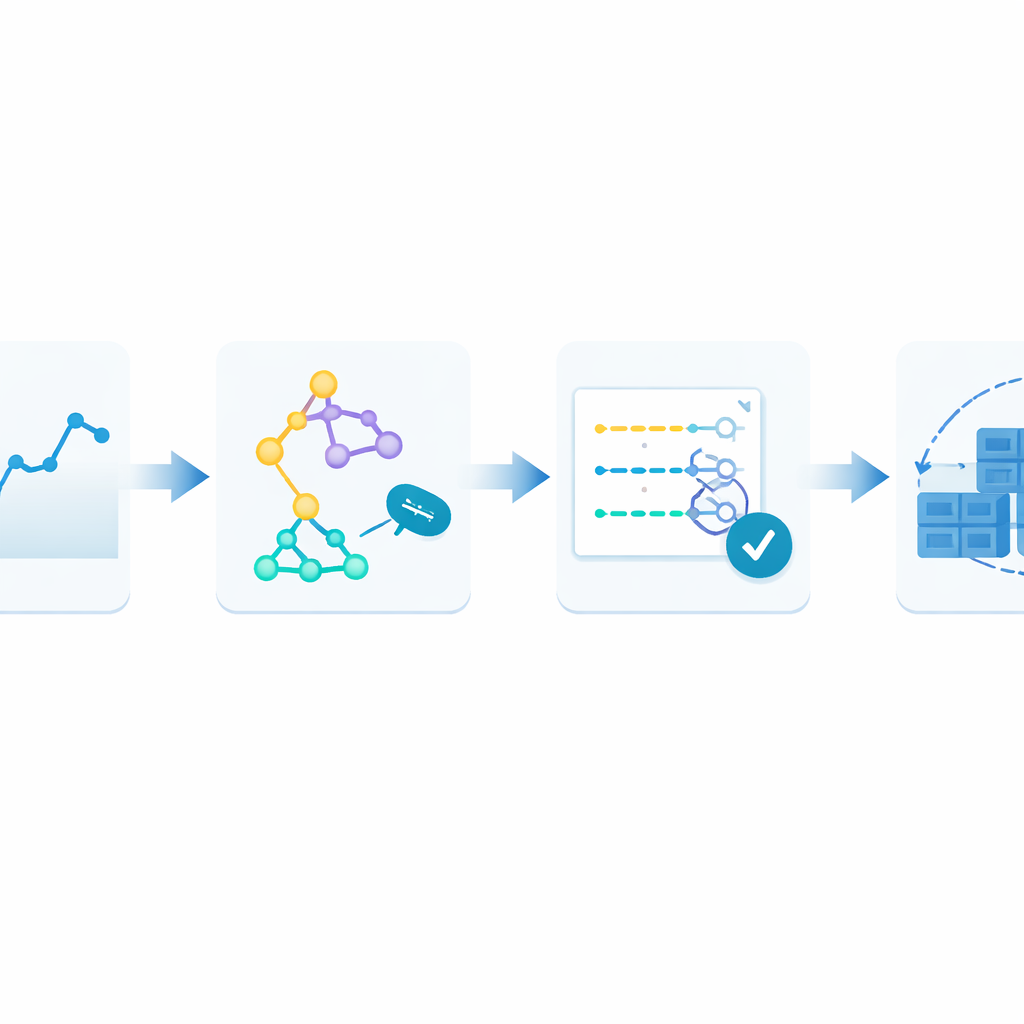
Putting the framework to the test
The researchers evaluated this approach using both synthetic and real traces of web activity. They generated several idealized patterns—smooth bell-shaped curves, steadily rising loads at different speeds, and highly erratic traffic—and also used records from the official World Cup websites in 1998 and 2018, where interest spikes abruptly. For each case, they compared three or four familiar prediction tools, including a statistics-based method, a support-vector model, a decision-tree ensemble, and, in later experiments, a popular type of recurrent neural network. The key result was that the “winner” changed with the situation: simple statistical models excelled when demand was steady, while learning-based methods were clearly superior when traffic turned wild and bursty.
Gains in accuracy and efficiency
By continually switching to whichever model was currently best suited to the observed behavior, the framework cut prediction errors by up to about 15 percent compared with sticking with any fixed model. Just as important, it did this without running all models all the time. Only one predictor is active during live operation; the others are retrained and checked periodically, keeping the computational burden modest. The authors also introduce a gradually tightening threshold for when to retrain, so that the system becomes less tolerant of repeated mistakes, reducing the risk of long stretches of poor forecasting.
What this means for everyday cloud users
In practical terms, the study shows that cloud platforms can be run more intelligently by letting forecasting models compete and by adapting their choice over time. For users, that can translate into smoother online experiences during big events and fewer slowdowns when crowds appear unexpectedly. For providers, it promises leaner use of computing resources, lower operating costs, and less wasted energy. Rather than betting on a single clever algorithm, this work argues for a flexible control loop that keeps learning, testing, and revising how it anticipates demand in an increasingly unpredictable digital world.
Citation: Nashaat, M., Moussa, W., Rizk, R. et al. Dynamic machine learning approach for workload prediction in cloud environments. Sci Rep 16, 10983 (2026). https://doi.org/10.1038/s41598-026-40777-z
Keywords: cloud workload prediction, autoscaling, containers, machine learning, time series