Clear Sky Science · en
A privacy-preserving multi-user retrieval system for multimodal artificial intelligence
Why keeping smart searches private matters
Many of us now rely on cloud-based artificial intelligence to sift through our photos, documents, and even medical scans. These systems are powerful because they can understand both pictures and words, but they also raise a hard question: how can we enjoy this convenience without handing over the meaning of our most sensitive data to distant servers? This paper introduces PMIRS, a new system that aims to let many users search across mixed image-and-text collections while keeping their information hidden from the cloud machines that power those searches.
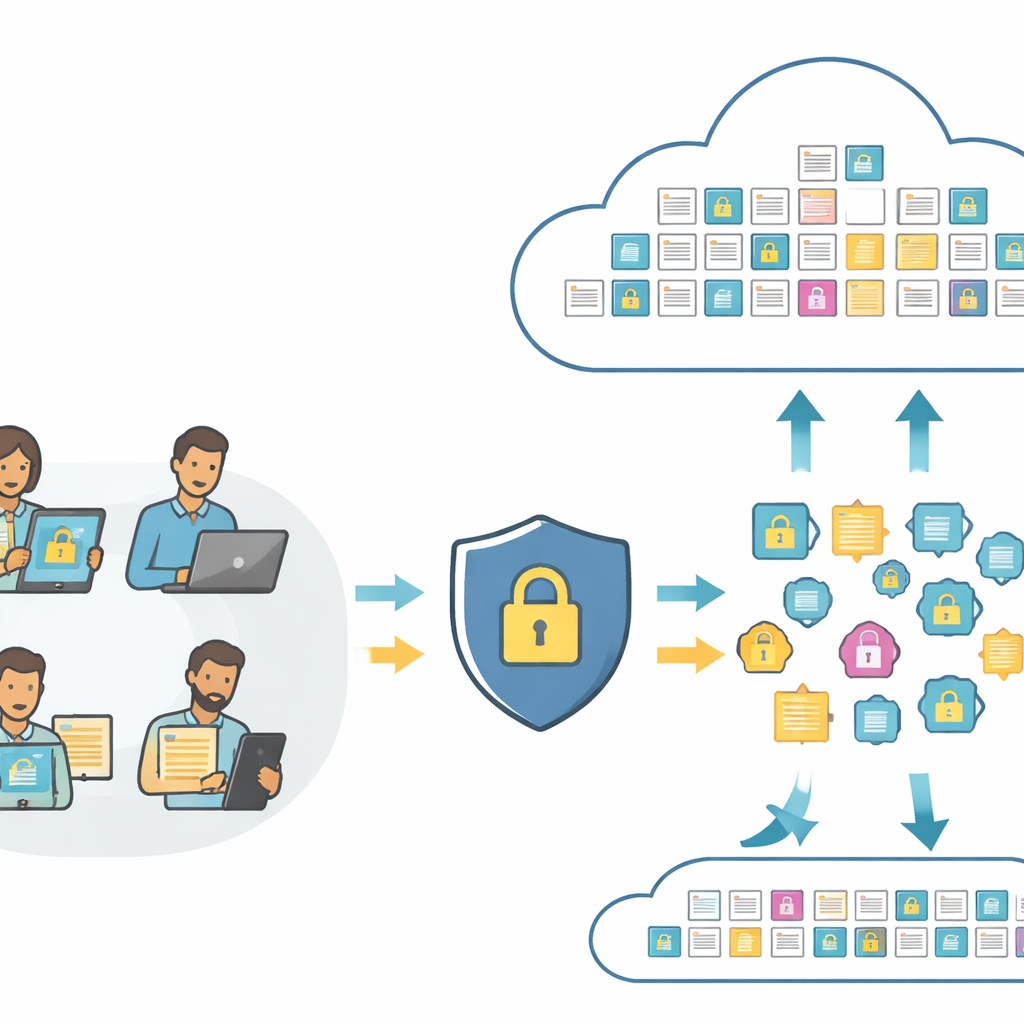
Searching pictures and text without showing their meaning
At the heart of modern search tools are "embeddings"—numeric fingerprints that capture the content of a photo or a sentence so a computer can compare them. Standard systems send these fingerprints directly to the cloud, where they can be analyzed or even misused. PMIRS rearranges this pipeline. Users first send their raw images and text to a local layer, which turns them into fingerprints using a compact vision-and-language model. Before anything leaves the user’s side, the fingerprints are scrambled in a controlled way and then encrypted. The cloud only ever sees these protected fingerprints and fully encrypted copies of the stored data, yet it can still carry out matching and return the best hits.
Learning from many users without pooling their data
Training a good image–text model normally requires gathering huge amounts of labeled examples in one place—a clear privacy risk. PMIRS instead uses federated learning. In this setup, the underlying model, adapted from the well-known CLIP architecture, is sent out to many devices. Each one trains locally on its own private image–text pairs and sends back only updated model weights, which are themselves encrypted. A central server averages these updates to improve a shared model without ever seeing any user’s raw photos or descriptions. The authors further shrink and fine-tune the model through a staged "distillation" process that prunes unnecessary parts while preserving accuracy, making the system lightweight enough for practical deployment.
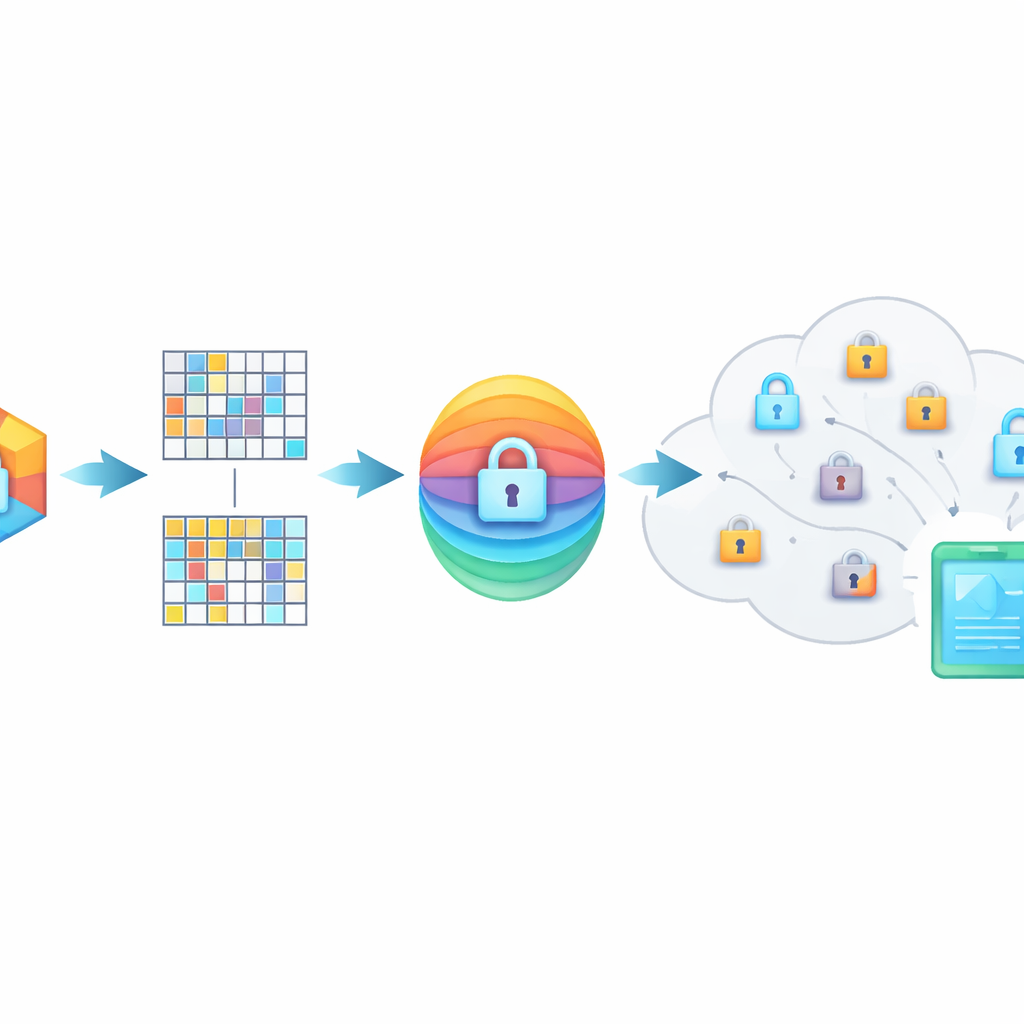
Hiding the meaning inside scrambled fingerprints
PMIRS protects queries with a two-layer shield. First, every fingerprint is cut into blocks and each block is transformed by a secret matrix, plus a carefully designed noise pattern. This scrambling hides the original structure of the data but is set up so that, when two related items are both transformed, their similarity stays the same. Second, the result is encrypted using the widely adopted AES method, with keys that are never sent openly across the network. For situations where one person needs to search another person’s data—such as a doctor consulting a specialist—the system uses a Diffie–Hellman key exchange protocol so they can agree on shared secrets without exposing them to eavesdroppers.
How well the system performs in practice
To test whether these protections come at too great a cost, the researchers built a benchmark that pairs everyday images with short natural-language phrases—closer to how people actually describe things than single-word labels. They compared PMIRS with a standard CLIP-based search across three themes: natural scenes, manufactured objects, and activities or landscapes. Across many repository sizes, PMIRS consistently found a better balance between catching all the right results (recall) and avoiding false matches (precision), leading to an average F1-score—a combined accuracy measure—about 7.7% higher than the baseline. Importantly, response times stayed below about 180 milliseconds, fast enough for interactive use, and often slightly faster than the unsecured baseline despite the extra protection steps.
What this means for everyday users
In plain terms, PMIRS shows that it is possible to build cloud search tools that understand images and text well, serve many users at once, and still keep each person’s data meaning out of reach of the cloud provider. By combining local training, clever scrambling of fingerprints, strong encryption, and secure key exchange, the system offers an end-to-end privacy-preserving pipeline rather than protecting only one stage. While it does not yet cover every possible attack and will need further refinement and real-world trials, the work points toward future services—such as medical image lookup, customer-support bots, or enterprise archives—where people can enjoy rich, multimodal AI search with far less worry that their personal content will be revealed or misused.
Citation: Gao, Y., Luo, W., Wang, C. et al. A privacy-preserving multi-user retrieval system for multimodal artificial intelligence. Sci Rep 16, 10348 (2026). https://doi.org/10.1038/s41598-026-40734-w
Keywords: privacy-preserving AI, multimodal retrieval, federated learning, encrypted search, secure cloud computing