Clear Sky Science · en
Clustering-cum-regression based model and performance analysis for early prediction of heart disease
Why catching heart trouble early matters
Heart disease often develops silently over many years, and by the time clear symptoms appear, damage may already be done. This study explores how everyday body-worn sensors and smart data analysis can work together to spot warning signs earlier, giving doctors and patients more time to act. By combining two different ways of looking at health data, the researchers aim to make predictions more accurate without making the technology harder to use in real clinics.
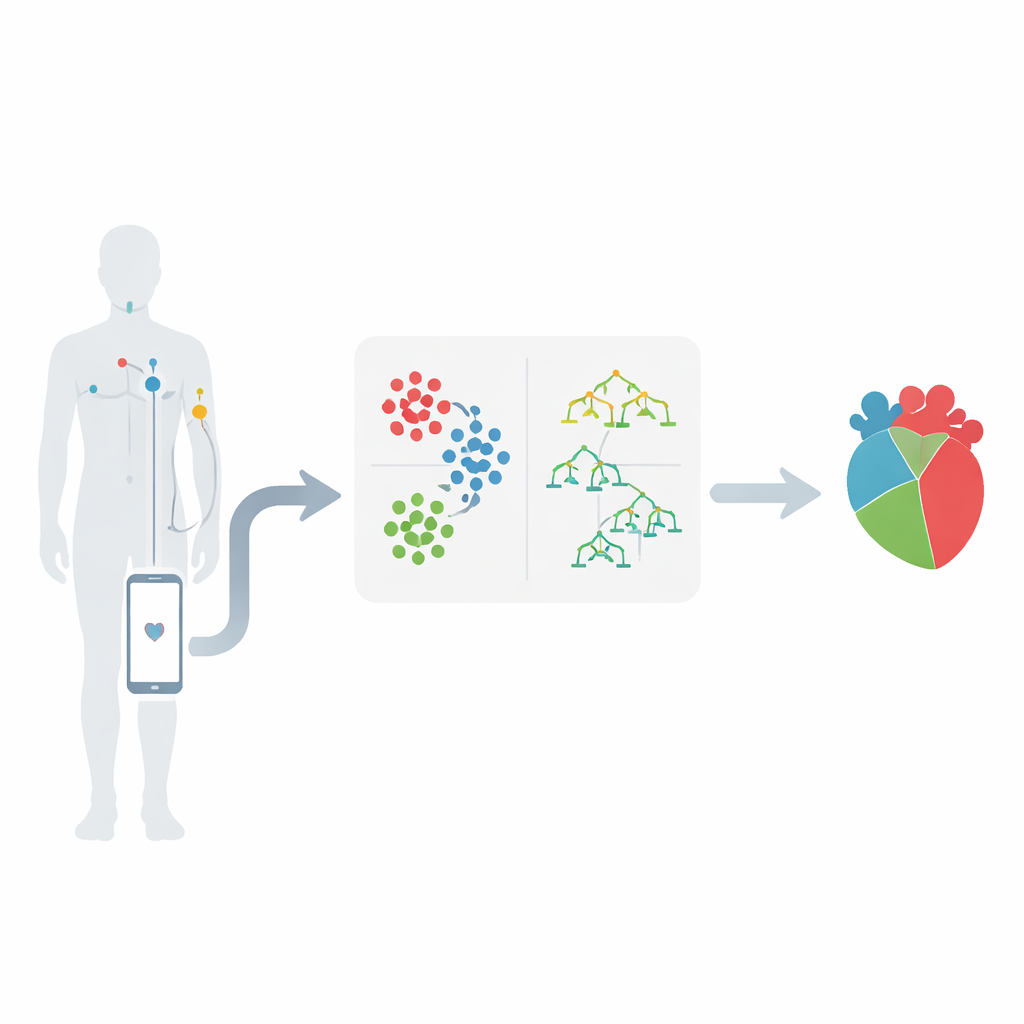
From body sensors to smart warnings
The work is set in the world of wireless body area networks, where small sensors placed on the skin track signals such as heart rate, blood pressure, and electrical activity of the heart. These sensors send measurements to a mobile device, which forwards them to a medical center for analysis. The key idea is that these streams of numbers can reveal patterns that hint at developing heart problems long before a crisis. The authors focus on a well-known heart disease dataset, selecting 12 important features including chest pain type, blood pressure, cholesterol, blood sugar, exercise-induced chest discomfort, and changes seen on an electrocardiogram.
Finding hidden groups in patient data
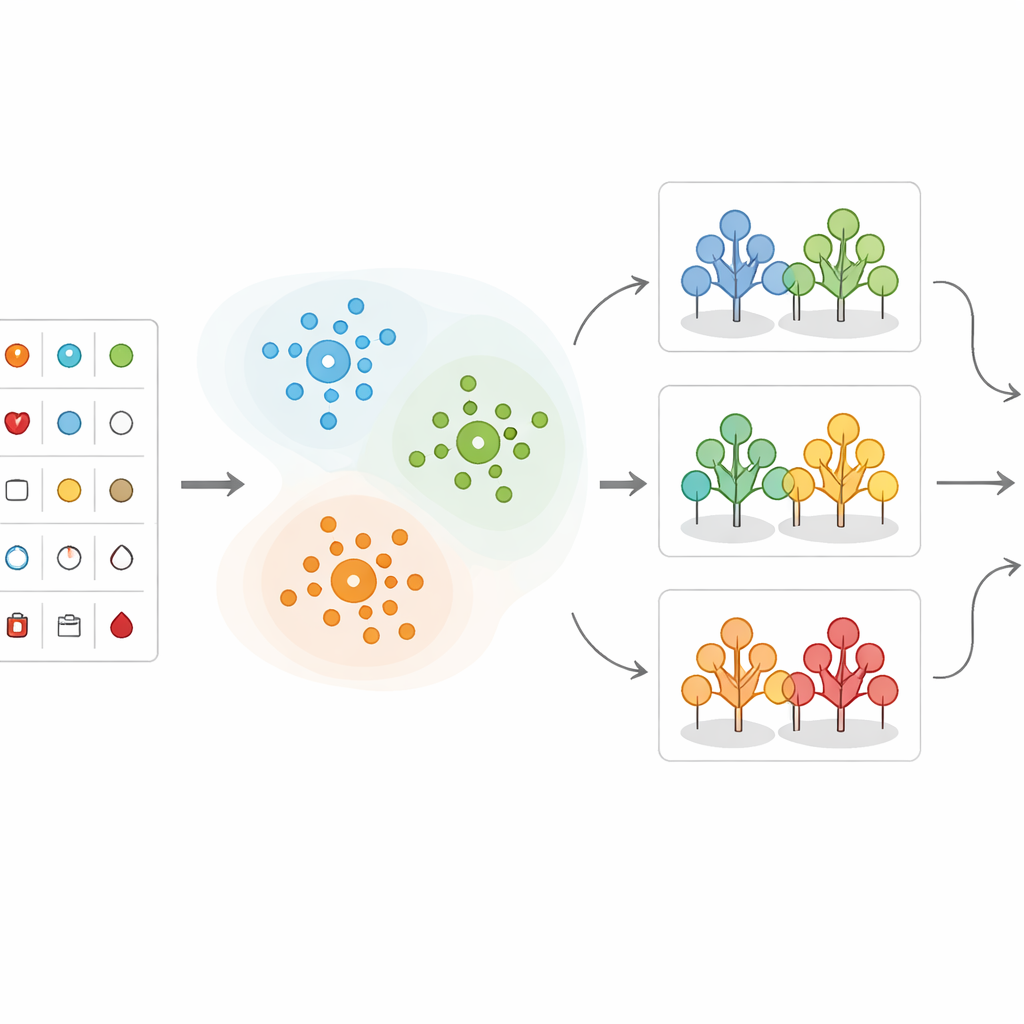
Instead of feeding all patient records directly into a single prediction formula, the team first groups similar patients together. They use a method called K-means clustering, which sorts people into clusters based on how alike their measurements are, with age playing a central role. For example, patients can naturally fall into groups with very high blood pressure, high cholesterol, or particular patterns on heart tests. This grouping step helps highlight which combinations of measurements are especially worrisome. It also reveals that certain ranges—such as blood pressure above 150, cholesterol above 300, or particular changes in heart tracings—tend to be linked with much higher risk.
Teaching machines to judge risk
After the data are grouped, the researchers apply several machine-learning methods that learn from past cases to predict whether a new patient is likely to have significant heart disease. They compare different approaches, including decision trees, k-nearest neighbors, support vector machines, logistic regression, Naïve Bayes, and random forests. In their hybrid design, each new patient is first assigned to the closest cluster; then a random forest model trained specifically on that type of patient makes the final risk prediction. The data are carefully cleaned, scaled, and split into training and testing sets, and class imbalance (more healthy than sick patients) is handled so that the models do not become biased toward the majority group.
How well the hybrid model performs
To judge success, the study looks not only at overall accuracy but also at how often the model correctly flags sick patients (recall), correctly reassures healthy ones (specificity), and balances both goals (F1 score and ROC–AUC). Earlier studies using similar data often topped out around 85 percent accuracy and struggled to improve these finer measures. Here, the combined clustering-plus-random-forest approach reaches about 91 percent accuracy, with strong recall and very high specificity. The confidence ranges for this model do not overlap with those of the simpler methods, suggesting the improvement is unlikely to be due to chance. At the same time, computing time stays in a practical range—on the order of milliseconds to seconds—suitable for real-time or near‑real‑time monitoring systems.
What this means for patients and doctors
In everyday terms, the study shows that letting computers first sort patients into meaningful groups and then apply tailored prediction rules can sharpen early detection of heart disease. The method is especially promising for continuous monitoring setups, where wearable sensors quietly collect data in the background. While the results come from a modest-sized, structured dataset rather than full clinical records, and the authors caution about possible biases, the message is clear: smarter use of existing measurements can give doctors a more reliable early warning system. With further work and larger, richer datasets, this kind of hybrid analysis could help turn raw sensor readings into timely, personalized alerts that prevent heart attacks and other serious events before they occur.
Citation: Tolani, M., AlZahrani, Y., Suman, G. et al. Clustering-cum-regression based model and performance analysis for early prediction of heart disease. Sci Rep 16, 9494 (2026). https://doi.org/10.1038/s41598-026-40626-z
Keywords: heart disease prediction, wearable health sensors, machine learning, medical data clustering, random forest model