Clear Sky Science · en
Research on super-resolution reconstruction of construction images based on attention mechanism and generative adversarial networks
Sharper Eyes on Busy Building Sites
Modern construction sites bristle with cameras, drones, and sensors, but many of the images they capture are disappointingly blurry or low in detail, especially at long distances or in poor light. This paper presents a new way to turn those rough images into crisp, high‑resolution views fast enough for live monitoring, helping engineers and safety managers see small but important details such as helmets, cracks, or loose materials that might otherwise be missed.
Why Blurry Pictures Are a Real Problem
On a construction site, a single camera feed can support many tasks at once: checking whether workers wear helmets, tracking where people and machines move, spotting cracks or loose parts, and measuring progress. Yet in real life, cameras sit far from the action, shake in the wind, or work at night under harsh spotlights. The result is often grainy, low‑resolution pictures where tiny but crucial details disappear. Existing image‑enhancement methods can sharpen these views, but they tend to face a trade‑off: some are fast but leave images smeared or artificial; others create sharp pictures but are too slow for real‑time video, especially in crowded, complex scenes filled with scaffolding, cranes, and overlapping objects.
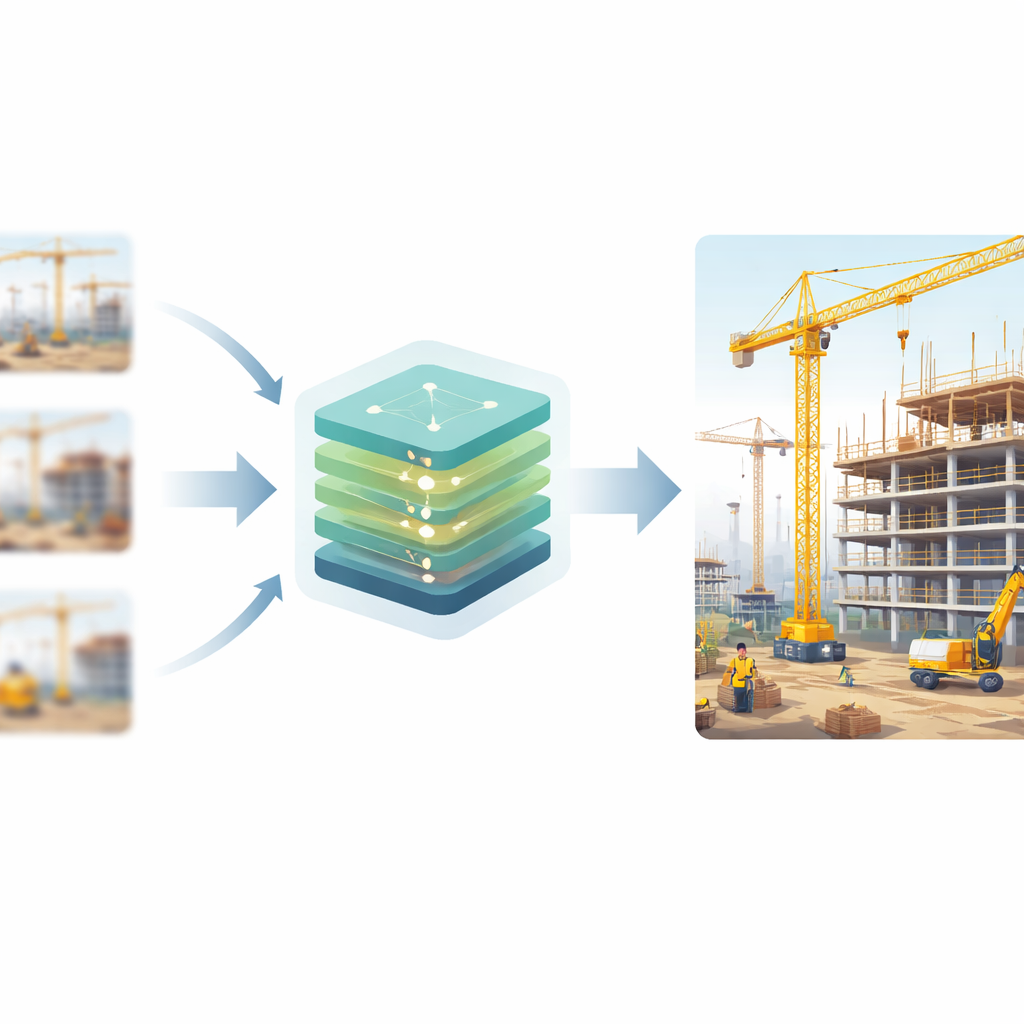
A Smarter Way to Recover Detail
The authors design a new image‑enhancement system that sits between the camera and the monitoring applications. It is based on a class of artificial intelligence models called generative adversarial networks, where one network tries to create realistic high‑resolution images and another network learns to tell real images from fake ones. Through this competition, the creator network learns to add lifelike detail rather than just smooth out rough edges. To better handle construction scenes, the model first looks at each blurry image at several scales at once, using different‑sized filters to capture both broad layouts, such as the outline of a tower crane, and fine elements, like the bars of a safety fence. This multi‑scale "front end" ensures that small objects are not lost when the system begins its deeper processing.
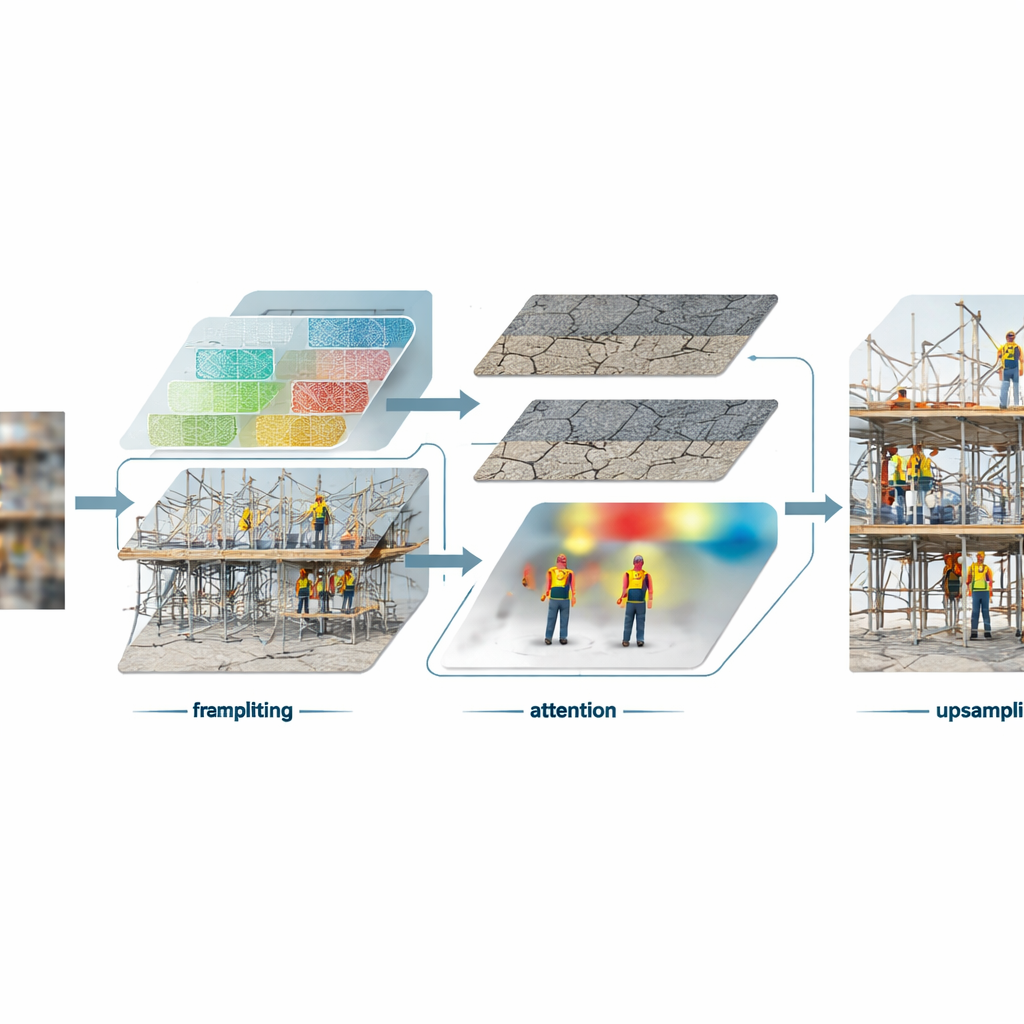
Focusing on What Matters Most
Inside the core of the model, the authors introduce a new building block that treats different kinds of visual information in different ways. Smooth areas such as sky, walls, or road surfaces are separated from sharp structures like scaffolding joints, cable edges, and crack patterns. The system processes these two streams at different resolutions, saving effort on simple regions and spending more computing power on fine detail. At the same time, an attention mechanism learns to highlight the most informative parts of a scene—places where important structures or safety‑related items appear—while downplaying redundant background clutter. Another component subtly adjusts the processing based on earlier clues from the image, so that regions containing workers, materials, or equipment can receive customized treatment that preserves their characteristic shapes and textures.
Judging Realism with a New Critic
To decide whether the enhanced images truly look like genuine high‑resolution photos, the system uses a modern "critic" network that examines both small local patches and the wider scene layout. This critic is built from a transformer architecture originally developed for vision tasks, which breaks images into patches and studies how they relate to each other across the frame. During training, the generator tries to fool this critic, while the critic keeps raising its standards. In addition to this realism test, the training process also includes measures that encourage pixel‑accurate reconstruction and similarity to how humans perceive image quality, striking a balance between crisp edges, natural textures, and faithful overall structure.
Tested on Real Construction Scenes
The researchers trained and tested their method on a large public dataset of real construction sites, with tens of thousands of high‑quality images covering workers, machinery, materials, and site layouts under different weather and lighting conditions. They artificially blurred and shrank these images to create low‑resolution inputs, then asked the model to reconstruct the originals at four times the resolution. Compared with several leading enhancement techniques, the new approach produced clearer text on signs, more natural wood grain, sharper crane hooks, and better structural edges, even in dark or noisy scenes. It also generalized well to other types of images, such as natural scenes and urban buildings, suggesting that the design is broadly useful beyond construction.
Clearer Images, Safer Sites
From a practical standpoint, the most striking result is that this system achieves both high visual quality and real‑time speed: it can process video at about 32 frames per second on a common graphics card, enough for live monitoring. That means existing camera setups on construction sites could, in principle, gain a virtual "zoom" that reveals tiny details without changing the hardware. Clearer images can feed downstream tools for helmet detection, crack inspection, or behavior analysis, making automated oversight more reliable. In simple terms, the paper shows how to give digital watchers on construction sites much sharper eyes—seeing more, faster, and in tougher conditions—without slowing down the flow of information.
Citation: Chen, Q., Hou, G., Wang, D. et al. Research on super-resolution reconstruction of construction images based on attention mechanism and generative adversarial networks. Sci Rep 16, 9449 (2026). https://doi.org/10.1038/s41598-026-40613-4
Keywords: image super resolution, construction site monitoring, computer vision, generative adversarial networks, safety inspection