Clear Sky Science · en
Exact feature collisions in neural networks
When Different Images Fool a Smart Machine
Modern artificial intelligence systems can recognize faces, read medical scans, and guide self-driving cars. We already know they can be tricked by tiny, carefully crafted changes to an image. This paper shows something even more surprising: the very same networks can be blind to huge, obvious changes, treating very different images as if they were the same. Understanding how and why this happens is crucial if we want AI systems we can truly trust.
From Tiny Tweaks to Big Blind Spots
Deep neural networks power today’s breakthroughs in vision, language, and many other fields. Earlier research on adversarial examples revealed that a barely visible change to an image can make a network misclassify it with high confidence. More recent work uncovered the opposite problem: some networks hardly react to large, obvious changes, and still produce almost identical predictions. In those cases, the internal features extracted from two very different images “collide,” meaning the network represents them in nearly the same way. This study takes that idea much further, proving that common networks do not just have approximate collisions but can have exact feature collisions, where two distinct inputs are mapped to precisely the same internal signals.
How Collisions Arise Inside a Network
To explain these collisions, the authors look under the hood of neural networks and focus on their weight matrices, the trained numbers that connect one layer to the next. A feature collision occurs when two different inputs produce the same output at some layer; once that happens, all later layers also see the same thing and therefore cannot tell the inputs apart. Mathematically, this happens when the difference between two inputs lies in the “null space” of a layer’s weights: directions in input space that the layer completely ignores. The authors show that whenever a weight matrix has a zero eigenvalue or maps from a higher-dimensional space to a lower-dimensional one, such ignored directions must exist. Because most real-world architectures, including popular models for classification, segmentation, and object detection, use many such layers, collisions are not rare edge cases but an almost inevitable property of these networks.
A New Way to Build Colliding Inputs
Building on this insight, the paper introduces a practical recipe called the null-space search. Instead of relying on trial-and-error or gradient-based tricks, this method directly uses the null space of the first weight matrix. Starting from any image, the authors compute a vector that the first layer ignores, then add a scaled version of this vector to the image. Because that direction is invisible to the layer, the network’s internal features—and final prediction—remain exactly the same, even if the image itself looks heavily distorted to a human observer. The same idea extends to convolutional layers and, in principle, to later layers as well. The authors survey many standard models and find that most have plenty of such ignored directions, meaning that countless colliding images can be generated in this way for a wide range of tasks.
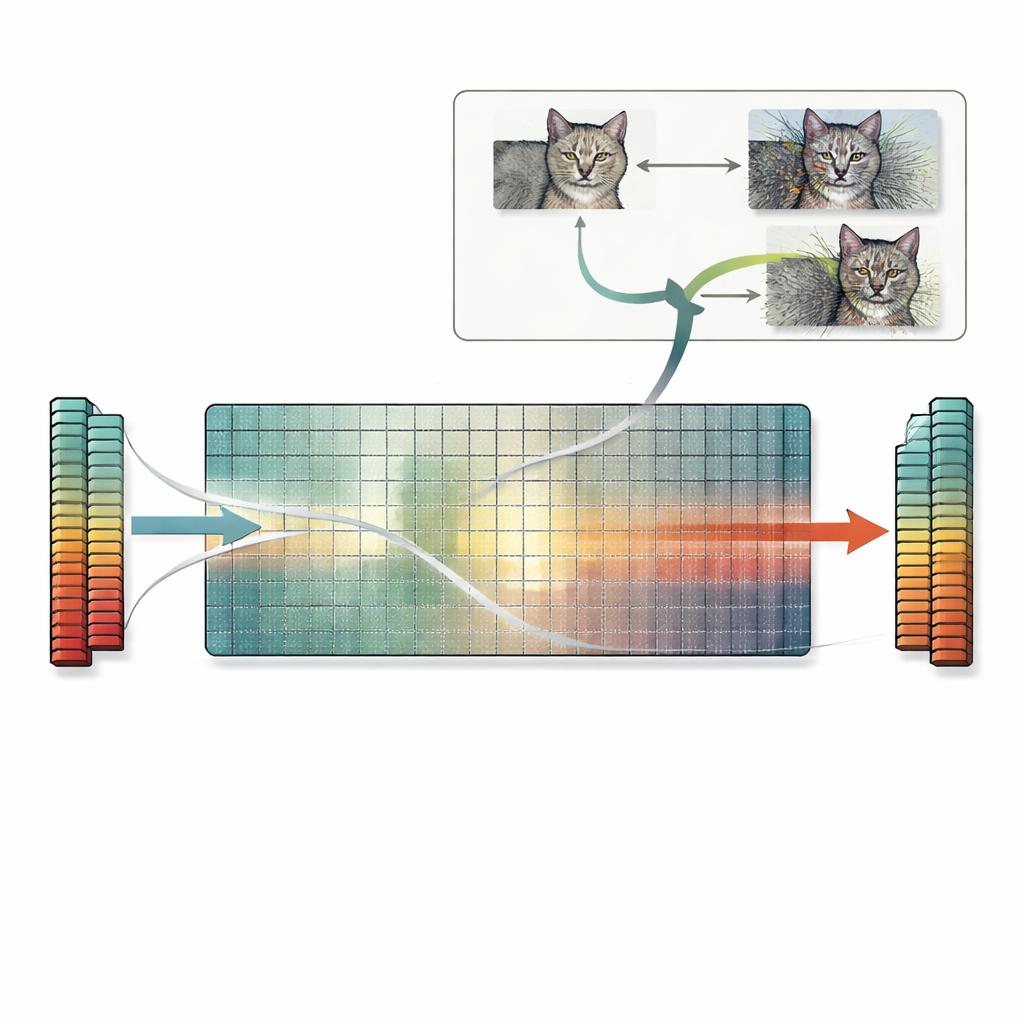
Hidden Risks for Similarity, Explanations, and Security
These exact feature collisions have far-reaching consequences. Two images with colliding features will not only share the same prediction, they will often also share the same explanation maps produced by popular interpretability tools. That can make an unrecognizable, heavily perturbed image appear just as well supported as a clean one, undermining trust in explanation methods. The problem also affects feature-based similarity measures that rely on neural networks: such metrics may judge a heavily corrupted image as “identical” to the original because the features match exactly, even though simple pixel-based scores correctly flag large differences. Finally, the null-space search can be combined with standard adversarial attacks, producing many different adversarial images that all yield the same wrong prediction and stay within standard perturbation limits, deepening existing security concerns.
What This Means for Building Safer AI
In plain terms, this work shows that today’s neural networks often throw away information in predictable ways, leaving entire directions in input space that do not affect their decisions at all. Attackers can exploit these blind spots to create bizarre or adversarial images that a network treats as identical to normal ones. The authors suggest using simple counts of these ignored directions as a way to gauge how vulnerable a model might be, and argue that slimmer, better-regularized networks with smaller null spaces could be more robust. While much remains to be tested in practice, the central message is clear: if we want reliable AI, we must pay attention not only to what networks respond to, but also to what they ignore.
Citation: Ozbulak, U., Rao, S., De Neve, W. et al. Exact feature collisions in neural networks. Sci Rep 16, 10139 (2026). https://doi.org/10.1038/s41598-026-40605-4
Keywords: neural networks, adversarial examples, feature collisions, model robustness, null-space search