Clear Sky Science · en
CMT-Unet: leveraging stage-wise hybrid framework for enhanced accuracy and efficiency in medical image segmentation
Sharper Views Inside the Body
Modern medicine relies heavily on scans such as CT and MRI to see inside the body, but turning these hazy grayscale images into clean outlines of organs and tissues is still a challenge. Doctors need precise boundaries to plan surgeries, track heart function, or measure how a tumor responds to treatment. This paper introduces a new computer vision approach, called CMT-Unet, designed to draw those boundaries more accurately and more efficiently, bringing automated image analysis a step closer to everyday clinical use.
Why Image Outlines Matter
Before an operation or a complex treatment, clinicians often need a pixel-level map of organs or structures in a scan—a process known as segmentation. Traditionally, experts would outline these regions by hand, a time-consuming and tiring task prone to variation between observers. Over the past decade, deep learning methods have taken over much of this work, especially models based on convolutional neural networks and Transformer-style attention mechanisms. Convolutional models excel at picking up fine local details such as edges, while Transformers are particularly good at capturing broader context across the entire image. However, each comes with trade-offs: convolutions can miss long-range relationships, while Transformers often demand hefty computing power and memory.
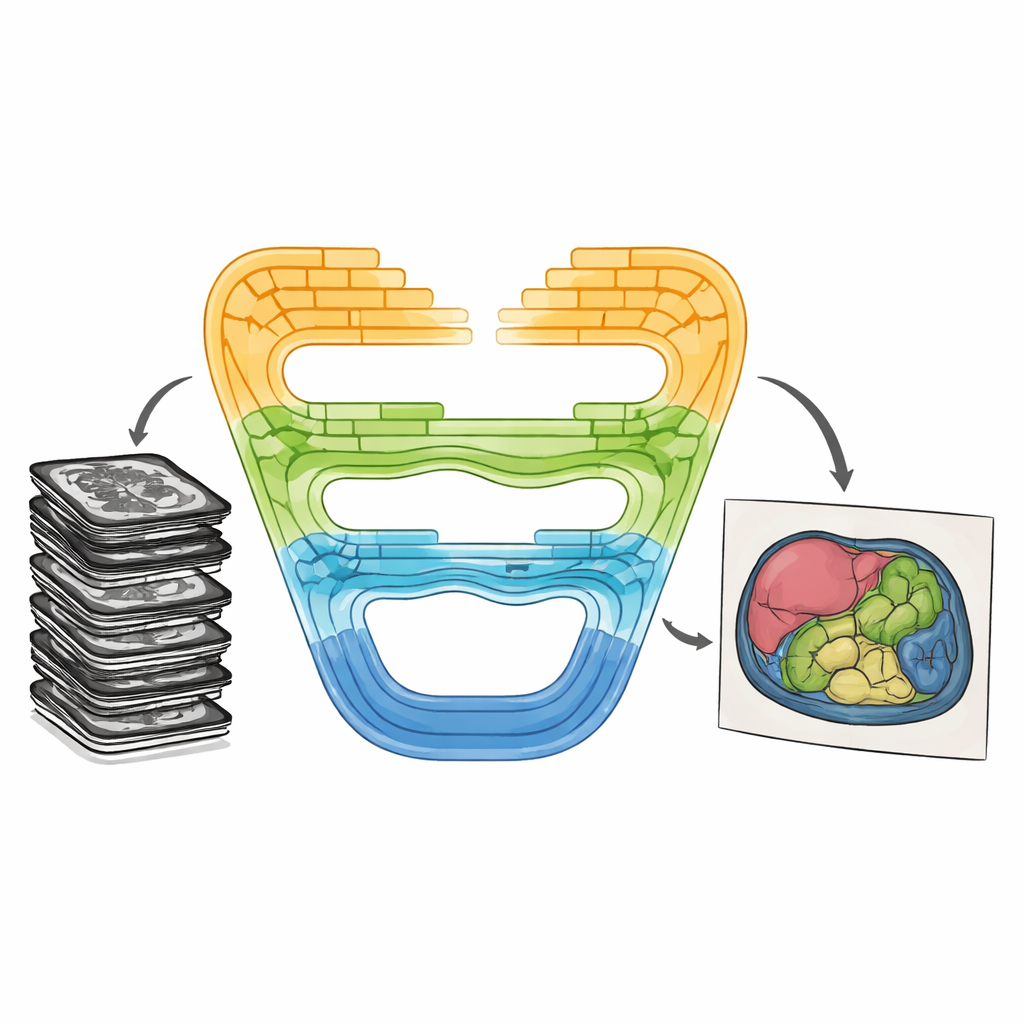
Combining Strengths in a New Way
CMT-Unet tackles these trade-offs by weaving together three kinds of building blocks in a stage-wise fashion, instead of relying on a single type throughout the network. At the front of the system, an inverted residual convolutional unit quickly learns local patterns—sharp borders and textures that help distinguish neighboring tissues. In the middle stages, a module based on so-called state space models, adapted from a recent architecture named Mamba, passes information along sequences of image features in a way that is both context-aware and computationally lean. Deeper in the network, Transformer blocks enhanced with HiLo attention split the information into high-frequency and low-frequency components, allowing the model to capture both tiny details and broad organ shapes before stitching them back together. This layered design mirrors the natural progression from raw pixels to abstract meaning as images are processed.
How the New Model Works Under the Hood
In practice, CMT-Unet follows the familiar U-shaped layout popular in medical imaging: an encoder that compresses information into richer features, a decoder that rebuilds a full-size prediction, and skip connections that pass along spatial detail. The key difference lies in which modules are used at each depth. The early convolutional unit handles the fine-grained structure that the Mamba and Transformer components might otherwise blur. The modified MambaVision block then improves mid-range context by mixing spatial information through specially designed two-dimensional operations, avoiding the heavy cost of full attention while still seeing beyond local patches. HiLo attention in the Transformer stage explicitly separates sharp edges from smooth background patterns, combining them in a way that preserves boundaries. Finally, a dual upsampling module in the decoder helps reconstruct clean, continuous contours while reducing common artifacts such as checkerboard patterns.
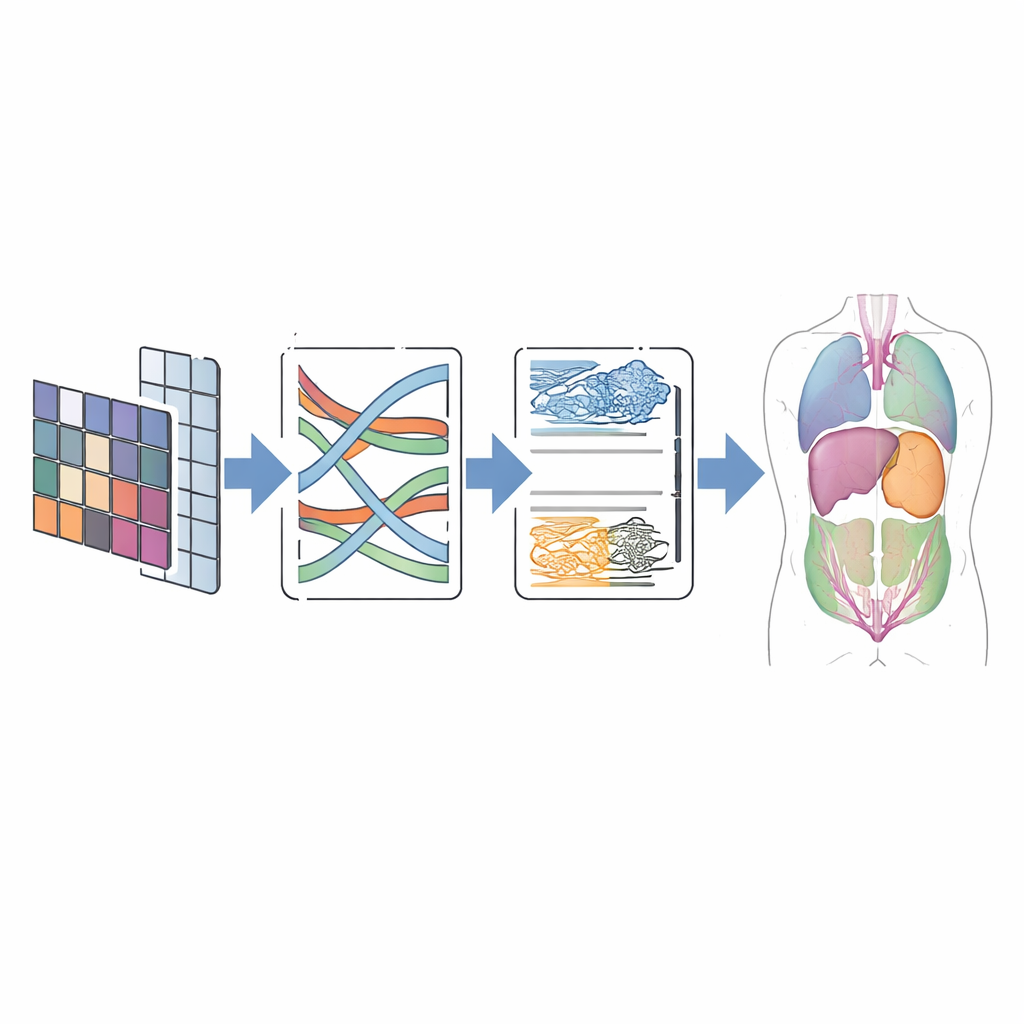
Testing on Real-world Scans
To judge whether this design pays off, the authors tested CMT-Unet on two widely used public datasets. The first, called Synapse, contains abdominal CT scans with eight labeled organs, including the liver, kidneys, and stomach. The second, ACDC, includes cardiac MRI images with labels for the heart’s ventricles and muscle wall. Across these benchmarks, CMT-Unet achieved segmentation scores on par with or better than leading convolutional, Transformer, and hybrid models, while using a moderate number of parameters and a manageable amount of computation. Visual comparisons showed smoother and more anatomically consistent boundaries, especially around challenging regions like the heart’s chambers, which are crucial for measuring function and planning intervention.
What This Means for Patients and Clinics
For non-specialists, the main takeaway is that CMT-Unet offers a smarter way to trace structures in medical images by carefully matching the right tool to the right stage of processing. By balancing local detail and global context, the model can produce accurate, clean organ outlines without demanding supercomputer-level resources. While the current work focuses on two-dimensional scans and a limited set of public datasets, the approach is promising for future extensions to three-dimensional imaging and broader clinical settings. If validated further, this kind of lightweight yet precise segmentation could support faster diagnoses, more reliable treatment planning, and real-time guidance in busy hospital environments.
Citation: Wang, R., Liu, H. & Wang, G. CMT-Unet: leveraging stage-wise hybrid framework for enhanced accuracy and efficiency in medical image segmentation. Sci Rep 16, 10079 (2026). https://doi.org/10.1038/s41598-026-40572-w
Keywords: medical image segmentation, deep learning, hybrid neural networks, state space models, medical imaging