Clear Sky Science · en
Addressing the balance between fairness and performance in glioma grade prediction using bias mitigation techniques
Why treating tumors fairly matters
When doctors use artificial intelligence to help diagnose brain tumors, we might assume the computer is neutral. But if the data used to train these tools reflect existing health inequalities, the software can quietly treat some patients less fairly than others. This study looks at how machine-learning systems that predict the severity of gliomas—a common type of adult brain tumor—can unintentionally favor certain racial or gender groups, and tests practical ways to make those predictions fairer without sacrificing too much accuracy. 
Brain tumors and computer helpers
Gliomas are brain tumors that range from slower-growing, more treatable forms to very aggressive cancers with poor survival. Correctly grading these tumors is vital, because it guides surgery, radiation, and drug treatment. The researchers worked with a public dataset of 839 adults with either low-grade glioma or aggressive glioblastoma. For each patient they had age, gender, race, and 20 common genetic markers in the tumor. They trained three standard prediction models—logistic regression, random forests, and gradient boosting—to tell the two tumor grades apart using these features, then checked both how accurate the models were overall and how well they treated different groups of patients.
Looking for hidden imbalance
To probe fairness, the team focused on two “protected” traits: race (White vs. non-White) and gender (male vs. female). The dataset itself was skewed—more than 90 percent of patients were White, and there were noticeably more men than women. The authors used group-level fairness measures that compare how often different groups receive a correct “high-grade” prediction, and how often the model makes mistakes for each group. All three models were quite accurate overall, with logistic regression performing best. But beneath that success, the fairness checks revealed that non-White patients generally had worse results than White patients, especially in correctly identifying the less aggressive tumors. In contrast, performance for men and women was much more balanced, with only small differences between genders.
Trying to fix the bias
The researchers then asked whether they could improve fairness without seriously weakening the model’s medical usefulness. They chose logistic regression as the base model, since it was both the most accurate and the fairest of the three. They tried two common debiasing strategies. A “pre-processing” approach called reweighting gave extra importance to under-represented patients during training, so the model would pay more attention to them. A “post-processing” approach called equalized odds kept the trained model but adjusted its outputs so that error rates became more similar across groups. 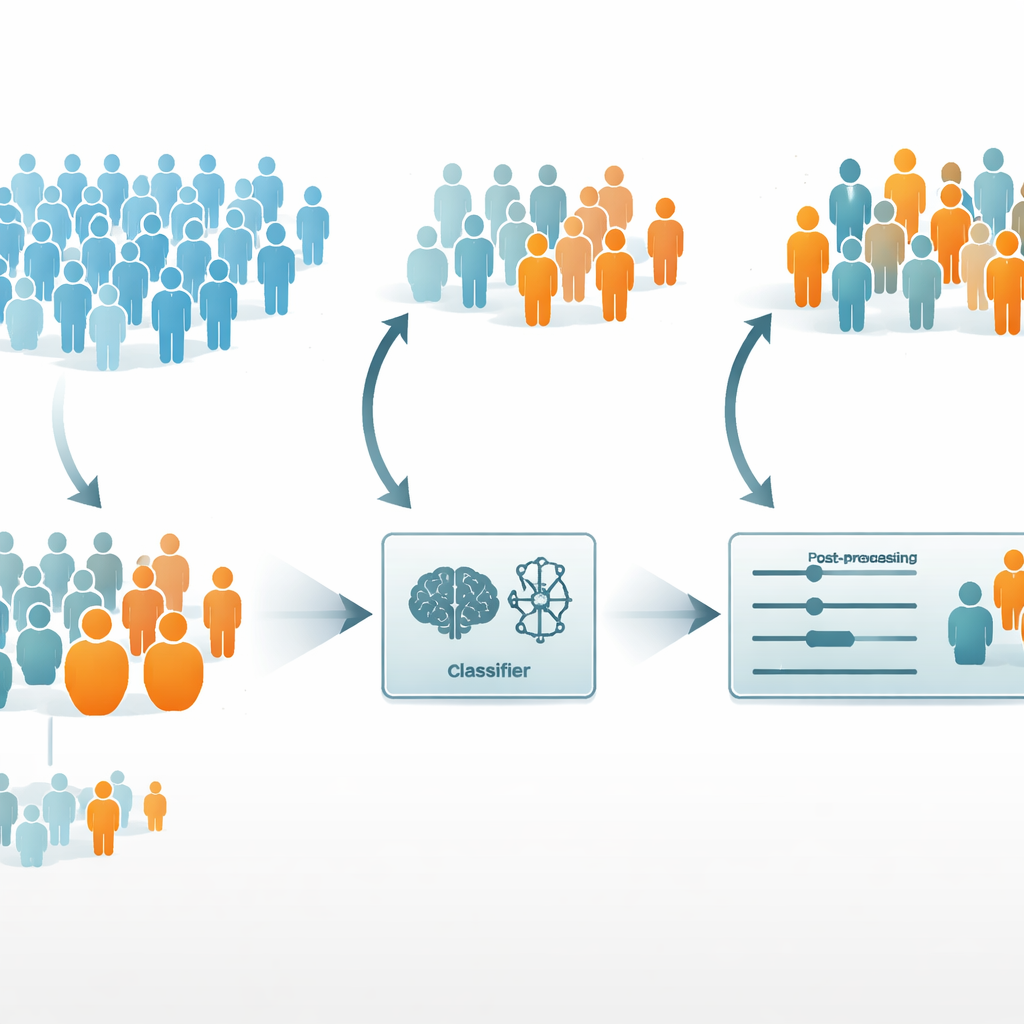
What changed when the model was adjusted
For gender, both strategies generally helped: prediction quality for women improved, and differences between men and women largely shrank. For race, where the imbalance in the data was much stronger, the picture was more complicated. Reweighting sometimes backfired, slightly worsening performance for non-White patients and even increasing unfairness according to some measures. In contrast, the post-processing method substantially reduced racial gaps in error rates while keeping the model’s overall accuracy high, although it did slightly lower performance for the majority group. The authors also showed that fairness numbers for the much smaller non-White group are statistically unstable—changing just one person’s prediction can noticeably shift the fairness scores—so those results must be interpreted cautiously.
What this means for patients and doctors
The study concludes that there is no free lunch: improving fairness in medical AI often involves trade-offs in performance, and the best fix depends on how skewed the data are and which fairness goal is prioritized. In this brain tumor example, tweaking the model’s outputs after training was the most practical way to make treatment recommendations more even-handed across race and gender, while preserving strong predictive power. The work highlights that fairness checks should be routine when deploying AI in healthcare, especially for serious conditions like glioma, and that methods exist to make these tools fairer—but they must be chosen and interpreted with care.
Citation: Sánchez-Marqués, R., García, V. & Sánchez, J.S. Addressing the balance between fairness and performance in glioma grade prediction using bias mitigation techniques. Sci Rep 16, 9785 (2026). https://doi.org/10.1038/s41598-026-40555-x
Keywords: glioma grading, medical AI fairness, algorithmic bias, brain tumors, bias mitigation