Clear Sky Science · en
Source camera attribution using a rule-based explainable convolutional neural network
Why your photos can tell more than you think
Every photo you take carries hidden clues about the camera that captured it. For digital investigators, these clues can help confirm whether an image is genuine, trace which device it came from, or link photos across different crime scenes. Today, powerful artificial intelligence (AI) tools can spot these patterns better than humans—but they often work as mysterious “black boxes.” This paper presents a way to open that box: a rule-based method that explains how a deep-learning model decides which camera took a picture, in a form that a human examiner can understand and trust.
The challenge of trusting smart forensic tools
Modern digital forensics has to sift through huge volumes of data—from smartphones, cloud backups, and social media—far beyond what human analysts can inspect manually. Deep-learning systems can quickly flag images or suggest which ones are important, but their inner workings are notoriously opaque. In sensitive settings like courtrooms, simply saying “the neural network thinks so” is not enough. Existing explanation tools usually highlight image regions the model found important, which is helpful for tasks like recognizing faces or objects. However, for source camera identification, the crucial signal is not a visible feature but a faint sensor fingerprint—subtle noise patterns that people cannot see. As a result, today’s visual explanation tools do not clearly show why a model thinks an image came from a specific camera, nor do they help examiners spot when the model is wrong.
A new way to watch a neural network think
The authors introduce xDFAI, a framework designed specifically for digital forensics that explains how a convolutional neural network (CNN) arrives at its decisions without changing the original model. Instead of treating the network as a single opaque box, xDFAI looks inside layer by layer. For each layer and each camera class, it identifies a set of recurring internal patterns, called “traces,” that consistently light up when the model believes an image belongs to that camera. These traces are extracted from a trained model using existing attribution methods, then filtered to keep only those patterns that appear reliably across many training images. Together, these traces form a structured map of how clues about camera identity evolve as the image flows through the network.
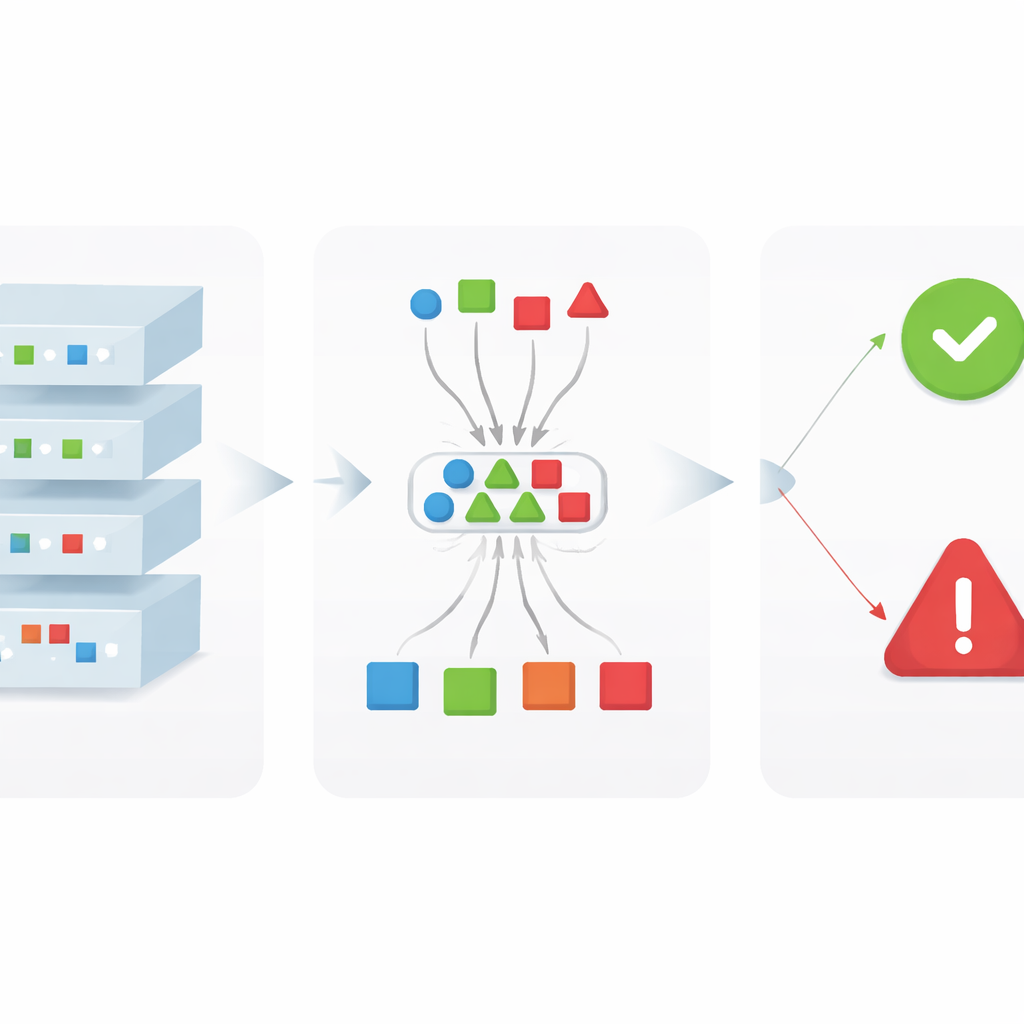
Letting the layers vote and turning votes into rules
Once the traces are known, xDFAI uses them to examine new, unseen images. For a given test photo, the framework measures how similar its internal activations are to the stored traces for each camera at each layer. Each layer effectively casts votes for the camera models whose traces it most closely matches. A cross-layer “majority vote” then summarizes how strongly the network, as a whole, supports each candidate camera. Crucially, the authors do not use this vote to replace the model’s prediction; instead, they use it as a check. Simple logical rules compare the majority vote with the original prediction: if the predicted camera also receives strong support from many layers, the decision is confirmed; if votes are scattered or favor a different camera, the behavior is flagged as abnormal and shown to the examiner as a potential model error.
Putting the framework to the test
To demonstrate xDFAI, the authors apply it to a seven-layer CNN trained to identify which of 27 camera models captured an image, using a well-known forensic dataset. The base CNN alone already performs very well, correctly classifying about 97% of test images. When xDFAI’s rules are applied on top, the system automatically flags 27 of the 37 wrong predictions as suspicious. Those flagged cases are no longer counted as confident identifications, which raises the precision—the fraction of accepted decisions that are actually correct—from 97.33% to 99.2%, while only slightly reducing overall accuracy. For forensic work, where a single wrong attribution can have serious consequences, this trade-off is highly desirable: fewer false alarms among the conclusions that analysts choose to trust.
What this means for real-world investigations
This work shows that it is possible to keep the full power of a modern deep-learning model while adding human-friendly explanations that respect forensic integrity rules—no retraining, no tampering with the original model, and no reliance on vague heat maps alone. By exposing stable internal traces, aggregating them through a transparent voting scheme, and expressing the outcome as simple rules, xDFAI gives examiners a way to confirm or question AI-generated camera attributions. Although the study focuses on camera source identification, the same ideas could be extended to other forensic attribution tasks. In the long run, approaches like this may help bridge the gap between highly accurate AI systems and the level of transparency and reliability required in courts and investigative practice.
Citation: Nayerifard, T., Amintoosi, H. & Ghaemi Bafghi, A. Source camera attribution using a rule-based explainable convolutional neural network. Sci Rep 16, 9137 (2026). https://doi.org/10.1038/s41598-026-40387-9
Keywords: digital forensics, explainable AI, camera identification, convolutional neural networks, image forensics