Clear Sky Science · en
MedicalPatchNet: a patch-based self-explainable AI architecture for chest X-ray classification
Why smarter X-rays matter
Chest X-rays are one of the most common medical tests in the world, and artificial intelligence (AI) systems are increasingly helping doctors interpret them. But many of today’s best-performing AI models act like “black boxes”: they may be accurate, yet even experts cannot easily see why they reached a particular diagnosis. This lack of transparency makes it hard for clinicians to trust and safely use AI in real patient care. The study introduces MedicalPatchNet, a new AI approach that aims to keep strong accuracy while making its reasoning visible and understandable, even to people without a background in machine learning.
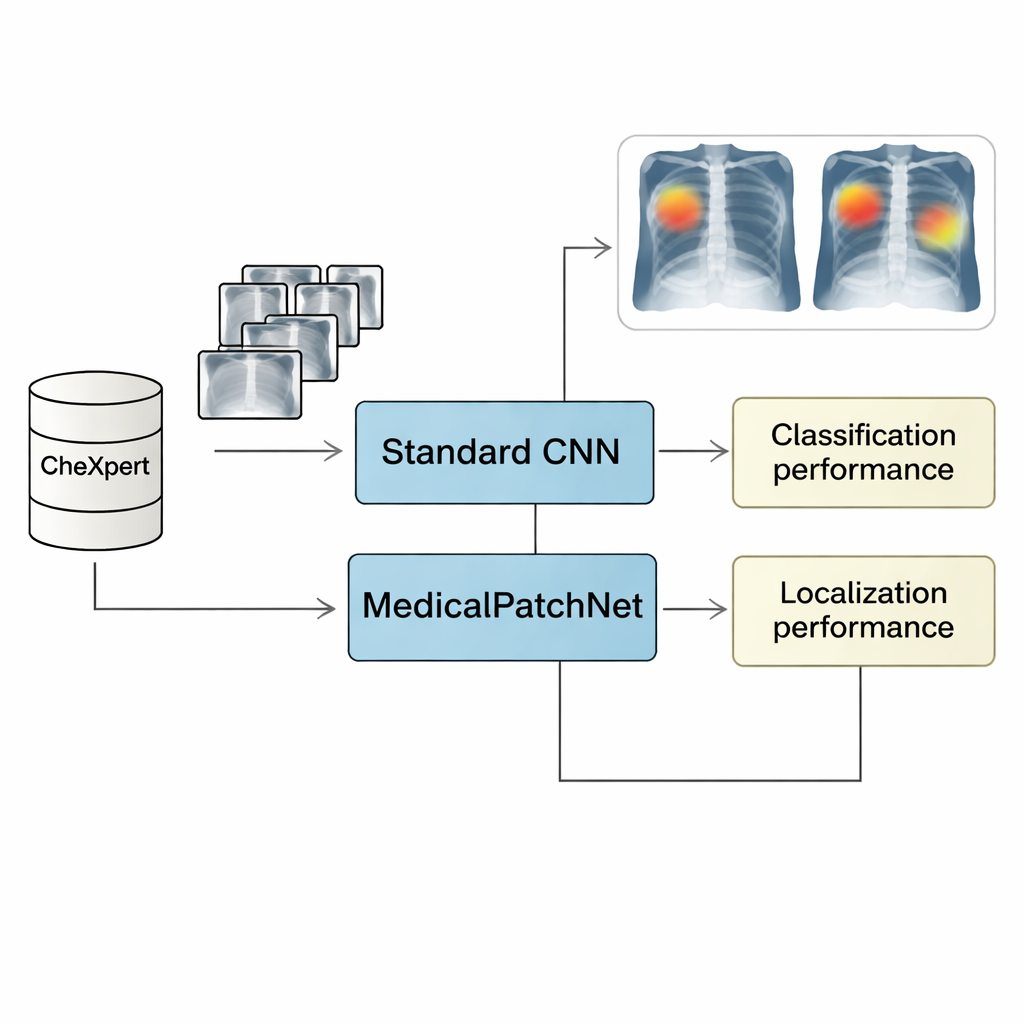
Breaking images into small, meaningful regions
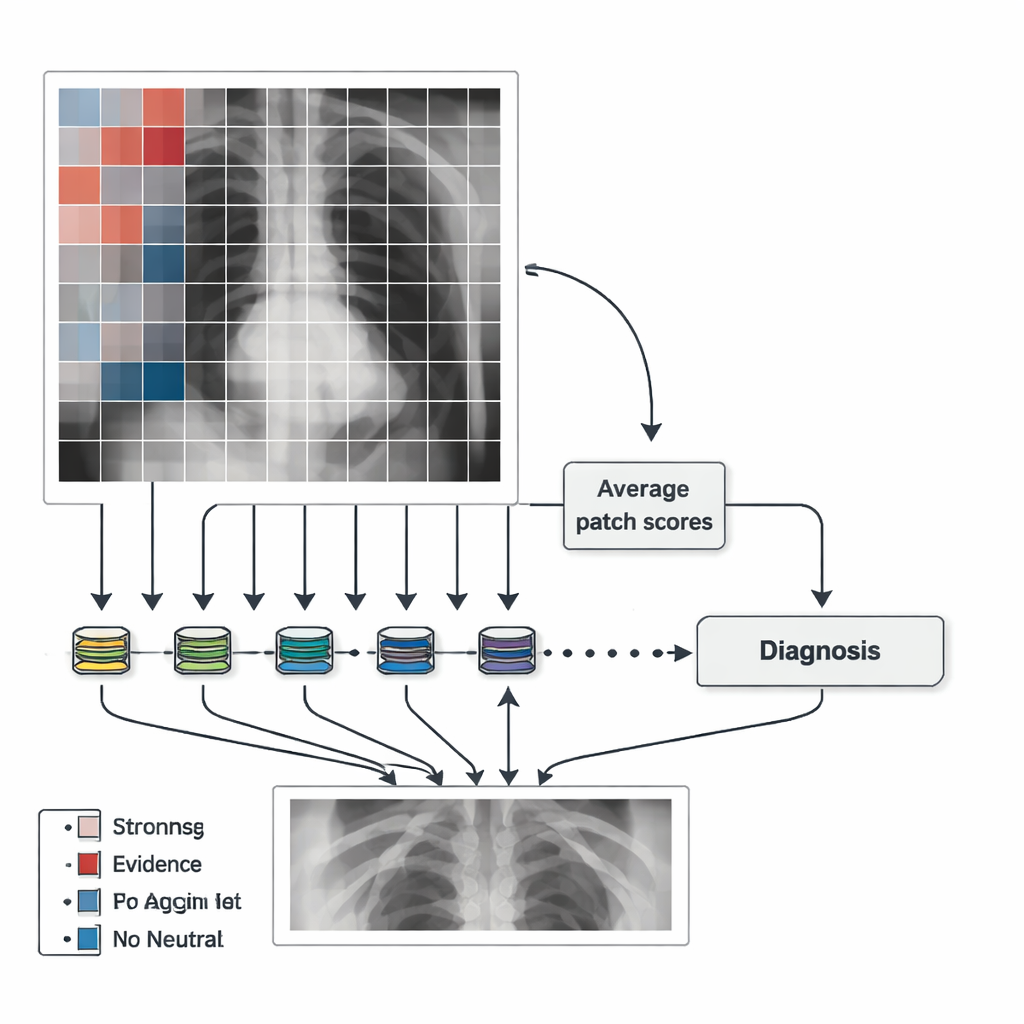
Instead of analyzing a chest X-ray as one large, mysterious whole, MedicalPatchNet works by splitting the image into many small, non-overlapping squares or “patches.” Each patch is sent through the same neural network, which produces a score for several possible findings, such as lung opacity, pneumonia, or pleural effusion (fluid around the lungs). These patch-level scores are then simply averaged to get an overall decision for the entire image. Because the final answer is just the sum of many local votes, it is straightforward to show how much each patch contributed to the diagnosis. Crucially, there are no hidden attention mechanisms or complex internal weighting schemes, so the influence of each region is explicitly defined rather than learned in an opaque way.
Turning model decisions into clear visual maps
The authors use these patch scores to create “saliency maps” that highlight where the AI found evidence for or against a disease. Patches that strongly support a finding are shown in warm colors (for example, red), those against it in cool colors (such as blue), and neutral areas in grey. This makes it easy to see whether the model is focusing on the lungs, the heart, or, worryingly, on irrelevant features like border artifacts or text labels. To make the maps smoother and less blocky, the team also generates maps after slightly shifting the image in many small steps and averaging the results. This adds some computational cost but yields heatmaps that better match the underlying anatomy while still preserving the clear link between each region and its contribution to the final decision.
Matching black-box performance while improving trust
To test MedicalPatchNet, the researchers trained it on CheXpert, a large public dataset of more than 220,000 chest X-rays labeled for 14 common findings. They compared its performance to a strong, conventional image-level model using the same backbone network (EfficientNetV2-S). On average, the two models achieved almost identical diagnostic performance, as measured by the Area Under the Receiver Operating Characteristic curve (AUROC), sensitivity, specificity, and accuracy. In other words, forcing the model to reason patch by patch and then average the results did not meaningfully weaken its ability to recognize disease. This suggests that for many chest X-ray tasks, local image information is sufficient, and there is no need for the model to rely on complex, fully global patterns to perform well.
Seeing where the model “looks” for disease
Beyond overall accuracy, the key question is whether MedicalPatchNet explains itself more reliably than popular “after-the-fact” tools such as Grad-CAM and its variants. For that, the team used a second dataset, CheXlocalize, which provides radiologist-drawn outlines of actual disease regions. They measured how often a method’s most highlighted point fell inside the true abnormal area (the “hit rate”) and how well the highlighted region overlapped with expert annotations (mean Intersection over Union, or mIoU). MedicalPatchNet’s patch-based maps achieved higher hit rates than Grad-CAM-style explanations for nine out of ten conditions, and the best overall overlap when counting both correct and incorrect predictions. This broader evaluation is important because it penalizes explanations that look good only when the model is right but fail to reveal misleading behavior when the model is wrong.
From opaque guesses to transparent partners
For non-specialists, the main outcome is that MedicalPatchNet shows it is possible to keep near–state-of-the-art performance on chest X-ray diagnosis while making the AI’s reasoning much more transparent. Instead of mysterious heatmaps that may or may not reflect what truly drove the decision, this approach ties every highlight directly to a local vote in the model’s calculation. Clinicians can see not just whether the AI thinks a disease is present, but also exactly where in the image it found supporting or contradicting evidence. While the method still has limits—such as difficulty with conditions that depend on distant regions of the image being considered together—it offers a practical path toward AI tools that act less like black boxes and more like clear, accountable partners in medical imaging.
Citation: Wienholt, P., Kuhl, C., Kather, J.N. et al. MedicalPatchNet: a patch-based self-explainable AI architecture for chest X-ray classification. Sci Rep 16, 7467 (2026). https://doi.org/10.1038/s41598-026-40358-0
Keywords: chest X-ray AI, explainable deep learning, MedicalPatchNet, medical image saliency maps, radiology decision support