Clear Sky Science · en
A kNN based machine learning approach to automating causality assessment of adverse events
Why this matters for people taking medicines
When a new medicine reaches the market, its story is just beginning. Millions of people will use it in the real world, and some will experience health problems that might or might not be caused by the drug. Sorting out which reactions are truly drug related is vital for patient safety, but today that work is slow, complex, and largely manual. This study explores how a simple but powerful form of artificial intelligence can help experts review these safety reports faster and more consistently, without replacing the human judgment that ultimately protects patients.
How safety stories become data
Drug companies and regulators rely on individual case safety reports, which are structured summaries of real people’s experiences with medicines. Each report may include what went wrong (for example, a headache or liver problem), how serious it was, what other medicines and illnesses were present, and what the original reviewer thought about the link to the drug. For over 800,000 such reports from six marketed drugs, the company’s medical reviewers had already decided whether each adverse event was related to the drug, not related, or impossible to judge because information was missing or conflicting. The researchers used this rich historical record as training material for a computer model that would learn to mimic those human decisions on new cases.

Teaching a computer to spot similar cases
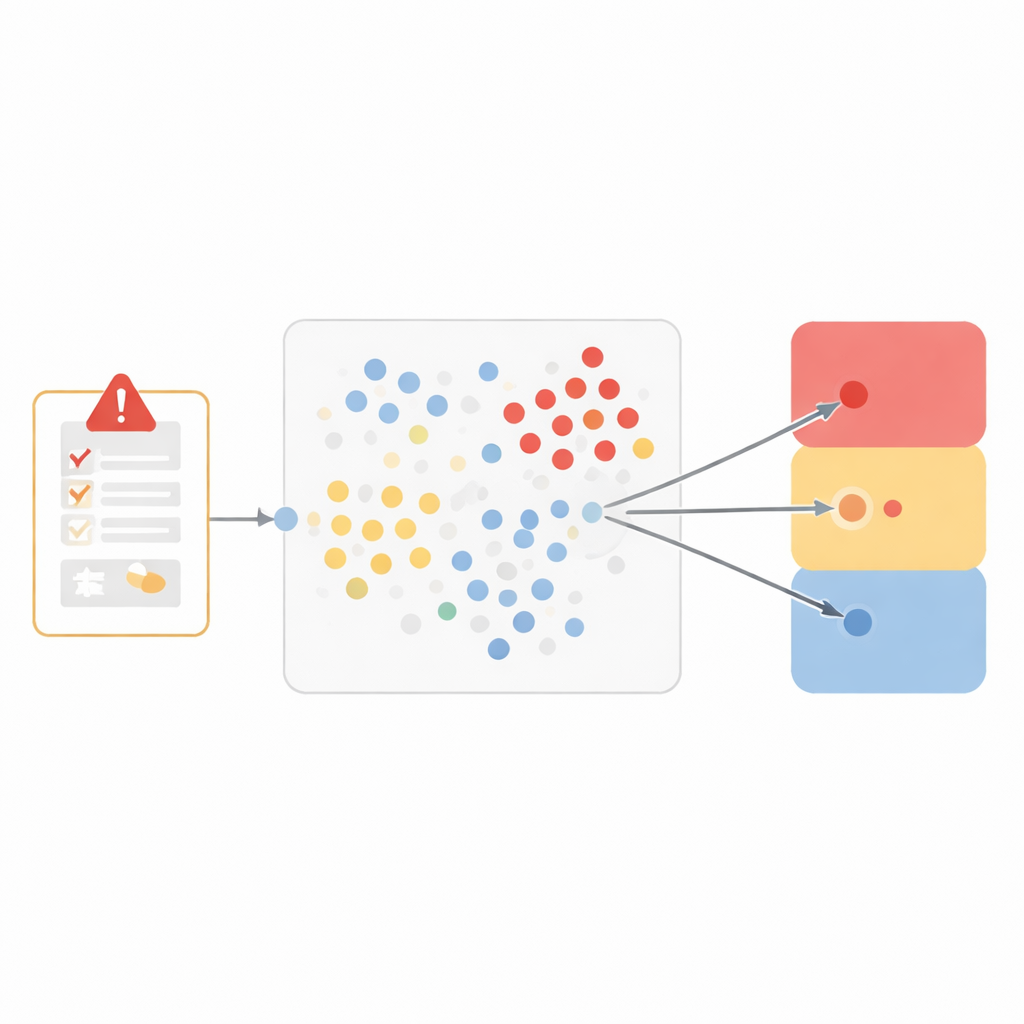
Instead of building a black-box system, the team chose a particularly transparent method called “nearest neighbors.” The idea is intuitive: if two cases look very alike, they probably share the same conclusion about whether the drug caused the problem. To capture similarity, the researchers represented each adverse event as a seven-part profile, including the medical term for the event, what happened when the drug was stopped and restarted, whether the problem was expected for that medicine, the reporter’s opinion, other medicines being taken, medical history, and how serious the event was. They then measured how close any two cases were in this seven-dimensional space, giving more weight to features that matter most for causality, such as the exact event and what happened when treatment changed.
From closeness to a three-way decision
When a new report arrives, the model looks back through the historical data to find the ten most similar cases. It then checks how those neighbors had been classified and lets them “vote” among three broad outcomes: likely related to the drug, not related or unlikely, and unassessable. This three-way grouping strikes a balance between clinical nuance and reliable performance. Tested on more than 250,000 previously unseen events, the model closely matched human reviewers for events considered related and for those judged unassessable, with low error rates and strong scores that combine accuracy and completeness. It struggled more with the smaller group of clearly not-related events, reflecting the challenge machine-learning systems face when one type of example is relatively rare.
Reducing the fog of “cannot tell”
One practical problem in real-world safety work is that the “unassessable” label can become a catch-all when information is thin or ambiguous, which makes it harder to see true safety patterns. The researchers added a tuning tool that makes the model more cautious about assigning this label. Rather than choosing “unassessable” whenever it wins a simple majority among similar cases, the model now requires a higher percentage of neighbors to support that choice. By raising this threshold, the team was able to sharply reduce how often the model called a case unassessable and improve performance for the other two categories, at the cost of some increased disagreement for the hardest-to-judge events. A web-based dashboard lets medical reviewers adjust this threshold by product, instantly see how the balance of outcomes shifts, and focus their attention on cases where the model and humans disagree.
What this means for future drug safety
For a sample of recent cases that human reviewers had labeled unassessable, the system highlighted hundreds where its conclusion differed. When senior reviewers re-examined these, they agreed with the model more than two-thirds of the time, showing that such tools can flag overlooked patterns and support quality oversight rather than replace experts. The work demonstrates that a clear, similarity-based approach can bring artificial intelligence into drug safety in a way that is explainable, tunable, and aligned with medical practice. As more data accumulate and text narratives are added using modern language technologies, systems like this could help ensure that emerging risks are spotted earlier, while keeping clinicians firmly in charge of final judgments.
Citation: Ren, J., Carroll, H., McCarthy, K. et al. A kNN based machine learning approach to automating causality assessment of adverse events. Sci Rep 16, 9140 (2026). https://doi.org/10.1038/s41598-026-40267-2
Keywords: pharmacovigilance, adverse drug events, causality assessment, machine learning, k nearest neighbors