Clear Sky Science · en
KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI
Why making AI smaller can make it greener
Artificial intelligence has a hidden cost: electricity. Training modern machine‑learning models often means crunching through millions of data points on power‑hungry hardware, which in turn produces carbon emissions. This paper introduces KM‑DBSCAN, a new way to shrink datasets before training without throwing away the information models actually need. By keeping only the most informative data, the method speeds up learning, cuts energy use, and still delivers accurate predictions in tasks ranging from handwritten digit recognition to early detection of skin cancer.
Too much data, too much energy
For years, the dominant belief in AI has been that more data almost always leads to better models. While that can improve accuracy, it also means longer training times, bigger computers, and higher electricity bills. Researchers have started to distinguish between "Red AI," which chases accuracy at any cost, and "Green AI," which tries to balance performance with environmental impact. One promising route to greener AI is data reduction: instead of feeding a model every example available, identify a much smaller set of cases that still define the problem well, especially the tricky borderline cases that determine a classifier’s decisions.
Mixing two simple ideas into one smart filter
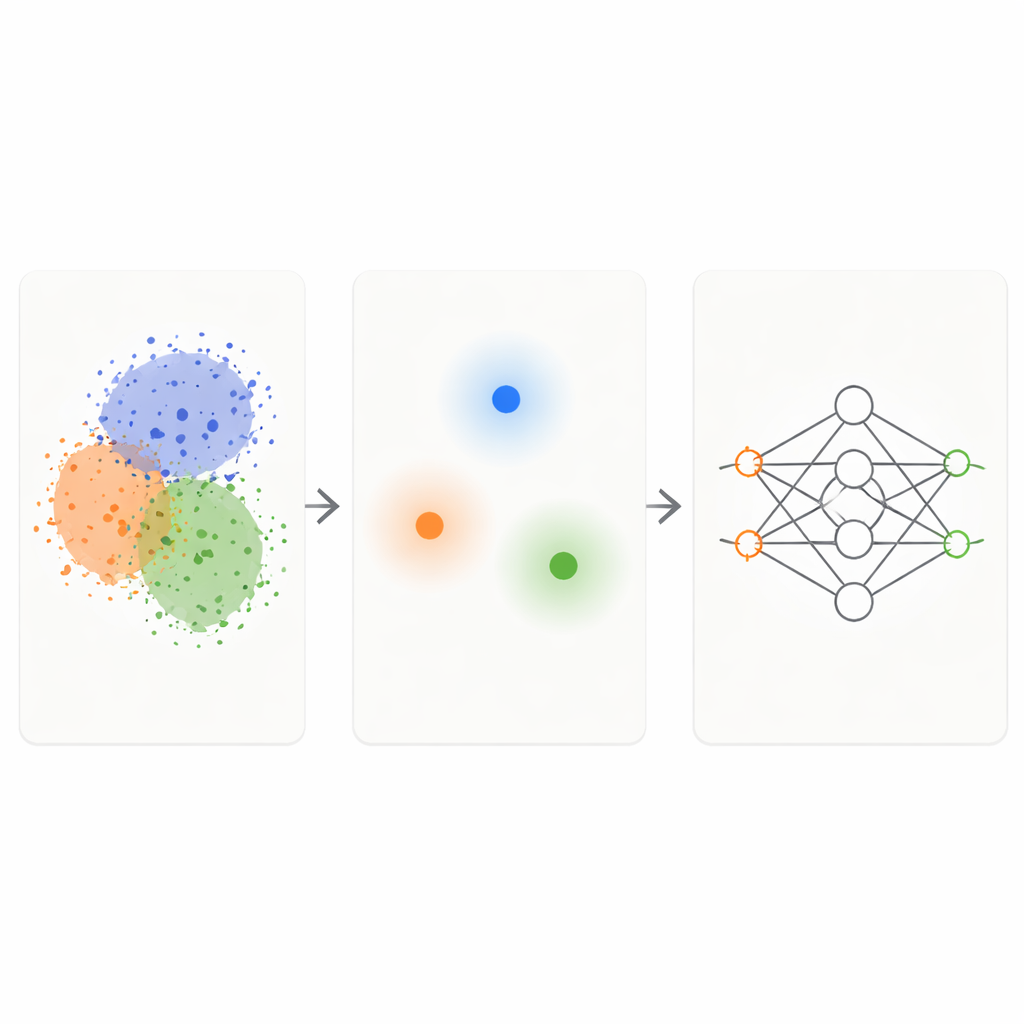
The KM‑DBSCAN framework combines two well‑known clustering techniques to act as an intelligent filter on raw data. First, a fast method called K‑Means groups points into compact clusters and replaces each group with a representative center, or centroid. This shrinks the problem from thousands or millions of points down to a few hundred representative ones. Next, a density‑based method (DBSCAN) is run on those centroids to find which regions lie at the borders between clusters and which are dense, homogeneous interiors or isolated noise. By working at the level of centroids, DBSCAN becomes far faster and less sensitive to fiddly parameter choices than when it is applied directly to all data points.

Keeping only the hard, informative cases
Once KM‑DBSCAN has identified where different groups touch or overlap, it keeps only the data points that sit near these borders and discards both deep interior points and clear outliers. Interior points are largely redundant: they all look similar and send the model the same message about their class. Border points, in contrast, tell the model exactly where one class ends and another begins. On synthetic toy datasets, this strategy reproduces the same decision boundaries that a classifier learns from the full data, even when most points are removed. On real‑world datasets such as Banana, USPS digits, the Adult income dataset, vehicle collision data, dry bean varieties, and melanoma skin images, the reduced sets preserve the key structure of the problem while being an order of magnitude smaller.
Speed, carbon savings, and real applications
The authors tested KM‑DBSCAN as a front‑end to several popular models, including support vector machines, multilayer perceptrons, and convolutional neural networks. In many cases, training on the reduced data was tens to thousands of times faster while maintaining almost the same accuracy—and sometimes even improving it slightly. For example, on handwritten digit recognition, the method cut the training set down to just 1.4% of its original size and still nudged accuracy upward, while making training 284 times faster. In an income‑prediction task with imbalanced classes, it achieved a 6907‑fold speedup using only about 3% of the data with minimal loss in accuracy. In a melanoma‑detection experiment, a deep neural network reached over 90% accuracy while training on less than a third of the original skin‑image dataset, with carbon emissions reduced by more than 70%.
What this means for everyday AI
For non‑specialists, the key message is that smarter selection can beat sheer volume. KM‑DBSCAN shows that carefully choosing which examples a model sees—focusing on the most informative border cases—can slash computing time and energy use while keeping predictions reliable. This approach fits neatly into the broader push for Green AI, where the quality of data and thoughtful design of training pipelines matter as much as raw model size. If adopted widely, such data‑aware filtering could make everything from medical image analysis to traffic‑safety systems more sustainable, bringing powerful AI tools within reach of organizations that lack massive computing resources.
Citation: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
Keywords: green AI, data reduction, clustering, machine learning efficiency, melanoma detection