Clear Sky Science · en
Source signal sparsity enhancement based on local maximum synchronous extraction transform algorithm for mixed matrix estimation in UBSS
Untangling Hidden Signals
Many of the technologies we rely on—wireless networks, radar, medical scanners and even smart microphones—must pick out faint signals that are hopelessly mixed together. Imagine trying to follow several conversations at once in a crowded café using only two ears. This paper presents a new way to "untangle" such overlapping signals when there are fewer sensors than sources, a notoriously hard setting. By sharpening how we look at signals in time and frequency, and by improving how computers group related data, the authors show they can separate mixtures more accurately and more reliably, even in noisy real-world conditions. 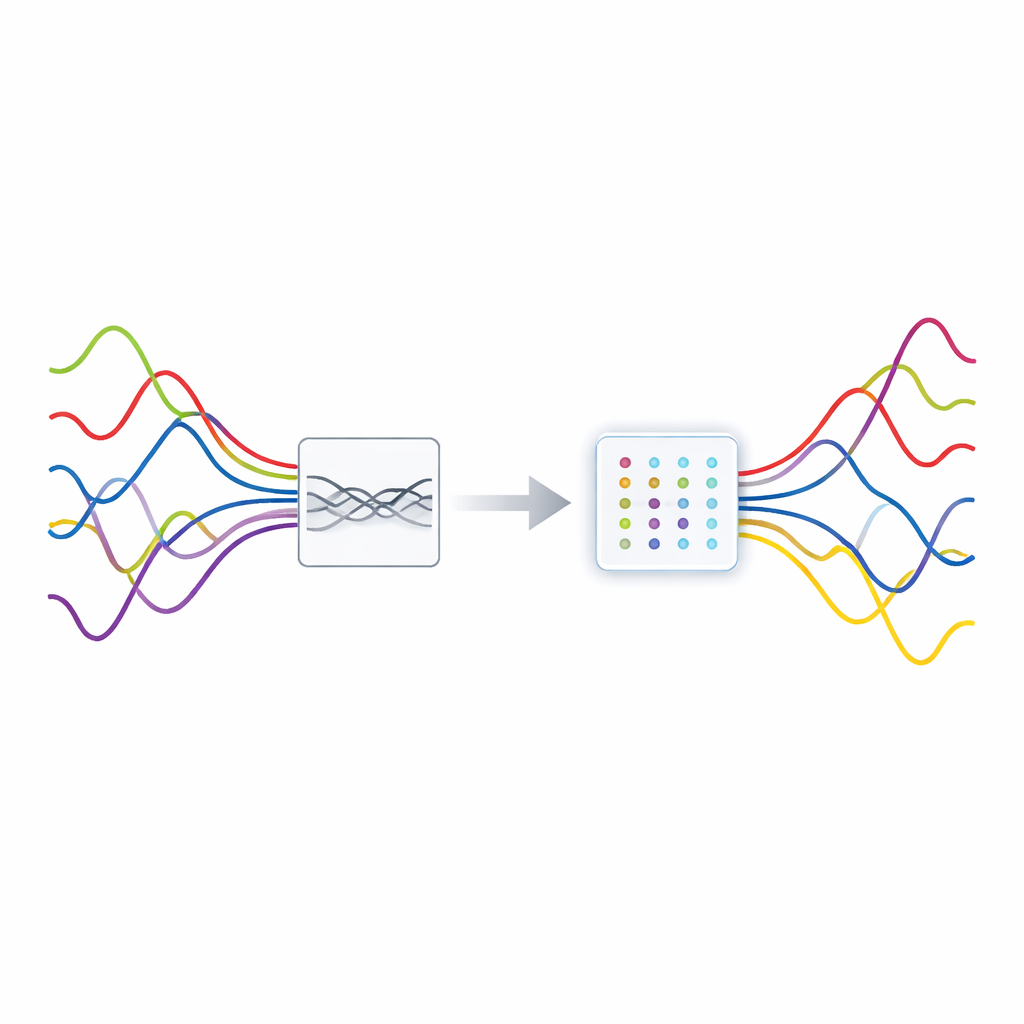
Why Mixed Signals Are So Hard to Separate
In many systems, several independent signals travel through the same channel and are picked up by a small number of receivers. This situation, called underdetermined blind source separation, means there are more unknown signals than measurements. Classic methods for signal separation generally assume the opposite, so they break down here. A key modern trick is to exploit sparsity: in a suitable representation, each source is active only at a few moments or frequencies. If, at most instants, only one source dominates, the cloud of observed data naturally forms clusters whose directions encode how each source mixed into the receivers. Accurately finding these clusters, however, depends on having a representation in which the energy of each source is sharply concentrated rather than smeared out.
Sharpening the Picture of a Signal
To uncover sparsity, engineers often transform signals into a time–frequency picture that shows which tones are present at which instants. The simple short-time Fourier transform does this by sliding a window along time and taking many small spectra, but it blurs energy and cannot simultaneously give sharp timing and precise pitch. More advanced variants such as synchrosqueezing and synchroextracting try to pull spread-out energy toward the ridge that follows a signal’s instantaneous frequency. These methods improve focus, but they remain vulnerable to noise: when random disturbances are compressed along the same ridges as the signal, the result can be a bright but fuzzy band that hides fine structure.
Finding Local Peaks to Boost Sparsity
Building on these ideas, the authors introduce the Local Maximum Synchroextracting Transform, or LMSET. Instead of pushing all nearby energy toward a frequency ridge, LMSET scans the time–frequency plane and, for each instant, locks onto local peaks along the frequency axis. Only coefficients around these local maxima are kept and reassigned, while the rest are suppressed. This simple change yields a representation where the energy of each component signal is concentrated into thin, clean curves with far fewer stray points. Through simulations with multi-component test signals, LMSET produces the lowest Rényi entropy, a standard measure of concentration, outperforming the conventional and state-of-the-art methods over a wide range of noise levels. Put plainly, LMSET produces a clearer picture of where each signal lives in time and frequency.
Smarter Grouping to Learn the Hidden Mixing
A sharper picture is only half the battle; the next step is to cluster the resulting points to estimate the unknown mixing matrix that describes how each source contributes to each receiver. Many approaches rely on fuzzy C-means, a popular clustering method that often gets stuck in poor solutions because it is very sensitive to its starting guess and to outlier data points. To overcome these weaknesses, the authors couple LMSET with a new, more robust clustering scheme. They first use a PID-based search algorithm, inspired by control theory, to explore the full space of possible cluster centers and avoid bad starting positions. They then introduce a Boolean weight mechanism to downplay outliers and employ an information-entropy strategy that reduces sensitivity to initial conditions. Together, these steps allow the clustering to lock onto the true directions of the hidden sources more consistently.
What the Tests Reveal
The authors test their full pipeline—LMSET plus the improved clustering—on mixtures of digitally modulated communication signals, including QAM, QPSK and FSK, in both quiet and noisy environments. They compare the estimated mixing matrices with the true ones using angular error and normalized mean squared error. Across the board, using LMSET instead of a traditional transform reduces errors, because the data points form tighter, more distinct clusters. Among clustering methods, the proposed PID-optimized robust fuzzy C-means achieves the smallest average angular deviations and the best error scores. Overall, the combined method improves the accuracy of mixing matrix estimation by nearly 20 percent relative to conventional approaches, while maintaining strong performance even when noise levels are high. 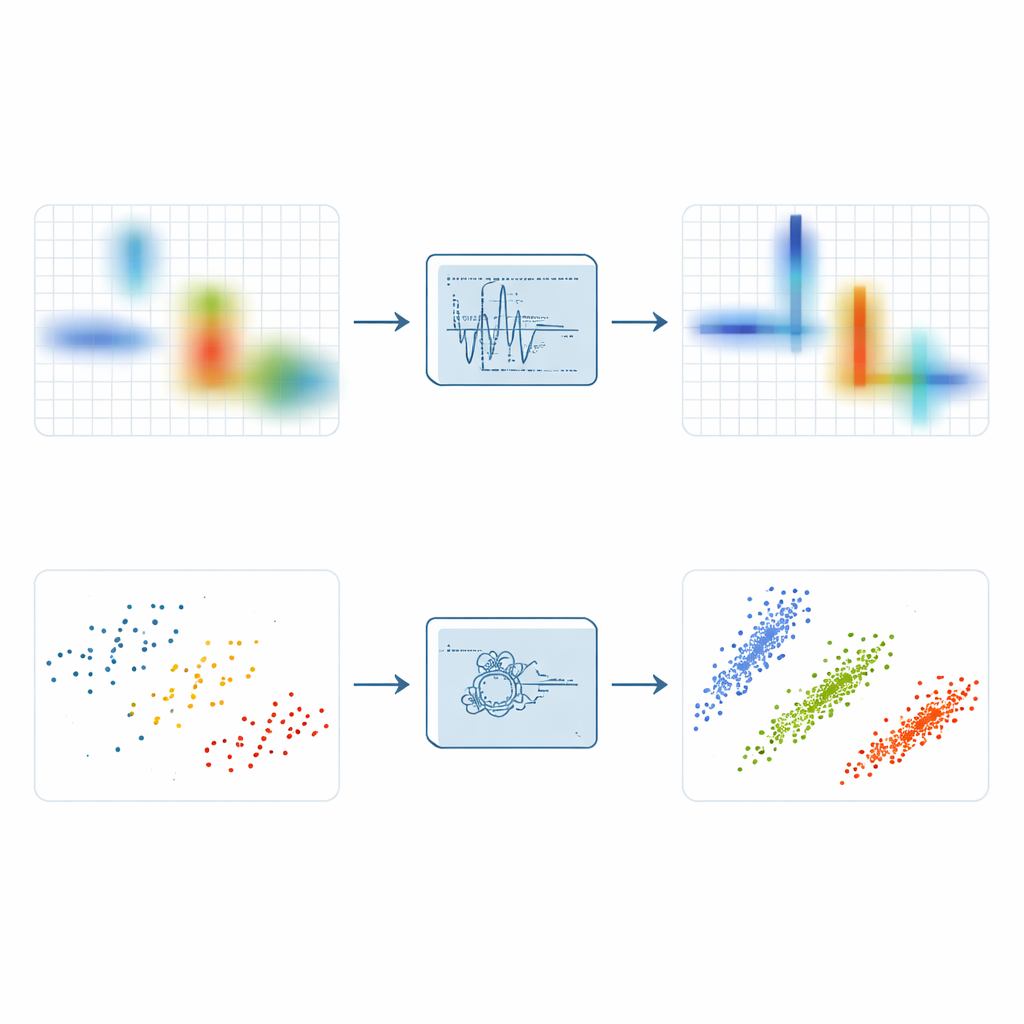
Why This Matters Beyond Theory
For non-specialists, the key takeaway is that the authors have found a better way to look at and group tangled signals so that each original stream can be more cleanly recovered. By homing in on local peaks in the time–frequency landscape and pairing this view with a more careful clustering strategy, their method makes the impossible café problem—many voices, too few ears—a bit more solvable. This advancement could benefit applications ranging from satellite links that must separate overlapping transmissions, to medical systems that need to isolate weak biological signals buried in noise, offering clearer information from the same limited measurements.
Citation: Li, X., Li, Z., Yao, R. et al. Source signal sparsity enhancement based on local maximum synchronous extraction transform algorithm for mixed matrix estimation in UBSS. Sci Rep 16, 9378 (2026). https://doi.org/10.1038/s41598-026-40055-y
Keywords: blind source separation, signal sparsity, time–frequency analysis, clustering algorithms, wireless communications