Clear Sky Science · en
Machine learning for predicting CKD stages in patients with autosomal dominant polycystic kidney disease: a nationwide cohort study in Japan
Why this matters for everyday health
Kidney disease often creeps up silently, and by the time symptoms appear, damage can be hard to reverse. For people born with autosomal dominant polycystic kidney disease (ADPKD) – a condition where fluid‑filled sacs slowly crowd out normal kidney tissue – knowing how fast their kidneys might fail can shape major life decisions. This study explores whether modern computer techniques, known as machine learning, can use routine medical check‑up data to forecast how a person’s kidney function will change over the next three years, without relying on expensive genetic tests or advanced scans.
A common disease with uncertain futures
ADPKD is one of the most frequent inherited kidney disorders and a leading cause of chronic kidney disease (CKD). Many affected people eventually need dialysis or a transplant, but the pace of decline varies widely. Some progress slowly and keep reasonable kidney function into old age; others reach kidney failure by their 40s or 50s. Doctors would like to sort patients into risk groups early, so treatment and monitoring can be tailored. Existing prediction tools often depend on detailed genetic testing or full MRI scans of the kidneys, which are not routinely available in many health systems, including Japan’s national insurance program. That gap motivated the authors to search for a simpler, widely usable way to gauge future CKD stage.
Turning a national registry into a prediction tool
The researchers drew on a nationwide Japanese registry that records information from people with difficult‑to‑treat diseases who receive government support. They focused on 2,737 adults with ADPKD who first registered between 2015 and 2021. For each person, the team collected data from the initial application – including blood test results, urine findings, basic body measurements, blood pressure, and doctor‑recorded kidney size – and then looked at that person’s CKD stage three years later. CKD stage, which is mainly based on how well the kidneys filter blood, serves both as a marker of disease severity and as a key criterion for financial assistance in Japan.
How the computers learned from patient data
To build their prediction system, the scientists tested three common machine learning methods: random forest, support vector machine, and naïve Bayes. All three learn from examples rather than from fixed formulas. The dataset was split into a training portion, used to fine‑tune each model, and a testing portion, used to check how well the final models performed on unseen cases. The computers tried to predict which of several CKD stages each patient would reach after three years. The random forest method, which combines many simple decision “trees” into a voting committee, showed the best performance, correctly predicting the stage in about 73% of test patients. The support vector machine, which assumes mainly straight‑line relationships between factors and outcome, did less well, while the simple naïve Bayes model fell in between.
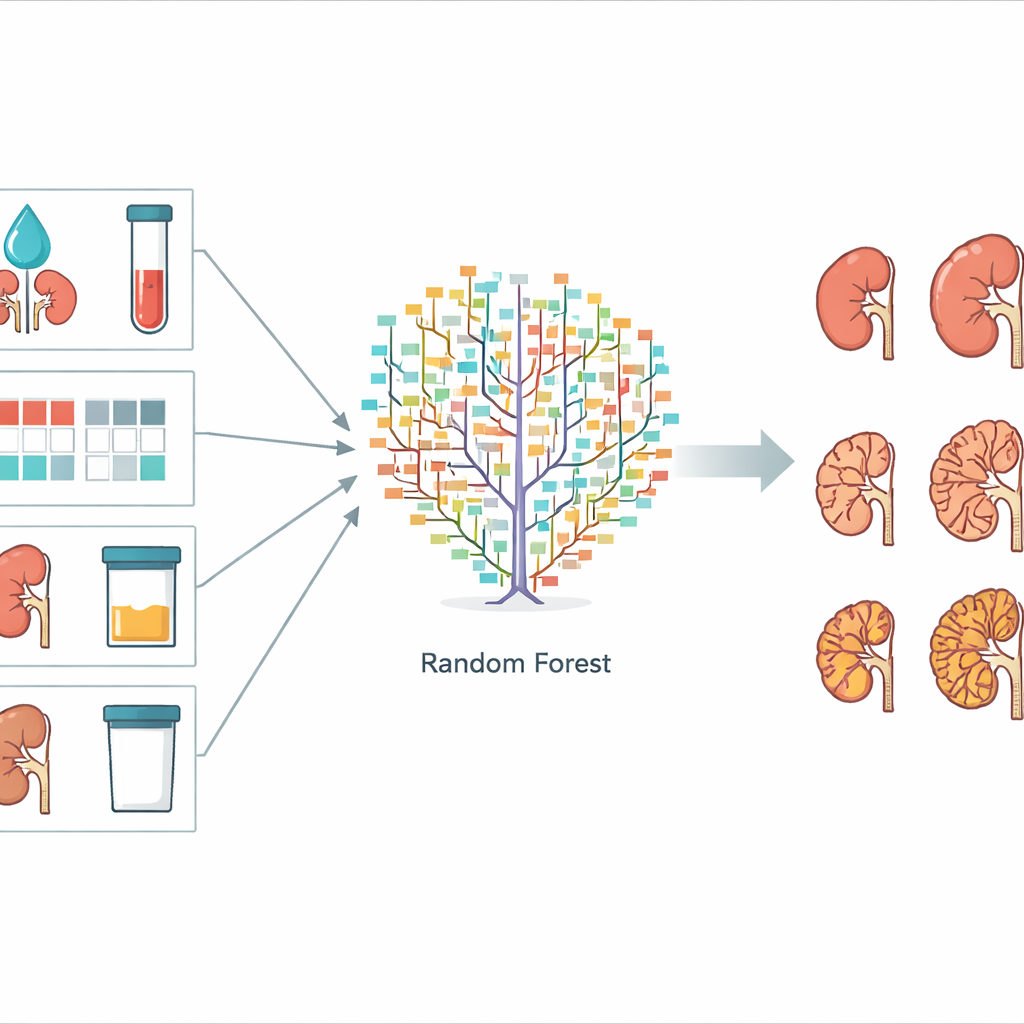
What mattered most for prediction
The team also asked which pieces of information were most useful to the random forest model. They measured this by shuffling one factor at a time and seeing how much the predictions got worse. Five features stood out as especially important: the estimated filtration rate of the kidneys (eGFR), the level of creatinine in the blood (another marker of kidney function), a color‑coded CKD "heat map" that combines filtration and urine protein findings, the amount of protein in the urine, and the total volume of both kidneys. These are all measurements that can be gathered during ordinary clinic visits, without specialized imaging files or gene sequencing. Other items, such as the exact number of cysts seen on scans, contributed little, suggesting they are not essential for a practical prediction tool.
What this means for patients and doctors
For people living with ADPKD, the study suggests that a carefully trained computer model fed with standard lab tests and basic imaging summaries can provide a reasonably accurate forecast of kidney health three years down the line. Because the best‑performing model can capture complex, non‑straight‑line relationships among factors, it may be better suited than traditional risk charts for this lifelong, variable disease. While the work is limited to Japanese patients and cannot prove cause‑and‑effect, it points toward clinic‑friendly tools that help identify who is likely to worsen quickly and who may have a slower course. In plain terms, the article concludes that machine learning – especially the random forest approach – can turn everyday medical data into individualized previews of kidney future, supporting more personalized care and better planning for patients with ADPKD.
Citation: Shimada, Y., Kataoka, H., Nishio, S. et al. Machine learning for predicting CKD stages in patients with autosomal dominant polycystic kidney disease: a nationwide cohort study in Japan. Sci Rep 16, 8771 (2026). https://doi.org/10.1038/s41598-026-39885-7
Keywords: polycystic kidney disease, chronic kidney disease, machine learning, risk prediction, personalized medicine