Clear Sky Science · en
EchoNet++: A multilingual soccer match audio commentary dataset
Why soccer sounds matter
Anyone who has watched a big match knows that the roar of the crowd and the rise and fall of the commentator’s voice are as much a part of the drama as the goals themselves. Yet almost all modern sports technology still focuses on what cameras see, not on what microphones hear. This paper introduces EchoNet and EchoNet++, a combined system and dataset that turn the chaotic sound of professional soccer broadcasts from many countries into clean, searchable text that computers can analyze. That makes it possible to study tactics, emotion, and storytelling across leagues and languages at a scale no human team of translators could match.
From noisy stadium to clean signal
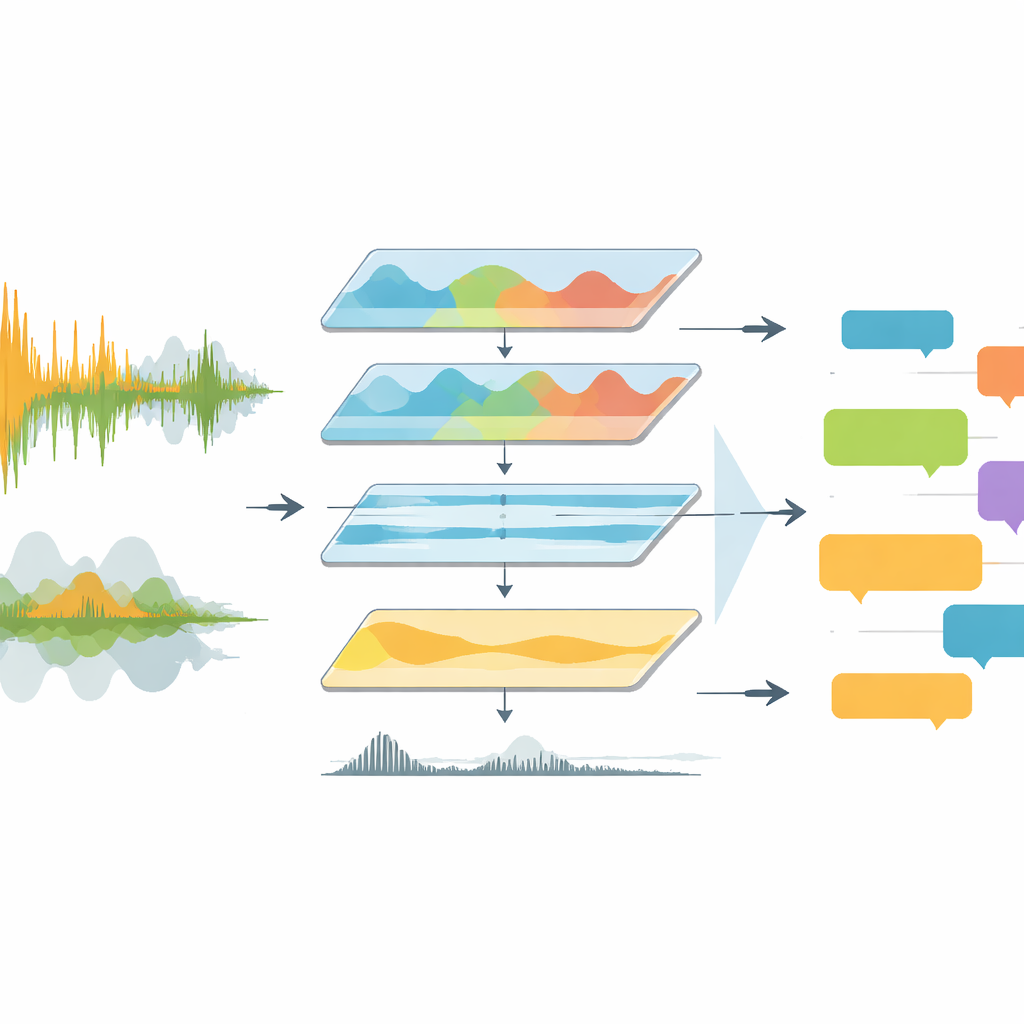
Televised matches are acoustically messy. Commentators talk over chanting fans, stadium music, and sudden explosions of cheering. Previous tools mostly fed this raw noise straight into speech-recognition software, which struggled with overlapping voices, shifting languages, and poor audio quality. EchoNet tackles the problem as an engineering pipeline rather than a single clever model. It begins by extracting the audio track from full-match videos and converting it into a standard, high-quality format. The system then moves into the frequency domain, focusing on the range where human speech lives while suppressing rumbling bass and shrill artifacts. A deep learning tool called Demucs further separates speech-like sounds from the rest, leaving a much clearer track for later stages to interpret.

Teaching machines to tell voices from noise
Once the sound is cleaned, EchoNet has to decide when someone is actually speaking and whether that voice belongs to a commentator or the crowd. For this, the authors use a neural voice activity detector that scans the audio in short windows and labels each moment as speech or non-speech. Detected speech chunks are then examined more closely. Segments that show the steady rhythm and structure of spoken language are tagged as commentary, while those that look like bursts of chaotic energy are tagged as spectators. This separation matters: commentator sentences carry tactical and narrative meaning, whereas crowd reactions mainly signal emotional peaks such as goals or near misses. By splitting these sources, the system can treat them differently in later analysis.
Turning many languages into one story
EchoNet feeds each commentary segment into several versions of the Whisper automatic speech recognition model, including both standard and speed-optimized variants. These models are trained on hundreds of thousands of hours of multilingual audio, making them well suited for Europe’s major leagues, where broadcasters switch among English, German, Spanish, Italian, French, and other languages. The system records each segment’s timing, language, and transcript into structured JSON files tied to the match halves. For non-English clips, EchoNet first transcribes in the original language and then sends the text to a translation engine to obtain English versions. This two-step design keeps transcription and translation errors separate, which helps researchers debug failures and compare language-specific behavior.
Measuring how well it all works
Because a pipeline is only as strong as its weakest step, the authors evaluate EchoNet from several angles. They introduce a new “Report Accuracy” score that converts traditional word error rates into a more intuitive percentage of practically correct content. Across three datasets—including their newly released EchoNet++ collection of 20 full matches—preprocessing with EchoNet consistently lowers transcription errors and boosts Report Accuracy by several points for every tested Whisper model. Signal-quality measures, which estimate how understandable the speech would sound to a human listener, also improve markedly after filtering, denoising, and normalization. Ablation studies, in which individual components such as the bandpass filter or voice detector are removed, show that each stage contributes meaningfully to both clarity and correctness.
What this means for fans and analysts
In everyday terms, EchoNet and EchoNet++ provide a reliable way to turn hours of noisy, multilingual match commentary into clean, time-aligned text and crowd indicators. With this foundation, developers can automatically detect key events from the commentator’s tone and words, match those moments to spikes in crowd reaction, and build detailed summaries or highlight reels without manual logging. Crucially, the dataset and code are being released for research use, giving the community a shared, reproducible platform for studying soccer through sound. For fans and analysts alike, this work nudges sports coverage toward a future where the soundtrack of the game becomes as searchable and analyzable as the video itself.
Citation: Majeed, F., Nazir, M., Agus, M. et al. EchoNet++: A multilingual soccer match audio commentary dataset. Sci Rep 16, 8884 (2026). https://doi.org/10.1038/s41598-026-39884-8
Keywords: soccer analytics, sports audio, speech recognition, multilingual commentary, broadcast analysis