Clear Sky Science · en
Bringing cross-validation into the real world to evaluate transferability of satellite-based vegetation models
Why watching grass from space matters
Grasslands feed livestock, support wildlife, and store carbon, and many ranchers and conservationists now rely on satellites to keep an eye on how much plant material is on the ground. New maps promise near‑real‑time views of pasture conditions, but their accuracy in unusual years—like deep droughts or very wet seasons—is often taken on faith. This study asks a simple but crucial question: how well do the computer models behind these satellite maps hold up when the real world refuses to look like the data they were trained on?
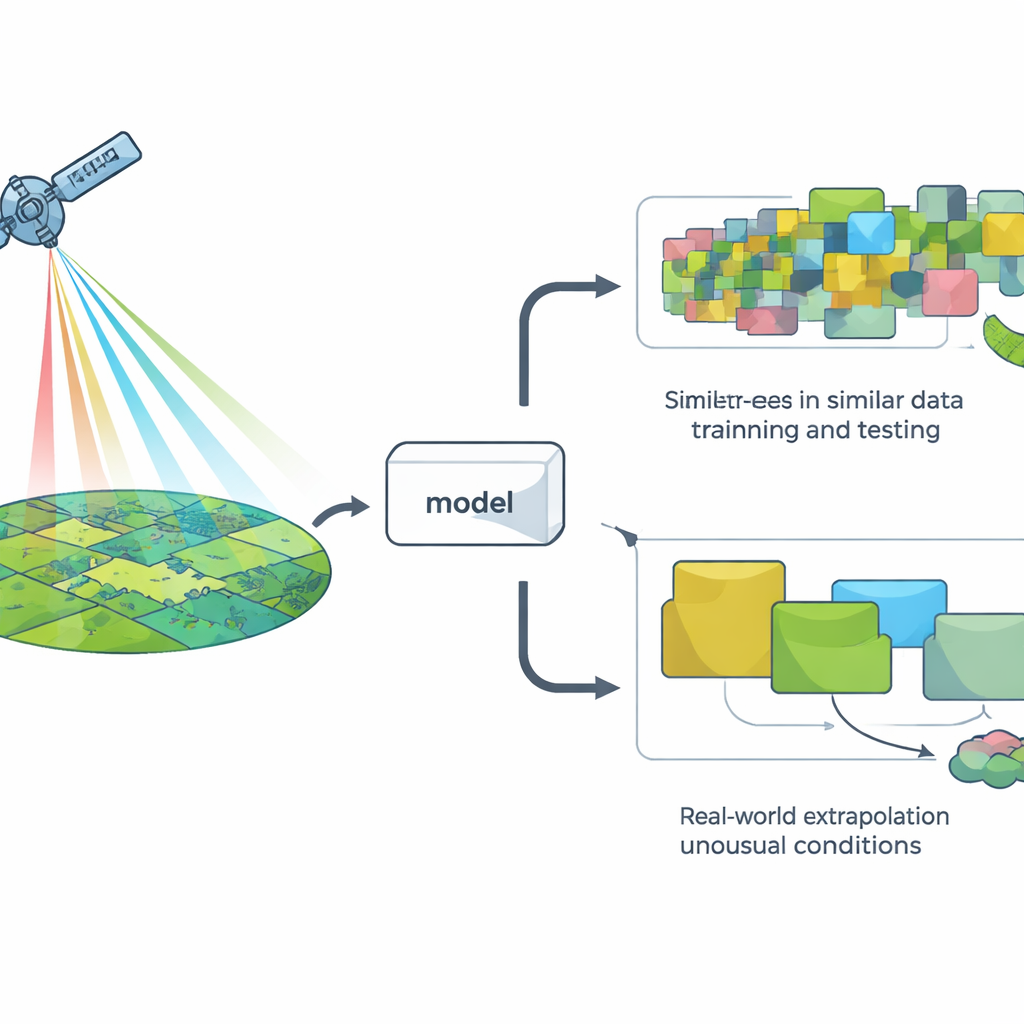
Checking models the easy way versus the hard way
To judge a model, researchers usually use a method called cross‑validation: they hide some data, train the model on the rest, and see how well it predicts the hidden points. The most common version randomly splits the data, which works fine for many problems but quietly assumes that all observations are independent. In landscapes, that assumption often breaks down: nearby places and neighboring years tend to look alike from space. As a result, random splits can make it seem as if a model is facing “new” situations when in fact it is mostly seeing more of the same.
Putting satellite models through real‑world tests
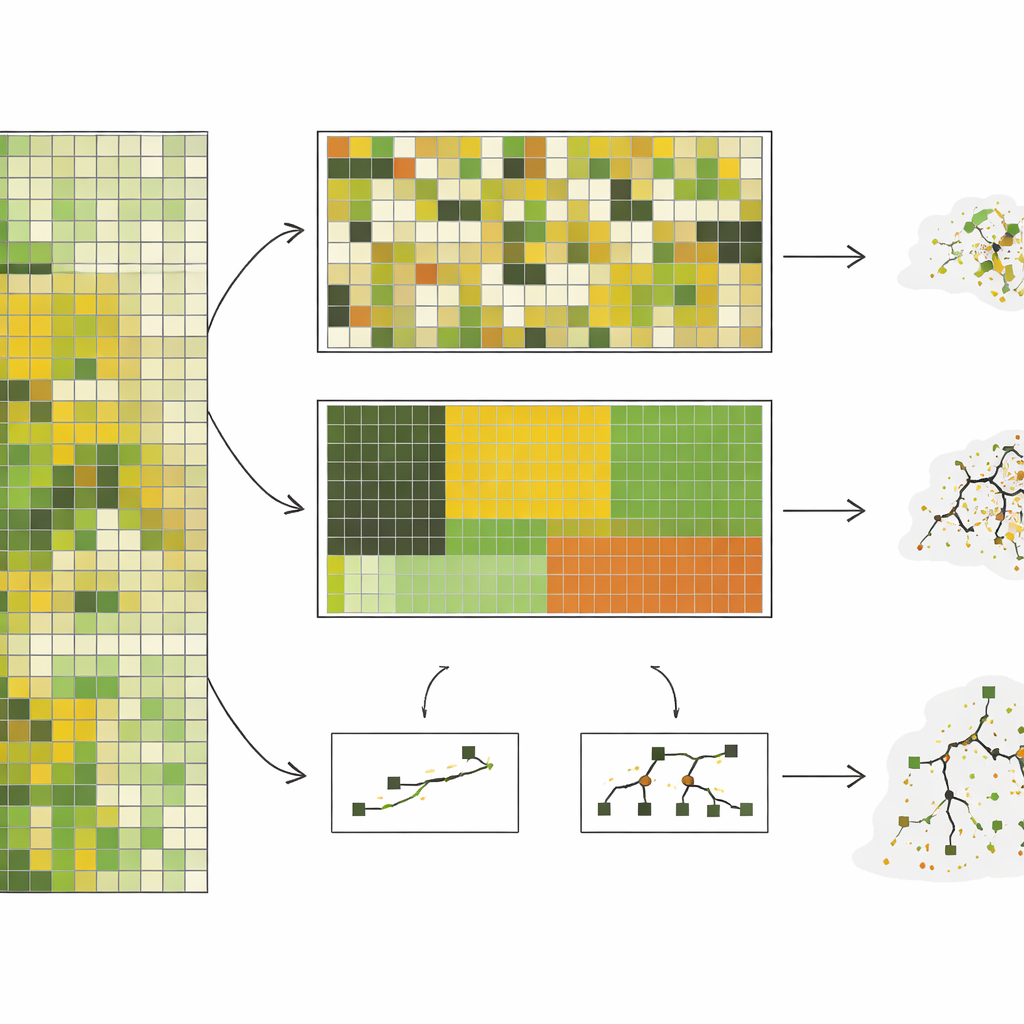
The authors assembled almost 10,000 on‑the‑ground measurements of standing herbaceous biomass—essentially how much grazeable plant material is present—from a shortgrass steppe in Colorado, collected over 10 years. They paired these measurements with detailed satellite imagery and then trained seven different types of computer models, ranging from simple straight‑line approaches to complex decision‑tree systems. Instead of just using random splits, they tested five ways of holding data out: by randomly chosen plots, by pasture blocks, by ecological site type, by year, and by clusters of pixels that looked spectrally distinct. These last two approaches, especially grouping by year and by spectral clusters, forced the models to predict for conditions that were truly different from what they had seen before.
When the future looks unlike the past
Across the board, model performance dropped sharply as the tests became more demanding. Under random splitting, complex models such as random forests looked impressive, explaining around three‑quarters of the variation in biomass. But when asked to predict for an entirely unseen year—a realistic task for near‑real‑time monitoring—their accuracy fell, and relatively simple models based on a handful of combined satellite variables did as well or better. In the most extreme test, where data were grouped to be as different as possible from each other, the accuracy of the complex models collapsed, while the better simple models held on to moderate, more predictable performance. The study also showed that complex models were highly sensitive to whether rare conditions, like severe droughts, were represented in the training data, sometimes performing very poorly in those high‑stakes scenarios.
Stable workhorses beat flashy sprinters
Beyond raw accuracy, the team examined how consistent each model was when retrained with slightly different subsets of years. Simpler methods, especially partial least squares regression, tended to pick out the same key satellite signals again and again, needed only a few tuning choices, and produced more stable results across years. More complex approaches often changed which inputs they relied on, needed many different tuning settings, and showed large swings in performance from one training run to another. For land managers who must update maps every year as new data arrive, this kind of stability can be just as important as peak accuracy in a favorable year.
What this means for using satellite maps on the ground
For people who depend on satellite‑based vegetation maps to decide when and where to graze livestock, react to drought, or track ecosystem health, this study carries a clear message. Common testing habits that shuffle data at random can paint an overly rosy picture of how well a model will perform when the weather swings to extremes or when it is applied in new places. When models are evaluated in ways that mimic their real‑world use—predicting for new years, new ecological settings, or rarely seen conditions—simpler, well‑behaved methods can outperform sophisticated ones and give more reliable guidance. In practice, that means developers should report how their models fare under several tougher, more realistic tests, and users should look for products whose performance has been checked in the kinds of challenging situations they are most likely to face.
Citation: Kearney, S.P., Augustine, D.J., Porensky, L.M. et al. Bringing cross-validation into the real world to evaluate transferability of satellite-based vegetation models. Sci Rep 16, 9383 (2026). https://doi.org/10.1038/s41598-026-39866-w
Keywords: satellite vegetation mapping, cross-validation, grassland biomass, machine learning models, drought monitoring