Clear Sky Science · en
Calibrating deep classifiers with dynamic confidence propagation and adaptive normalization
Why trusting AI confidence matters
Modern artificial intelligence systems don’t just say what they think is in a photo or sensor reading—they also output how sure they are. That self‑reported confidence is crucial in safety‑critical settings such as medical imaging, autonomous driving, or industrial monitoring, where a misplaced sense of certainty can be dangerous. Yet today’s deep neural networks are notorious for being overconfident in their mistakes, and existing fixes often break down when data are imbalanced or come from shifting environments. This paper introduces a new method, called Dynamic Confidence Propagation with Alternating Normalization (DCP‑AN), designed to make AI systems’ confidence scores more honest, stable, and efficient in realistic, changing conditions.
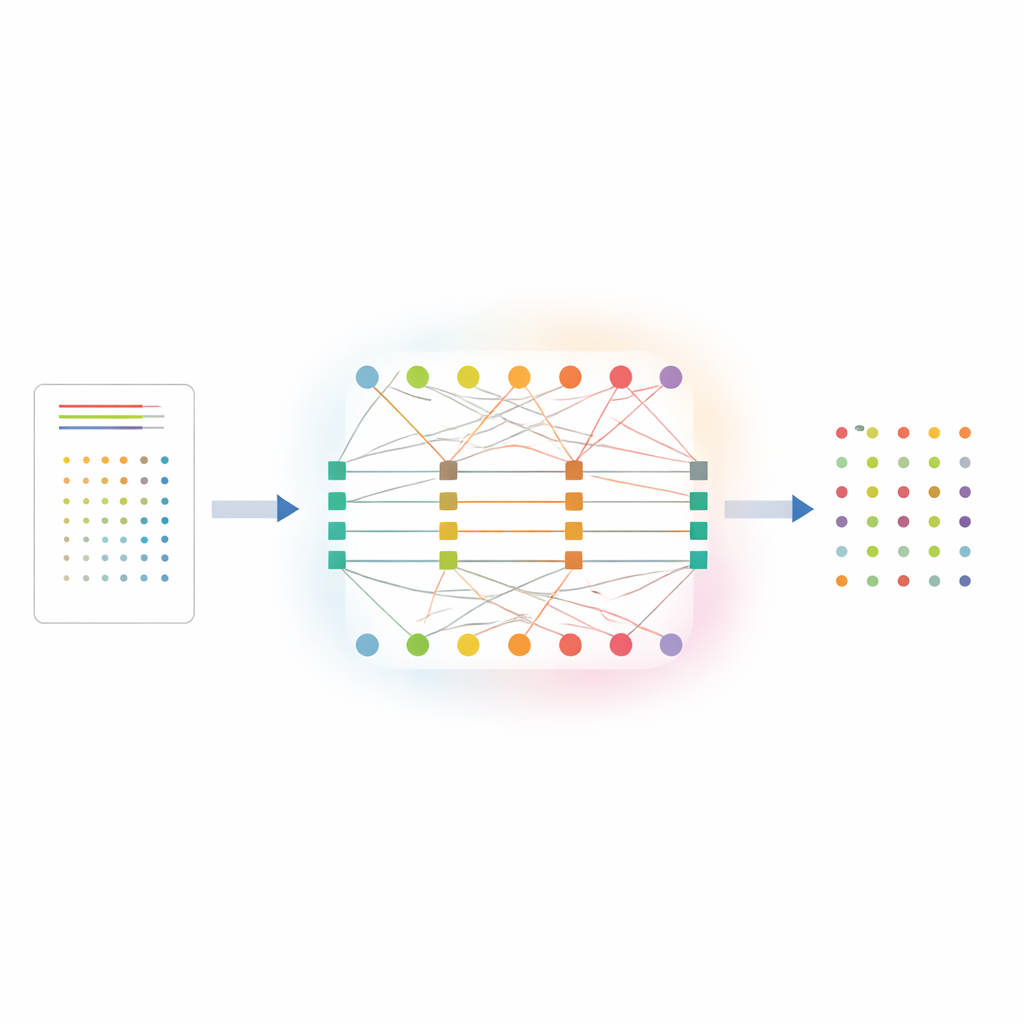
When smart machines are too sure of themselves
Most popular deep learning models are trained to predict the correct label, not to judge how trustworthy each prediction is. As a result, a network might be 99% “sure” that an image shows a cat when it is actually a dog. Standard calibration techniques, such as temperature scaling or dividing predictions into confidence bins, try to fix this after training by applying global adjustments. However, these methods treat all categories and all examples the same way. In the real world, data are rarely balanced: a few common “head” classes have many examples, while rare “tail” classes might appear only a handful of times. Networks tend to be overconfident on common classes and underconfident on rare ones, a gap that static, one‑size‑fits‑all corrections cannot close—especially when the data distribution changes across domains, such as from artistic sketches to real‑world photos.
A new way to share information between data and labels
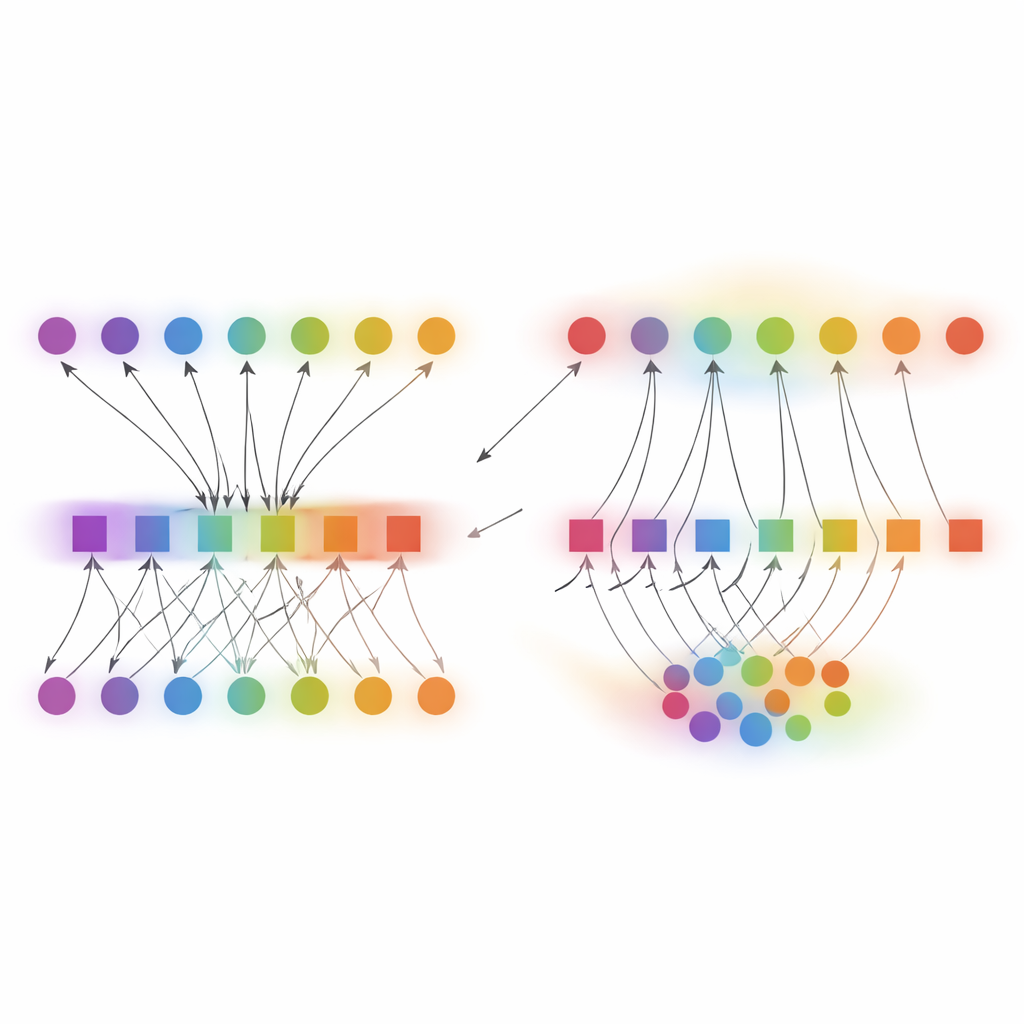
DCP‑AN tackles this problem by explicitly modeling how confidence should flow between individual samples and the classes they belong to. The method represents the relationship between samples and classes as a two‑layer network: one layer of nodes for samples, another for classes, linked by weighted connections that encode initial prediction strengths. Confidence is then refined through a two‑step dance. In the first step, information flows from samples to classes, adjusting how sharply each class’s predictions are spread out, guided by how uncertain that class currently appears. In the second step, information flows back from classes to samples, nudging each sample’s confidence profile based on how consistent it is with earlier estimates. By repeating this back‑and‑forth process a limited number of times, the system encourages better “teamwork” between examples and labels, so that rare classes receive clearer signals instead of being drowned out by common ones.
Turning up the heat where it is needed
A key innovation in DCP‑AN is an adaptive “temperature field” that changes how strongly the method reshapes confidence, depending on how uncertain things look locally and globally. Instead of using a single temperature value for all predictions, the method computes separate adjustment strengths for classes and for samples, based on measures of uncertainty and mismatch over time. For head classes that the network already handles confidently, the effective temperature gently cools down, preventing over‑smoothing and preserving sharp distinctions. For tail classes and ambiguous samples, the temperature rises, allowing stronger corrections that lift their confidence when justified and dampen spurious spikes. This dynamic behavior emerges from a principled update rule and is shown to respond quickly when uncertainty grows, yet remain stable when the model is already well aligned.
Reliable improvement across tasks and hardware
The authors carefully evaluate DCP‑AN on several widely used image datasets. On a long‑tailed version of ImageNet, where some categories have hundreds of times more images than others, the method boosts accuracy on rare tail classes by about 10 absolute percentage points and cuts a standard calibration error measure by more than half compared with an uncorrected baseline. In a cross‑domain test that transfers a model trained on artwork to real‑world photos, DCP‑AN both increases accuracy in the new domain and reduces a statistical measure of the gap between source and target data. Importantly, these gains do not come at the cost of heavy computation: running on a modern graphics card, the method adds just over one millisecond of delay and less than half a megabyte of extra memory, keeping it practical for real‑time and edge devices.
What this means for everyday AI
In plain terms, this work shows that we can make AI systems not only smarter, but more self‑aware about when they might be wrong. By letting confidence information flow back and forth between examples and categories, and by adapting how aggressively it corrects itself based on changing uncertainty, DCP‑AN delivers probability estimates that better match reality—even for rare events and across shifting environments. Because it comes with a mathematical guarantee that its iterative updates settle quickly, and because it runs with minimal overhead, this framework could be plugged into existing neural networks in domains like healthcare, robotics, and security monitoring. The result is AI that still makes mistakes, but is much more honest about how sure it is—a crucial step toward systems people can safely rely on.
Citation: He, P., Fu, W., Wang, L. et al. Calibrating deep classifiers with dynamic confidence propagation and adaptive normalization. Sci Rep 16, 10959 (2026). https://doi.org/10.1038/s41598-026-39842-4
Keywords: confidence calibration, deep neural networks, long-tailed recognition, uncertainty estimation, domain adaptation