Clear Sky Science · en
A flexible framework for hyperparameter optimization using homotopy and surrogate models
Why Tuning the Dials of AI Matters
Modern artificial intelligence systems depend not only on clever algorithms and oceans of data, but also on a surprisingly fussy layer of settings called “hyperparameters.” These are the dials that decide how big a model should be, how fast it learns, and how it deals with noisy data. Getting them wrong can turn a promising system into a dud. This paper introduces HomOpt, a new way to tune those dials more efficiently and reliably, especially when the search space is huge and messy, making it attractive to anyone who cares about making AI work better with less trial and error.
A New Way to Guide the Search
Traditional approaches to hyperparameter tuning, such as grid search or random search, are a bit like trying recipes by throwing ingredients together and hoping something tastes good. More refined methods, like Bayesian optimization, try to be smarter by building a rough model of how settings affect performance, then using that model to pick the next combination to try. But these methods assume the performance “landscape” is smooth and well-behaved, which is often not true in real-world problems full of quirks, noise, and abrupt jumps. HomOpt tackles this challenge by repeatedly building approximate stand-ins for the true landscape—called surrogate models—and then smoothly transforming one surrogate into the next as more data arrives, all while tracking how the best solution moves during that transformation. 
Smoothly Morphing Models Instead of Starting Over
The key idea behind HomOpt comes from a mathematical concept called homotopy, which, in simple terms, is about gradually morphing one shape into another without tearing or jumping. In this framework, each surrogate model is a smoothed picture of how different hyperparameter settings affect a model’s performance. As new experimental results are collected, HomOpt builds an updated surrogate and then defines a continuous transformation between the old and new versions. Instead of discarding past work and restarting the search, it tracks how the best point on the old surface slides across this morphing landscape to land at a good point on the new one. This guided motion makes the search more directed and less random, improving the chances of finding better settings in fewer steps. 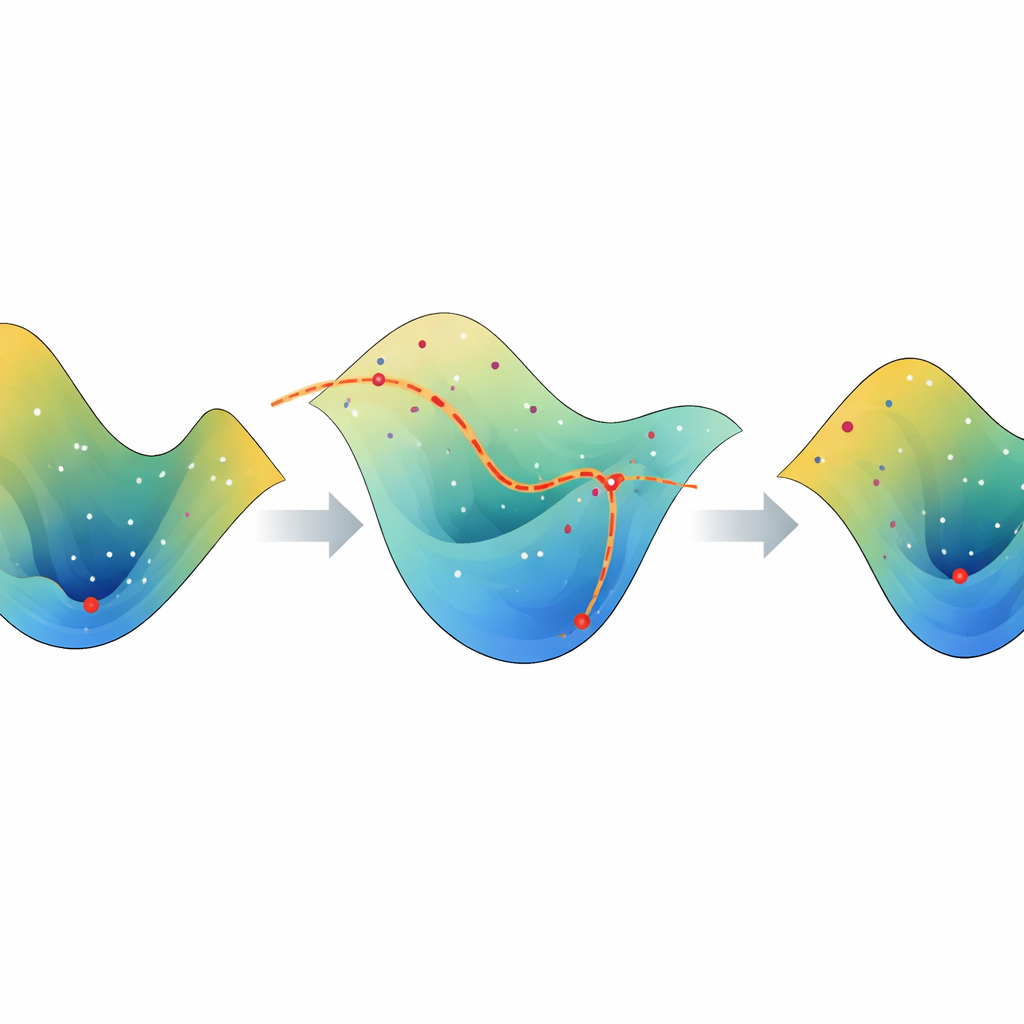
Flexible Tools for Different Types of Data
To show that the idea works in practice, the authors plug two very different kinds of surrogate models into HomOpt. First, they use Generalized Additive Models, which are smooth and fairly easy to interpret, making them useful when relationships between settings and performance change gently. Second, they use CatBoost, a powerful ensemble method well-suited to complicated, high-dimensional problems like image recognition. HomOpt does not lock itself to one surrogate; instead, it treats the surrogate choice as a plug-in component that can match the difficulty and structure of the task. The framework can handle continuous, discrete, and categorical settings, and can sit on top of common search strategies such as random search, Bayesian optimization, or tree-based methods, acting as a refinement layer rather than a replacement.
Putting the Method to the Test
The researchers evaluate HomOpt on a diverse set of benchmarks. On classic machine learning tasks drawn from public tabular datasets, they tune models like support vector machines, random forests, logistic regression, multilayer perceptrons, and gradient-boosted trees. They also examine demanding open-set recognition problems, where a system must cope with previously unseen categories, using a specialized classifier called the Extreme Value Machine. Finally, they test HomOpt on neural architecture search tables for well-known image datasets such as CIFAR-10 and ImageNet-style collections, where the space of possible designs is especially large and rugged. Across many of these settings, HomOpt either accelerates the descent toward good solutions or improves the final performance compared with the underlying methods alone, often using fewer expensive model evaluations.
What This Means for Everyday AI Practice
For practitioners, the main message is that HomOpt offers a structured way to make hyperparameter tuning smarter rather than simply more exhaustive. By continually refining an approximate picture of the performance landscape and smoothly following how its best point shifts as that picture improves, the method reduces wasted search and makes better use of every model run. Because it works with a wide range of loss measures, model types, and search strategies, HomOpt can be treated as a general-purpose add-on for existing optimization tools. In plain terms, it promises to get more accurate, robust AI systems out of the same compute budget—and to do so in a way that scales from small tabular problems to large, complex vision tasks.
Citation: Abraham, S.J., Maduranga, K.D.G., Kinnison, J. et al. A flexible framework for hyperparameter optimization using homotopy and surrogate models. Sci Rep 16, 9412 (2026). https://doi.org/10.1038/s41598-026-39713-y
Keywords: hyperparameter optimization, surrogate models, homotopy methods, automated machine learning, neural architecture search