Clear Sky Science · en
An adaptive data rebalancing framework for real-time traffic risk prediction
Why balancing traffic data matters for safety
Highway crashes are rare events compared with the vast amount of ordinary, uneventful driving. That is good news for safety, but it creates a hidden problem for computers that try to predict when and where crashes might occur in real time. When the data are dominated by safe situations, algorithms can become very good at predicting “nothing will happen” and still look accurate on paper—while quietly missing the truly dangerous moments. This study tackles that imbalance head-on, proposing an adaptive way to “rebalance” traffic data so that warning systems can better recognize rare but important risk conditions without becoming too slow for real-world use.
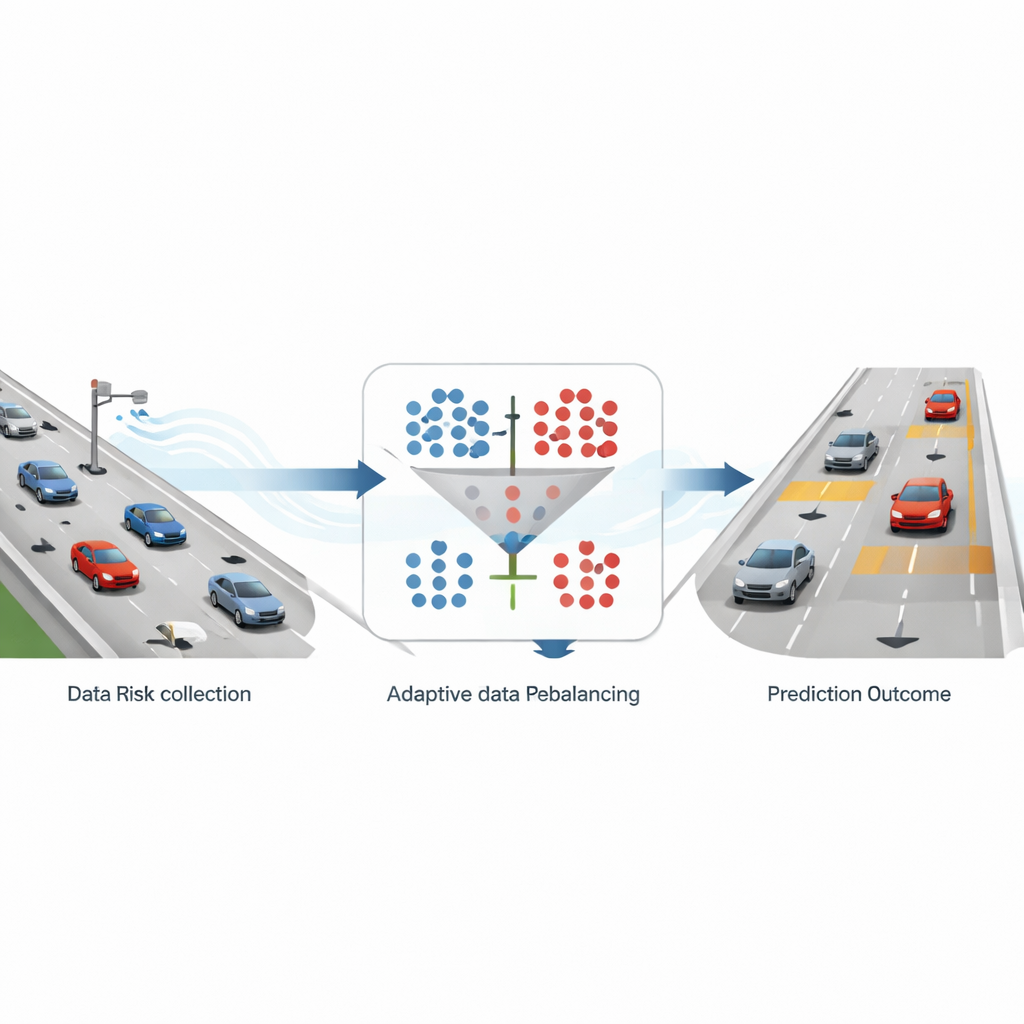
How real traffic is turned into warning signals
The researchers build their framework on detailed highway trajectory data from a large drone-based dataset recorded over German freeways. Every vehicle’s position and speed are tracked many times per second along six-lane highway segments. From this rich motion record, the team computes a widely used safety indicator called time-to-collision, which estimates how long it would take for a following car to hit the car in front if both continued as they are. When this time drops below three seconds, the situation is labeled “high risk”; otherwise, it is treated as “non-risk.” After aggregating these measures in 10-second slices and focusing on six-lane roads, they end up with about nine safe samples for every risky one, a strongly skewed dataset that mirrors real highway conditions.
Fixing the skew without losing what matters
To address this skew, the study compares two common strategies. One, called oversampling, adds more examples of rare risky situations by creating synthetic samples similar to real high-risk cases. The other, undersampling, pares down the many safe cases by randomly discarding some of them. The authors use a popular oversampling method (SMOTE) and a simple random undersampling method, applying them at several fixed ratios of safe to risky samples—1:1, 2:1, 3:1, and 4:1. They then feed both the original and altered datasets into four prediction models: two traditional machine-learning approaches and two deep learning models that specialize in handling time series. By testing all of these combinations, they can see how different ways of balancing the data change the system’s ability to spot risk while still recognizing safe conditions.
Letting an algorithm search for the sweet spot
Instead of assuming that perfectly equal numbers of safe and risky samples are best, the researchers let a genetic algorithm—a search method inspired by evolution—hunt for the most effective balance. This optimizer adjusts the safe-to-risk ratio within a realistic range from 1:1 to 4:1, repeatedly generating candidate ratios, evaluating them, and refining them over hundreds of iterations. Crucially, it does not look at prediction accuracy alone: it also considers how long the model takes to train and make predictions, reflecting the real-time demands of traffic control centers. To ensure that accuracy and computation time can be fairly combined, all measures are normalized before being blended into a single “fitness” score that the algorithm tries to minimize.
What the models learn about risk on the road
Across the many experiments, one pattern stands out. Balancing the data improves risk prediction compared with leaving the original skew untouched, and oversampling with synthetic risky cases tends to work better than throwing away safe ones. A 2:1 ratio of safe to risky samples gives the best performance among the fixed settings, outperforming the widely used 1:1 choice. When the genetic algorithm is allowed to fine-tune this ratio, it settles on slightly uneven but optimal values—about 2.3:1 for oversampling and 2.7:1 for undersampling. Among the prediction models, a particular type of recurrent neural network known as a gated recurrent unit consistently delivers the strongest results, especially when paired with oversampling and optimization. The models also reveal that average vehicle speeds upstream and downstream of a point on the highway are more informative for risk than simple counts of vehicles.
Checking stability and preparing for the real world
Because optimization methods can sometimes get stuck on misleading solutions, the authors examine how their search behaves over time. They show that the fitness scores steadily decline and eventually flatten out, suggesting that the algorithm is converging to stable, high-quality ratios rather than jumping around. They then nudge the chosen ratios up and down by a few percent to see whether performance collapses. In practice, the accuracy drops only slightly under small changes, indicating that the system is robust and not overly tuned to a single, fragile setting. However, when the portion of data reserved for testing becomes very large, the models become more sensitive, highlighting the need for sufficiently rich training data.
What this means for safer, smarter highways
In everyday terms, the study shows that teaching computers to recognize danger on the road is not just about clever models; it is also about feeding those models a fair view of rare but critical events. By carefully adjusting how many safe and risky examples are used in training—and by letting an adaptive algorithm find the best compromise between accuracy and speed—the proposed framework makes real-time highway risk prediction more reliable and more practical. Traffic agencies could embed this approach into systems that watch traffic detector data and issue early warnings about likely rear-end collisions, helping to guide driver alerts, patrol deployment, or automated braking strategies. While the work is demonstrated on German highways under good weather, the underlying idea of adaptive data balancing offers a general recipe for improving safety predictions wherever dangerous events are rare but too important to miss.
Citation: Chen, S., Cui, B. & Chang, A. An adaptive data rebalancing framework for real-time traffic risk prediction. Sci Rep 16, 8882 (2026). https://doi.org/10.1038/s41598-026-39539-8
Keywords: traffic safety, crash risk prediction, imbalanced data, machine learning, highway trajectories