Clear Sky Science · en
Interpretable and lightweight fall detection in a heritage gallery using YOLOv11-SEFA for edge deployment
Why gallery safety matters
As societies age, more older adults are visiting museums and heritage galleries—beautiful spaces that were never designed with modern safety monitoring in mind. A simple fall in these settings can lead to serious injury, yet wiring buildings with new sensors or constantly watching camera feeds is costly, intrusive, and often impractical. This paper explores a new way to spot falls automatically and quickly in such spaces, using compact artificial intelligence that can run close to the cameras themselves without flooding the internet with video or invading visitors’ privacy.
A tricky place to watch over
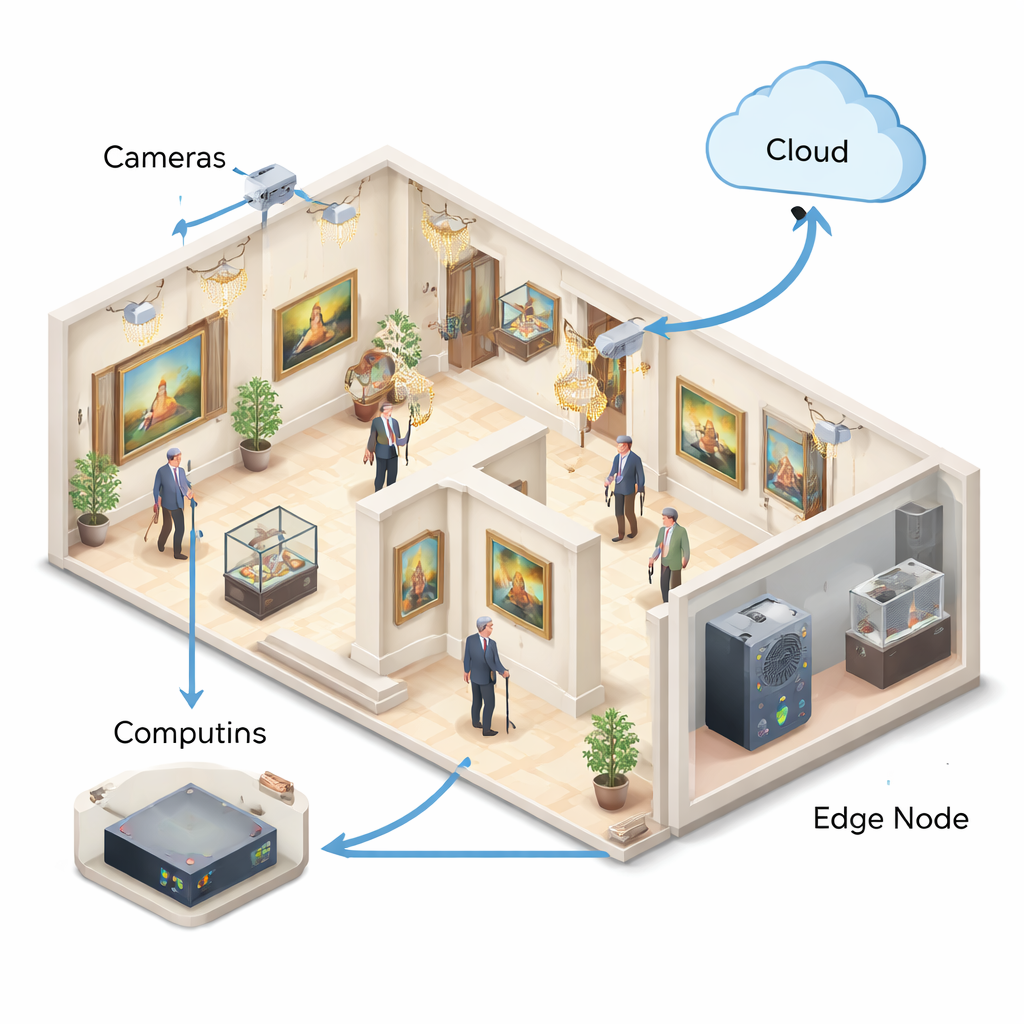
Rochfort Gallery in North Sydney, a restored 1920s building with high ceilings, ornate finishes, glossy floors, and glass cases, serves as the test bed for this work. These features make it visually rich for visitors but difficult for machines: light bounces off glass, shadows shift through the day, and crowds ebb and flow. Heritage protection rules also limit drilling, cabling, and bulky equipment. The authors argue that any fall detection system here must be compact, power‑efficient, and respectful of privacy, while still being reliable enough to support staff in keeping vulnerable visitors safe.
Teaching computers what a fall looks like
To train their system, the team did not rely on a small, staged dataset. Instead, they extended an existing image collection with thousands of additional photographs taken in museums, galleries, and community centers. Each image was labeled as either a normal posture (such as standing or walking) or a fall posture (lying on the floor in different orientations), and captured from various angles—ceiling‑mounted, side, and eye‑level views—under conditions ranging from daylight to dim, spotlighted rooms. They also deliberately included scenes with partial blocking by furniture or other visitors, as well as crowded rooms, to mirror the clutter and confusion of real public spaces.
A lightweight smart watcher at the edge
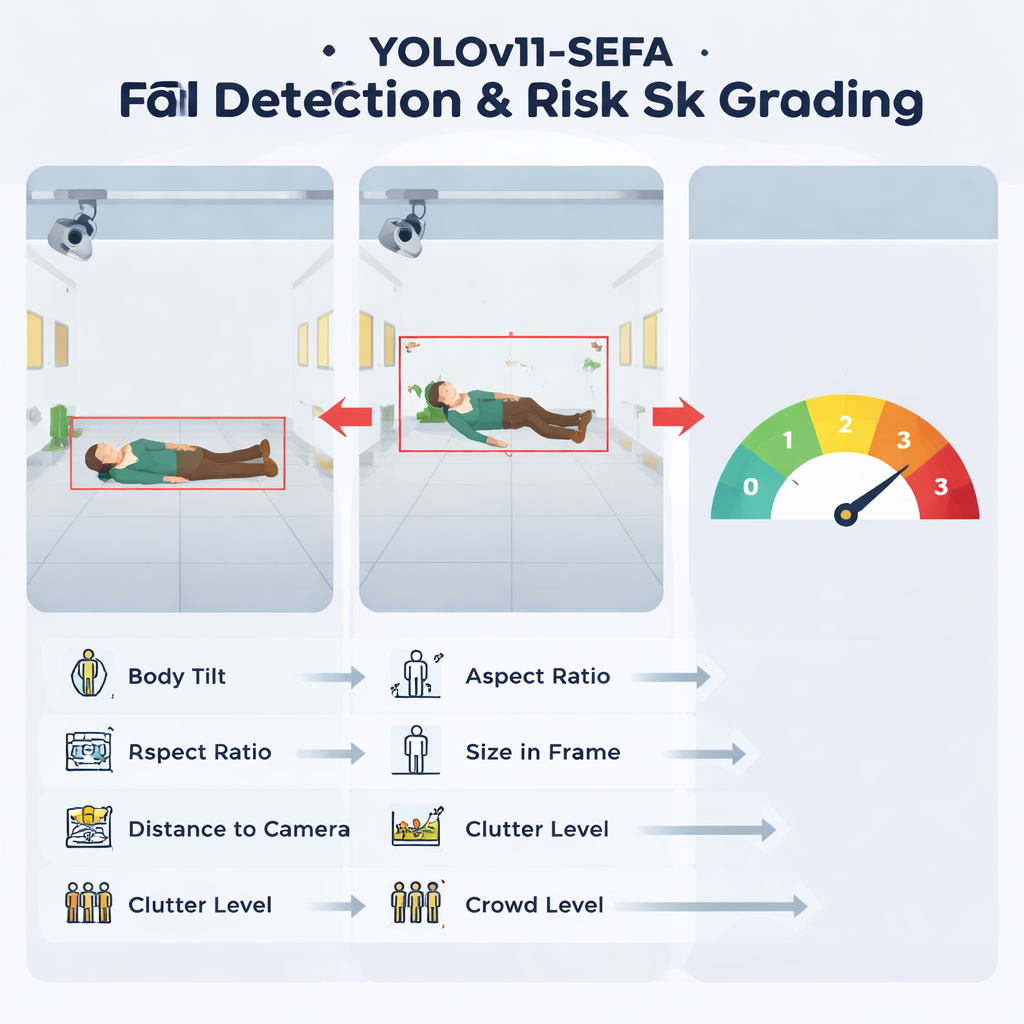
The core of the system is a streamlined object‑detection network called YOLOv11‑SEFA, which analyzes each camera frame and decides whether someone has fallen. Rather than building a heavier and more complex model, the authors add two focused tweaks to an existing fast detector so that it pays special attention to small or partly hidden bodies and to the regions where a person touches the floor. This boosts both the fraction of true falls it catches and the accuracy of its bounding boxes, while keeping the computation low enough to run on modest "edge" computers installed in the building. Tests against several popular alternatives show that this tuned model offers one of the best trade‑offs between accuracy and speed, using only a small increase in processing power compared with its starting point.
From simple alarms to graded risk
Rather than only shouting "fall" or "no fall," the system goes a step further and assigns each detected event a risk level from 0 to 3. To do this, it converts the visual detection into six simple numbers: how much of the image the person occupies, how tilted they are, how far they appear from the camera, how stretched or flattened their outline is, how visually busy the surrounding area is, and how many other people are present. A separate decision model, inspired by expert safety opinions, combines these values into four bands: normal activity, low‑risk odd posture, medium‑high risk, and obvious, high‑risk falls. Importantly, the authors use an explanation tool to confirm that the model really does rely most heavily on posture‑related cues, like body tilt and shape, rather than on irrelevant background details.
Testing in the real gallery
The complete system connects cameras, local edge computers, and a cloud service into a four‑layer pipeline. Cameras stream reduced‑rate video to compact machines on the same floor, which run the fall detector and generate alerts; only brief snippets or heat‑map overlays are sent to the cloud when needed, limiting both bandwidth and privacy exposure. In a 72‑hour pilot at Rochfort Gallery, the system maintained response times of around a quarter of a second even in crowded scenes and produced fewer than half a false alarm per hour at peak times—mostly from visitors crouching to take photos—while staged trial falls were all detected. The authors stress that these numbers come from a relatively short, controlled trial, but they show that the approach is technically workable in a demanding real‑world setting.
What this means for future public spaces
For non‑experts, the key outcome is that it is now possible to add an automatic, graded fall‑warning layer to existing camera systems in historic galleries and similar public buildings without major rebuilding or constant human monitoring. By running an efficient detector on small on‑site computers and carefully structuring how results are interpreted and shared, the system offers early evidence that technology can quietly stand guard in the background—spotting likely falls, hinting at how serious they might be, and doing so with modest hardware and an eye on privacy. Wider and longer trials, and extensions to other types of buildings, will be needed before it can be considered a city‑scale safety standard, but this work outlines a clear, practical path in that direction.
Citation: Wu, S., Yang, H., Hu, Y. et al. Interpretable and lightweight fall detection in a heritage gallery using YOLOv11-SEFA for edge deployment. Sci Rep 16, 7795 (2026). https://doi.org/10.1038/s41598-026-39527-y
Keywords: fall detection, smart galleries, edge AI, elderly safety, computer vision