Clear Sky Science · en
A data-efficient 3D medical vision-language model using only a 2D encoder
Smarter Help from 3D Scans
When doctors read CT or MRI scans, they don’t just look at single pictures—they mentally piece together hundreds of slices to understand a problem in three dimensions. Teaching computers to do the same could support faster, more consistent diagnoses and clearer reports for patients. But current artificial intelligence systems that handle 3D scans are extremely “data-hungry,” needing vast, carefully labeled datasets that many hospitals simply do not have. This paper introduces a way to get 3D-level understanding from existing 2D image technology, promising powerful tools that are easier and cheaper to build and deploy.
Why 3D Scans Are Hard for AI
Modern “vision–language” systems can already look at a 2D medical image and answer questions or draft a report in plain language. Extending that talent to 3D volumes would let AI reason about full organs and subtle lesions that only become clear when many slices are viewed together. The problem is that most current 3D systems rely on special 3D image encoders trained from scratch on huge collections of labeled scans. Such datasets are rare, expensive to annotate, and often tied to well-funded centers, which limits who can benefit. At the same time, simply treating each slice as a separate 2D image throws away the natural continuity across slices and drowns the model in repetitive information.
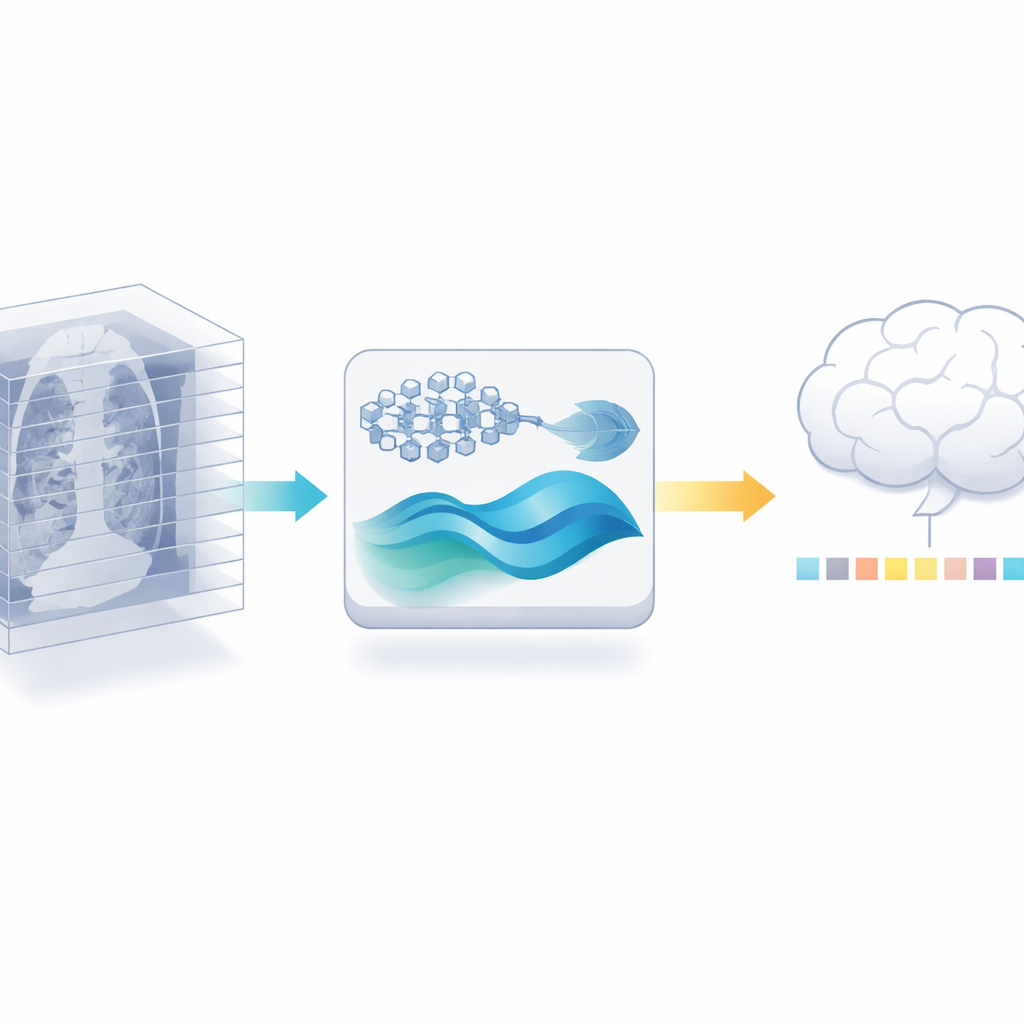
Recycling a 2D Expert for 3D Work
The authors propose a different path: instead of training a new 3D encoder, they reuse a powerful 2D medical image model that has already been trained on millions of labeled images from the medical literature. They first cut each 3D scan into its individual slices and let this 2D model extract detailed features from every slice. Then they carefully trim away redundancy: because neighboring slices in a scan often look almost the same, a similarity check can discard many near-duplicates while keeping the most informative views. This step alone reduces the amount of data the later stages must handle, without asking for more labeled scans.
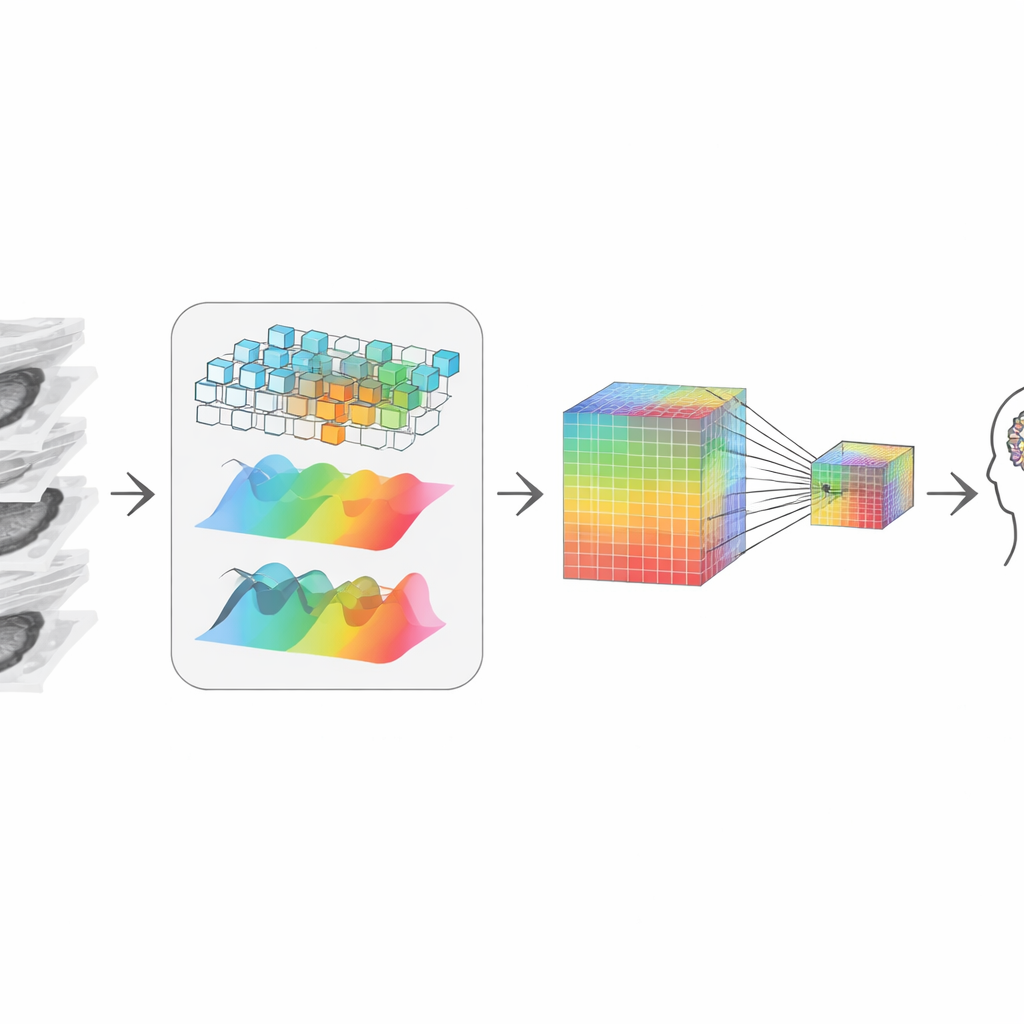
Rebuilding the 3D Story from Pieces
After trimming, the system needs to “re-stitch” the remaining slices into a coherent 3D picture. The authors do this by combining two complementary views of the data. One path looks at local shapes and edges, like a magnifying glass moving through the volume, sensitive to crisp boundaries and textures. The other path transforms the data into a frequency view, which is better at capturing broad patterns and long-range structure across slices—how a tumor extends or how an organ is shaped overall. An adaptive fusion step learns how much to trust each view at every point, yielding a representation that respects both fine detail and global context, even though it started from 2D slices.
Keeping Tiny Clues While Compressing
To talk to a large language model—the part that answers questions and writes reports—the visual information must be compressed into a modest number of tokens, or “visual words.” Simple shrinking would blur out tiny but critical signals, like small calcifications or subtle texture changes that matter in diagnosis. To avoid this, the authors create a two-track representation: one keeps a high-resolution version rich in detail, and the other is a smaller, cheaper version. An attention mechanism lets each point in the smaller version selectively “look back” to the larger version and pull in the sharpest available details. The result is a compact visual summary that still carries the clues a radiologist would care about, which is then passed to the language model for reasoning.
Proof on Real Medical Tasks
To test their design, the researchers evaluated it on public 3D benchmarks that ask two main things: can the system write accurate radiology-style descriptions of 3D scans, and can it answer questions about what is visible in them? Their approach, despite never training a 3D-specific encoder, outperformed several strong 3D-based models on both tasks. It produced more precise, clinically rich reports and answered questions more accurately, including difficult ones about the exact organ, abnormality, or location involved. It also ran faster and required far less 3D training data, and generalized well to different scan types such as MRI and PET.
What This Means for Future Care
In everyday terms, this work shows that we do not need to start from scratch with data-hungry 3D models to get high-quality help from AI on volumetric scans. By smartly recycling a strong 2D expert, carefully selecting informative slices, and rebuilding the 3D picture while preserving tiny details, the authors achieve state-of-the-art performance with much less data and computation. If adopted widely, this kind of approach could make advanced AI assistance—such as better reports, clearer explanations, and more reliable triage—available to hospitals and clinics that lack massive data resources, bringing sophisticated imaging analysis closer to routine clinical practice.
Citation: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
Keywords: 3D medical imaging, vision-language models, radiology AI, data-efficient learning, CT and MRI analysis