Clear Sky Science · en
Comparative performance analysis of quantum feature maps for quantum kernel-based machine learning
Why this matters beyond the lab
As our data and problems grow more complex, even today’s best machine learning tools can struggle to find clear patterns. Quantum computers promise new ways to tackle such problems, but it is still unclear when and how they can really help. This paper explores a practical piece of that puzzle: how to design and tune quantum-based classifiers so they can compete with, and sometimes rival, well-established classical methods on both toy problems and a real medical dataset.
Turning similarity into quantum power
Many successful learning methods, such as support vector machines, rely on “kernels” that measure how similar two data points are after an invisible transformation into a richer feature space. Quantum computers can implement such transformations naturally by encoding data into quantum states and then comparing how much two states overlap. The authors focus on these quantum kernels and on the “feature maps” that tell a quantum circuit how to convert ordinary numbers into quantum states. A good feature map makes tangled data easier to separate; a poor one wastes the quantum hardware. The work asks two key questions: which feature maps work best, and how much can careful tuning improve them?
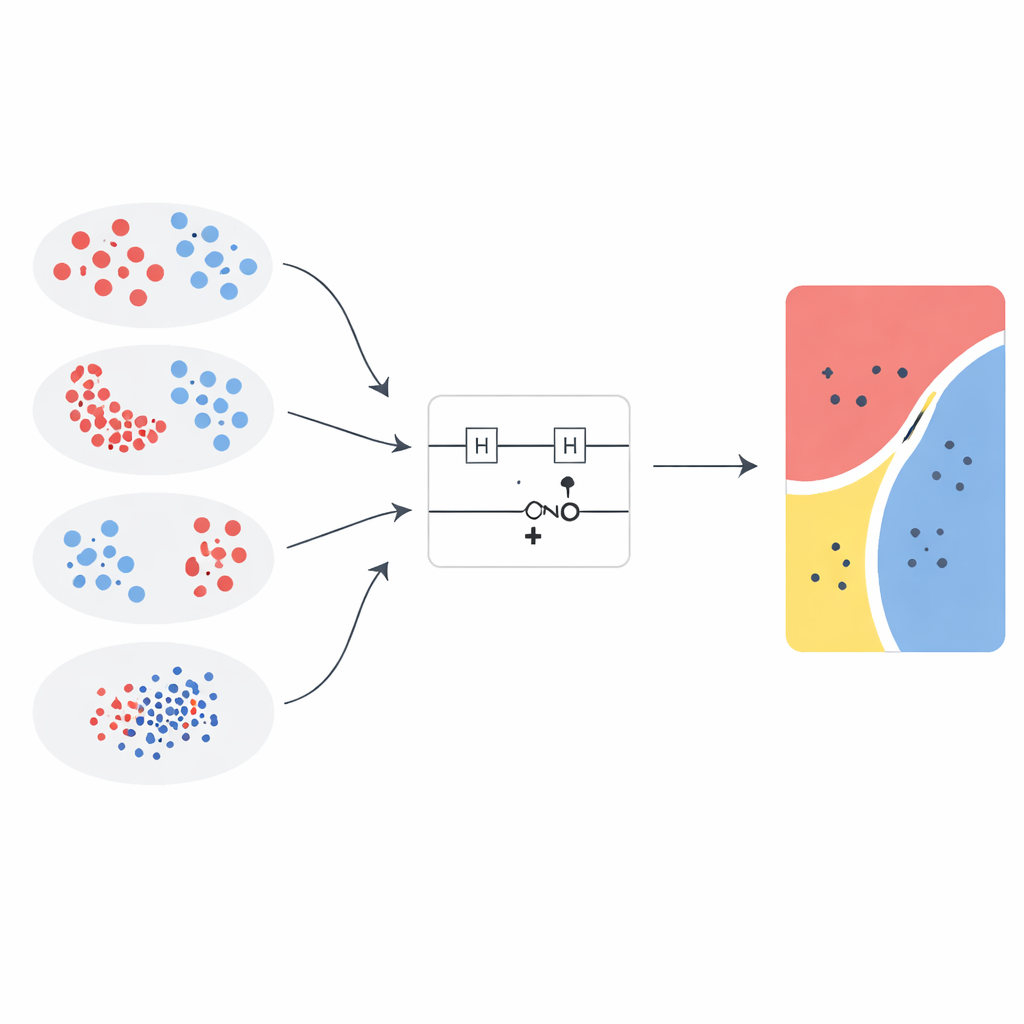
Testing several quantum recipes
The researchers introduce a new high-order feature map and compare it with five state-of-the-art designs from earlier work. Each map uses a simple two-qubit circuit that applies single-qubit rotations and an entangling gate, but the mathematical formulas that drive those rotations differ. To keep the study focused, the quantum circuit structure, the support vector machine settings, and the evaluation procedure are held constant while only the feature map and its internal “rotation strength” are varied. This makes it possible to attribute performance gains directly to the way data are encoded into quantum states rather than to extra tweaking of the classical learning algorithm around it.
From toy patterns to cancer diagnosis
The team evaluates the quantum kernels on three classic two-dimensional test problems—concentric circles, crescent moons, and an XOR pattern—as well as on a reduced version of the Wisconsin Breast Cancer Diagnostic dataset. For the medical data, two of the most informative imaging-based features are selected by a standard feature-selection method. All inputs are then rescaled to the same range and fed into shallow two-qubit circuits, keeping the experiments realistic for today’s noisy intermediate-scale quantum devices. Performance is compared against a broad set of classical models, including linear and radial-basis-function support vector machines, decision trees, random forests, boosting, naïve Bayes, linear discriminant analysis, and multilayer perceptrons, using accuracy and the Matthews correlation coefficient to capture both correctness and class balance.
What the comparisons revealed
Across the simpler benchmark datasets, the enhanced quantum kernels—especially those built from the new feature map and two of the existing ones—achieve nearly perfect classification, matching or surpassing most classical competitors. On the more demanding breast cancer data, the best quantum feature maps remain competitive with strong classical baselines such as radial-basis-function kernels and neural networks. A key knob is the rotational factor, which scales how strongly input values affect the quantum rotations. By sweeping this factor across several values, the authors show that choosing it well can markedly improve performance, and that the best value depends on the dataset. Visualizations of the feature spaces and the resulting decision boundaries make clear that some maps carve out finely detailed, well-aligned separating regions, while others leave distorted or poorly placed boundaries, explaining the spread in results.
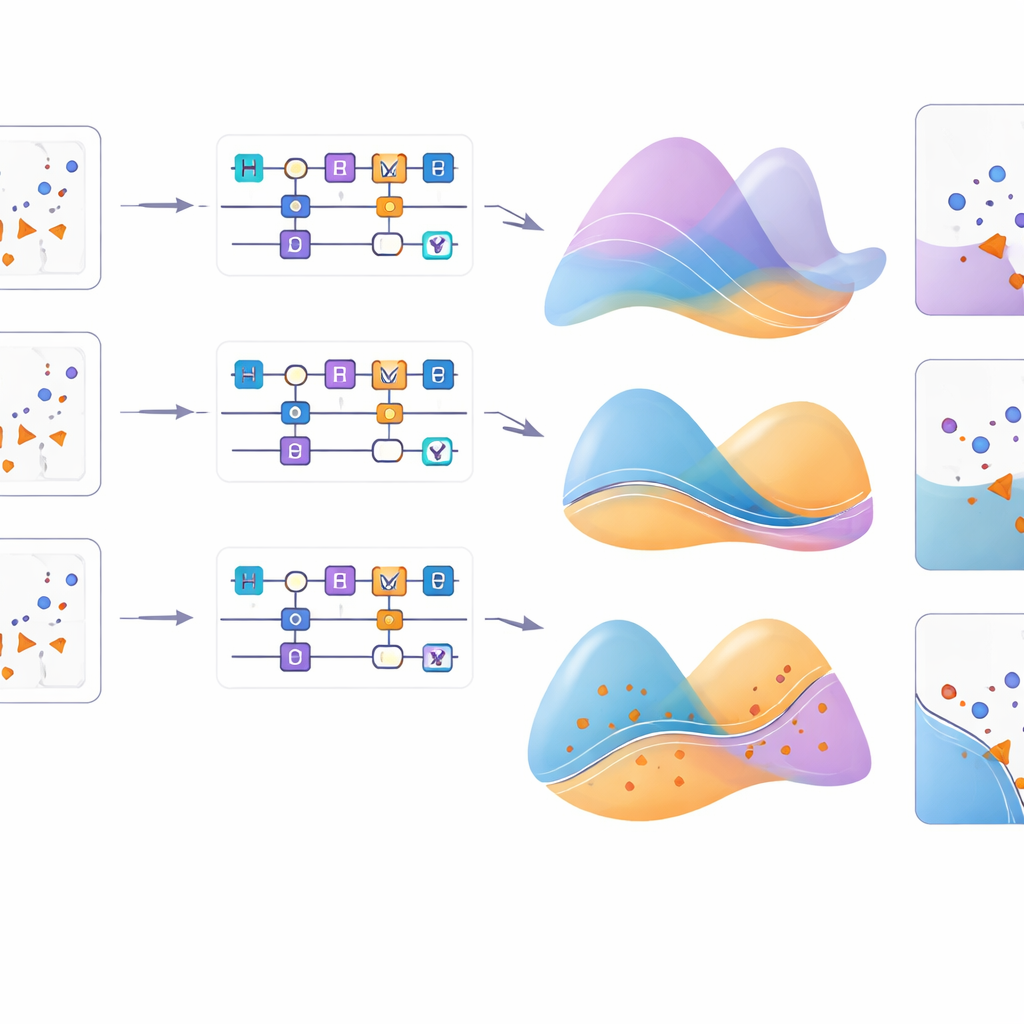
Zooming in on how it works
To better understand these effects, the study visualizes how each feature map reshapes a grid of input points for different problems. For the circular pattern, most maps successfully reproduce the underlying structure, but for the crescent moons and real cancer data only a subset of maps align well with the true distribution. Additional experiments vary the type of single-qubit rotation used and confirm that, for certain patterns like XOR, the choice of rotation axis can matter as much as the detailed encoding formula. Overall, the new feature map consistently ranks among the best, particularly when paired with an appropriate rotational factor, highlighting the subtle interplay between quantum gates, encoding formulas, and hyperparameter settings.
What this means going forward
To a non-specialist, the main message is that quantum advantage in machine learning will not come “for free” just by running standard models on quantum hardware. Instead, success depends on crafting the right way to feed data into quantum circuits and on tuning a few critical settings so that the quantum states capture the structure of the problem at hand. This paper provides a roadmap for doing exactly that with quantum kernel methods, showing that thoughtfully designed and tuned quantum feature maps can yield strong, sometimes superior, performance even with very small circuits. At the same time, the authors note that their results are based on simulations without hardware noise and on relatively modest datasets, so fully realizing these gains on real quantum machines and at larger scales remains a vital challenge for future work.
Citation: Jha, R.K., Kasabov, N., Bhattacharyya, S. et al. Comparative performance analysis of quantum feature maps for quantum kernel-based machine learning. Sci Rep 16, 8142 (2026). https://doi.org/10.1038/s41598-026-39392-9
Keywords: quantum machine learning, quantum kernels, feature maps, hyperparameter tuning, classification