Clear Sky Science · en
CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion
Teaching Cars to See the Whole Street
Modern cars and robots increasingly rely on cameras to understand the world around them—spotting roads, sidewalks, people, vehicles, and signs in real time. This paper presents CGDFNet, a new computer vision system designed to perform this kind of "scene understanding" faster and more accurately, especially in busy city streets. By learning to keep both the fine details (like traffic light poles or bicycle wheels) and the big-picture layout (like roads and buildings) in focus at once, CGDFNet aims to make automated driving and other real‑time vision tasks safer and more reliable.
Why Pixel-Level Vision Is So Demanding
In semantic segmentation, a computer assigns a category to every single pixel in an image: road, car, pedestrian, sky, and so on. This is far more demanding than simply drawing a box around a car, because the system must trace object boundaries and small shapes with high precision. Many high‑accuracy methods exist, but they tend to be slow and power‑hungry, which is a poor fit for real‑time systems in cars, drones, or wearable devices. On the other hand, lightweight methods that run quickly often sacrifice detail or lose track of the broader scene, struggling with small objects, thin structures, or crowded urban environments.
Two Paths: One for Detail, One for Context
CGDFNet tackles this tension with a dual‑branch design: one branch focuses on crisp details, while the other captures broad context. Building on an efficient backbone network, lower layers feed a “detail branch” that keeps higher resolution to preserve edges and textures. Deeper layers feed a “context branch” that views the scene in a more compressed form, good for understanding overall structure and relationships between objects. Unlike earlier two‑branch designs that largely keep these streams separate and then crudely add them together, CGDFNet encourages them to talk to each other throughout processing, so that fine details are constantly checked against what the network knows about the overall scene.
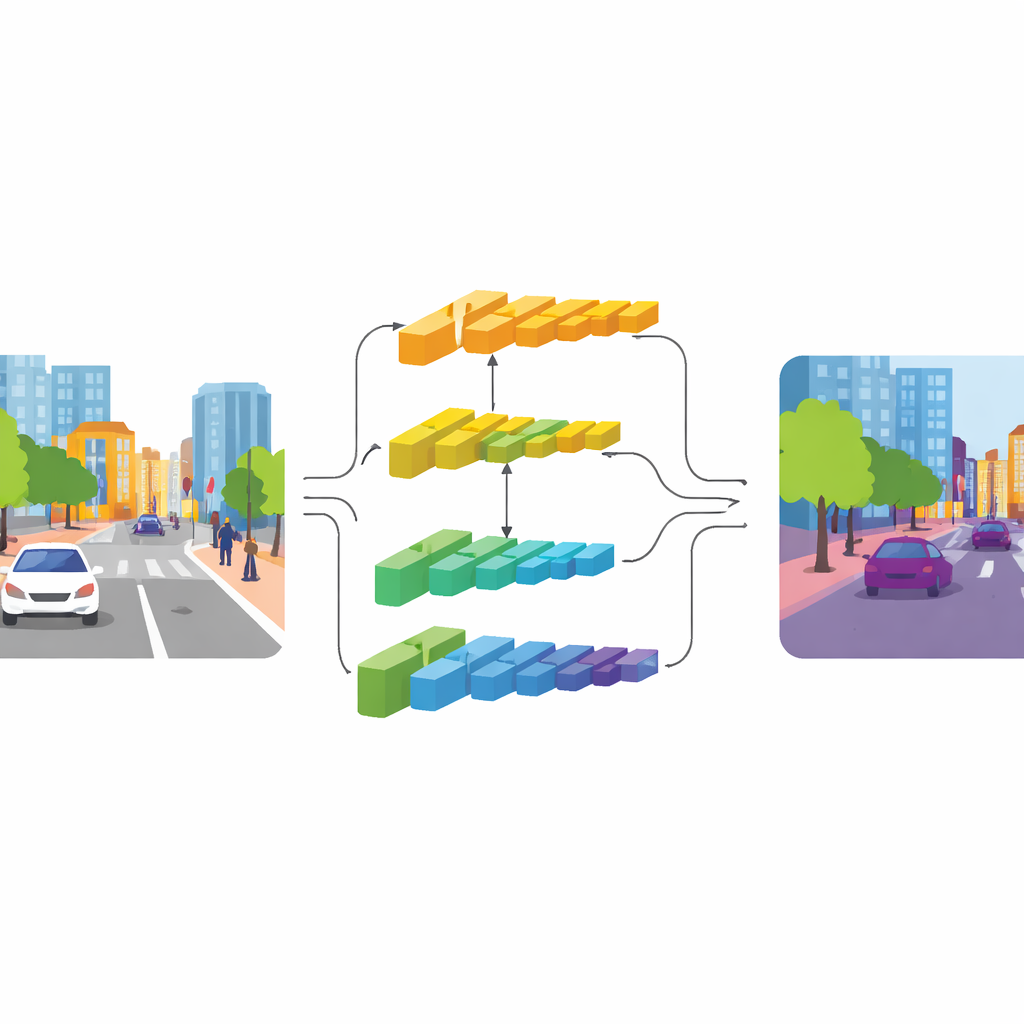
Guiding Details with Meaning
Two key components strengthen this interaction. In the context branch, a Semantic Refinement Module learns to highlight the most informative regions and channels in its feature maps. It does this by combining local cues (which parts of the scene are active near one another) with global cues (what the network sees across the entire image), so the representation carries both neighborhood detail and scene‑level meaning. In the detail branch, a Context‑Guided Detail Module uses this semantic information to steer attention to edges and fine structures that matter, such as the outline of a bus or the frame of a bicycle. It relies on a special kind of convolution that is more sensitive to changes between neighboring pixels, which naturally emphasizes contours and small objects without adding many extra parameters.
Blending Information in the Frequency World
A distinctive feature of CGDFNet is how it merges the two branches. Rather than simply adding their maps together in image space, the authors design a Fourier‑Domain Adaptive Fusion Module. This module temporarily transforms the combined features into the frequency domain, where patterns are represented in terms of slow, broad variations and fast, sharp changes. An adaptive gating mechanism then learns which frequency components to emphasize from the detail branch and which to emphasize from the context branch. After this weighting, the features are transformed back, yielding a representation that unites sharp edges with coherent global structure more effectively than traditional spatial‑only fusion.
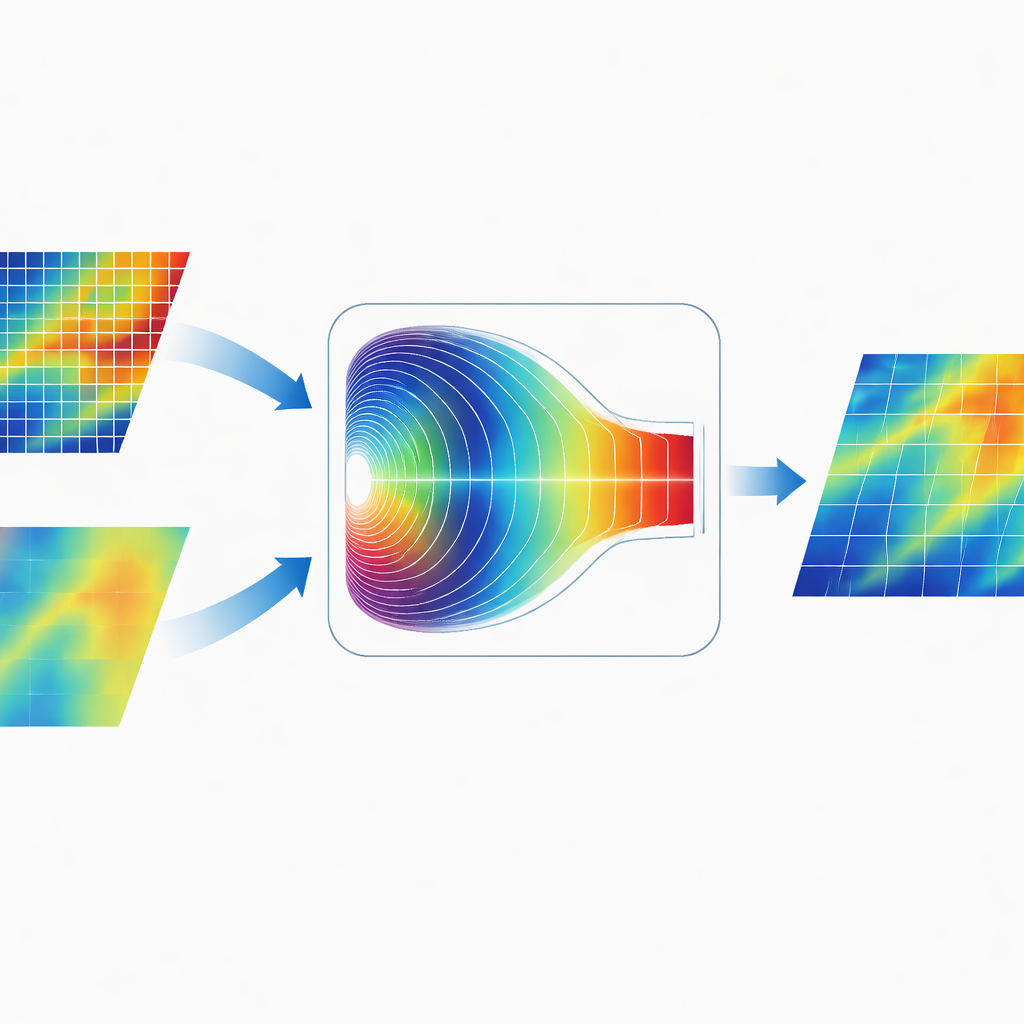
Results on Real Streets
The team tested CGDFNet on two widely used benchmarks for urban driving scenes: Cityscapes, collected from European cities, and CamVid, captured from a driver’s perspective in the UK. CGDFNet processed large images at real‑time speeds—around 88 frames per second on Cityscapes and about 129 frames per second on CamVid—while achieving segmentation accuracy that rivals or surpasses many state‑of‑the‑art systems. It performed especially well on categories that are usually hard to segment, such as fences, traffic signs, buses, and bicycles, where preserving precise boundaries and small structures is crucial.
What This Means for Everyday Technology
In practical terms, CGDFNet shows that it is possible to build vision systems that are both fast enough for real‑time use and careful enough to respect small, safety‑critical details in complex city scenes. By combining a detail‑focused branch, a context‑focused branch, and a smart fusion step in the frequency domain, the network keeps a balanced view of the street: it knows where everything is and where each object begins and ends. While challenges remain—such as densely packed crowds or bad weather—the approach offers a promising blueprint for future on‑device vision, from self‑driving cars to smart traffic cameras and assistive robots.
Citation: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
Keywords: real-time semantic segmentation, autonomous driving vision, dual-branch neural network, Fourier-based feature fusion, urban scene understanding