Clear Sky Science · en
Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition
Teaching Computers to Read Body Language
From video doorbells to smart rehab tools, many modern systems need to understand what people are doing just by watching how they move. But training computers to recognize human actions usually demands huge, carefully labeled datasets, where every wave, kick, or handshake is annotated by hand. This study introduces a way for machines to learn from raw motion data alone, using only the moving skeleton of the body—no labels, no faces, and no full-color video—making action recognition more accurate, more private, and far less dependent on expensive human annotation.
Why Skeletons Are All You Need
Instead of analyzing full video frames, the method works with 3D skeleton data: the coordinates of key joints such as shoulders, elbows, hips, and knees across time. This bare-bones view of the body has several advantages. It largely sidesteps privacy issues because faces and clothing are stripped away, and it is compact enough to process efficiently, even for long recordings. Skeletons are also robust to cluttered backgrounds and lighting changes that can confuse regular video-based systems. However, most existing skeleton-based approaches still rely heavily on labeled examples and struggle to fully capture how joints move together in complex, coordinated actions.
Learning Without Labels
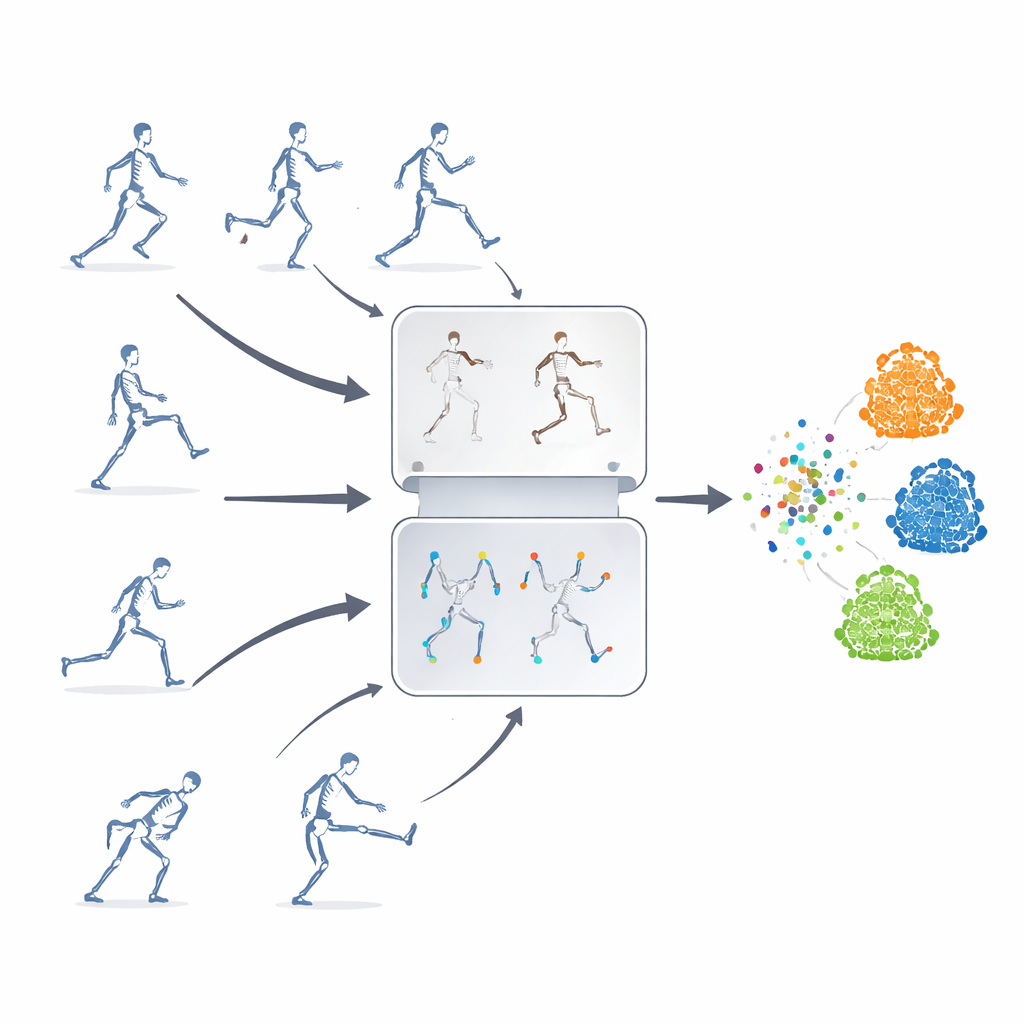
The authors propose a self-supervised learning framework, meaning the system teaches itself from unlabeled skeleton sequences. Their key idea is to combine two powerful strategies that are usually used separately. One is “masked prediction,” where parts of the skeleton data are deliberately hidden so that the model must guess the missing motion from the remaining context. The other is “contrastive learning,” which shows the model multiple altered versions of the same action and trains it to realize that these variations still represent one underlying movement. By blending these approaches, the system learns both fine details of joint motion and the big-picture meaning of an action.
Hiding the Right Joints
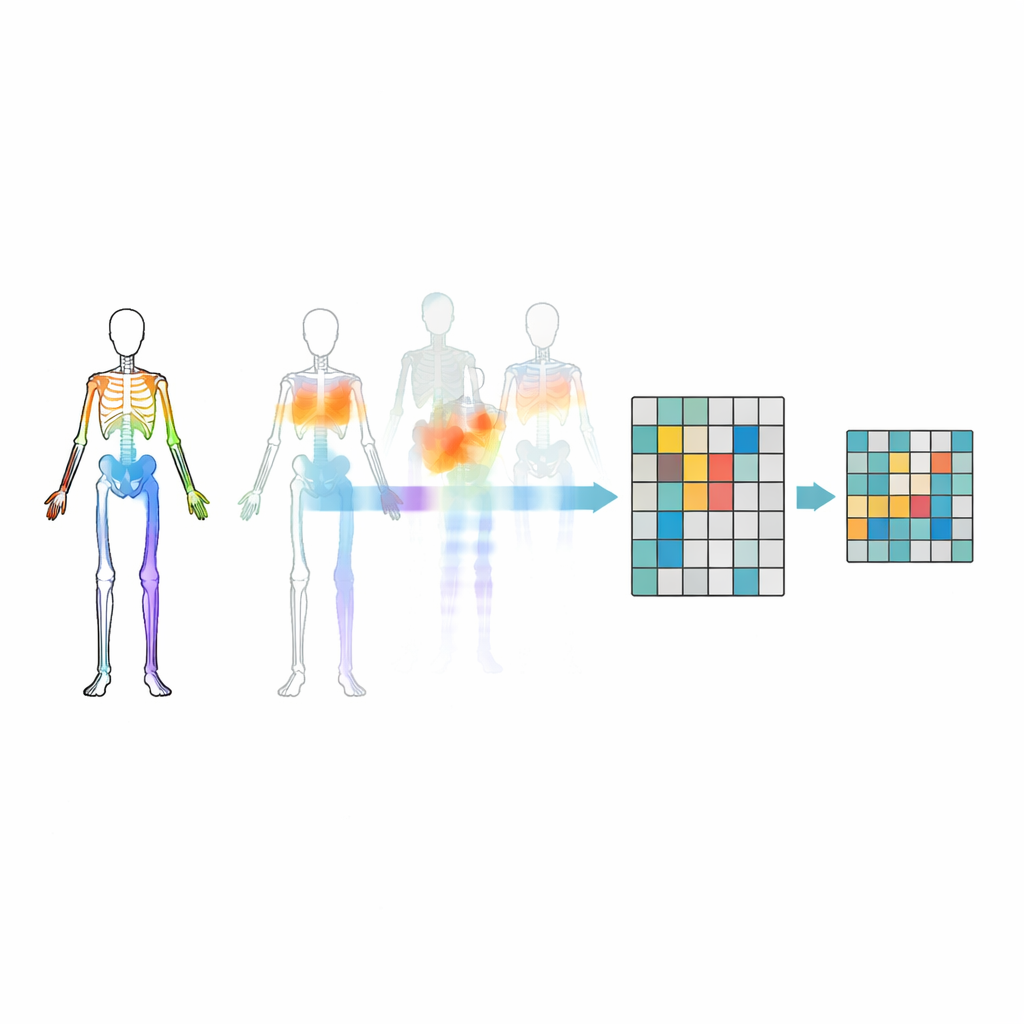
Simply masking random joints is not enough—the model might ignore important relationships between body parts or fixate on the most obvious motion. To avoid this, the researchers introduce a motion–topology masking strategy. They group joints into meaningful body regions such as arms, legs, and trunk, then measure how strongly each region moves over time. Masking decisions are guided by both the body’s structure and how much each region is moving, so that sometimes highly active parts are hidden and the model is forced to infer them from the rest of the body. This targeted hiding helps the system learn how joints cooperate during actions, rather than just memorizing a few flashy movements.
Stretching Actions in Many Ways
To train the contrastive part of the system, the same original skeleton sequence is transformed into many different “views.” Some changes are gentle, such as cropping the time window or slightly warping the trajectory, while others are more extreme, including flips, rotations, and stronger noise. These multiple levels of augmentation expose the model to a rich variety of motion patterns, encouraging it to focus on the core structure of an action rather than superficial details. At the same time, a trajectory-guided feature dropping module tracks which motion features the model relies on most and intentionally suppresses them during training. By temporarily removing its favorite clues, the system is pushed to discover backup cues and learn more general, transferable representations.
How Well Does It Work?
The framework is tested on three large public benchmarks of 3D human actions, covering everyday behaviors, medical-related movements, and interactions between people. Even though it uses only skeletal joint data and a relatively lightweight recurrent neural network, the method matches or surpasses many state-of-the-art systems that rely on more complex inputs or architectures. It is particularly strong when annotation is scarce or when some body parts are occluded, conditions that commonly arise in real-world environments. While its ability to transfer knowledge across very different datasets still leaves room for improvement, the approach significantly narrows the gap between labeled and unlabeled training for action recognition.
What This Means for Real-World Systems
To a non-specialist, the bottom line is that this work shows how computers can become much better at reading human body language without being explicitly told what every motion means. By smartly hiding and distorting skeleton data during training, the model learns robust patterns of movement that hold up under poor lighting, visual clutter, or missing joints, and does so with far fewer human-provided labels. This opens the door to more private, scalable, and adaptable action-recognition systems for applications ranging from home monitoring and sports coaching to medical rehabilitation and human–robot interaction.
Citation: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
Keywords: human action recognition, 3D skeleton data, self-supervised learning, contrastive learning, motion analysis