Clear Sky Science · en
A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification
Why following people across cameras matters
Modern cities are covered in cameras, yet those cameras rarely "talk" to each other. When a person walks from one street corner to a train station, different cameras see them from new angles, under different lighting, and often through crowds. Automatically recognizing that it is the same person across video clips—called video-based person re-identification—can help investigators trace movements after an incident, support missing-person searches, or power analytics in busy public spaces. But doing this accurately and efficiently, especially on modest hardware, is a major technical challenge.
A simpler brain for matching people in motion
This study introduces a compact artificial-intelligence system designed to tell whether two short video clips show the same person. Instead of using today’s trend of very deep or transformer-based networks, the authors build on a leaner design that combines two classic ingredients: a convolutional network that analyzes each video frame, and a gated recurrent unit (GRU) that tracks how appearance changes over time. These two branches are arranged in a Siamese layout—essentially, twin copies of the same network that share all their internal settings. Each twin processes one video sequence, and the system learns to produce similar internal signatures for clips of the same person and clearly different signatures for different people.
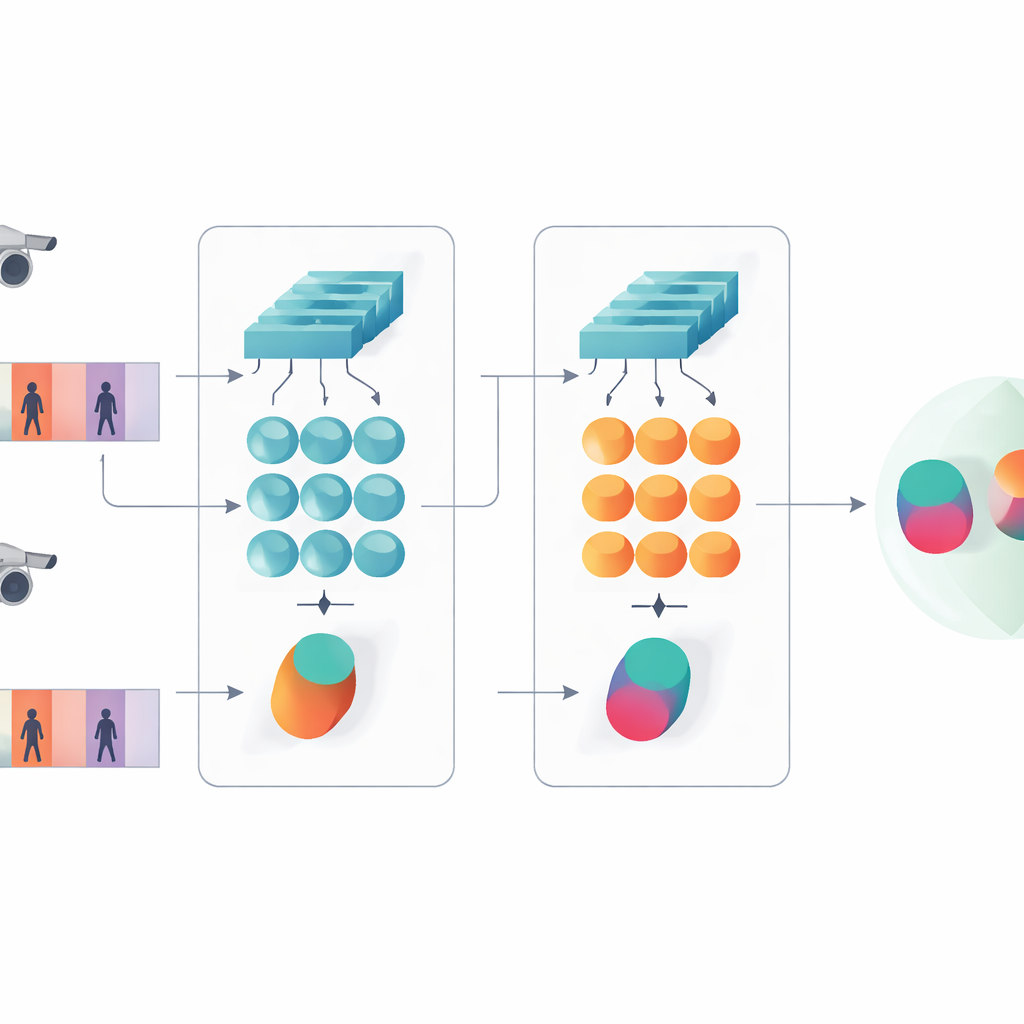
Seeing both details and patterns over time
A key idea of the work is that recognition should not rely only on the deepest, most abstract features of a network. Earlier layers still contain crisp visual details such as the weave of a jacket, stripes on trousers, or the outline of a backpack—cues that often survive changes in camera angle. The proposed model therefore keeps two levels of description. One branch pools the early-layer features over all frames to summarize fine-grained textures and local patterns. The other branch feeds later features into the GRU, which follows the sequence frame by frame and then averages its internal states over time. This averaging step avoids overemphasizing the last few frames and instead captures a consensus view of how the person looks and moves across the whole clip.
Training the twin networks to agree and to classify
To teach the system what matters, the authors combine two training goals. First, a verification objective encourages the twin branches to produce nearby signatures for videos of the same person and distant signatures for different people. Second, a classification objective asks the network to assign each training clip to a specific identity. By optimizing both at once, and by doing so at both low and high feature levels, the model learns internal descriptions that are not only distinct between people but also robust to noise, occlusion, and occasional poor-quality frames. The design remains shallow in terms of layers and parameters, which helps it avoid overfitting on relatively small video datasets.
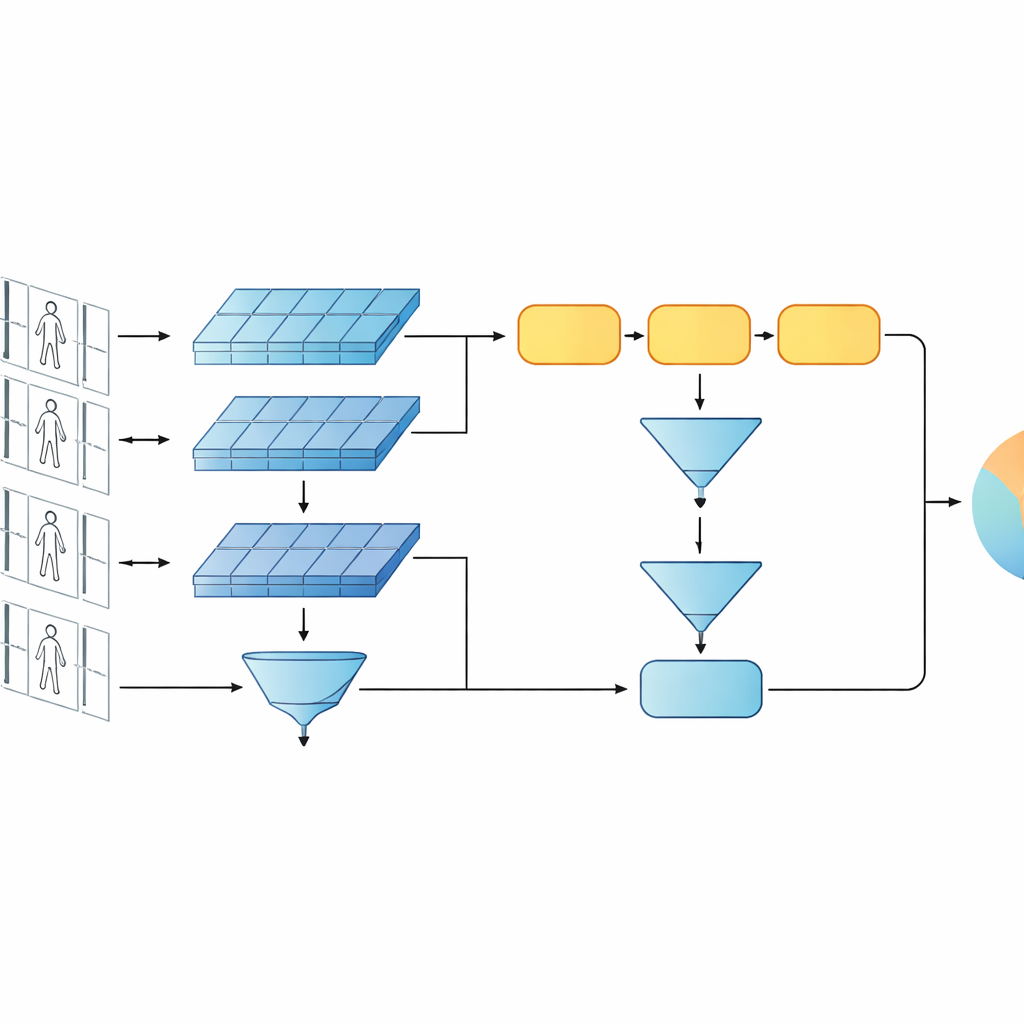
Testing on real surveillance-style videos
The framework is evaluated on two widely used video benchmarks, PRID-2011 and iLIDS-VID, which contain short walking sequences of hundreds of individuals captured from pairs of disjoint cameras. The study carefully probes different design choices: swapping the GRU for other recurrent units, changing how many recurrent layers are used, altering how features are pooled over time, and turning the low- or high-level branches on and off. Across these tests, a single-layer GRU with mean pooling and the full multi-level setup consistently delivers the best accuracy. The model matches or surpasses many more complex recurrent and Siamese systems, and performs competitively with some attention-based designs, while using far fewer parameters and computation.
Efficiency for real-world deployments
Beyond accuracy, the work emphasizes practicality. The entire network has only around one to two million trainable parameters—orders of magnitude fewer than popular deep residual or transformer-based backbones—and requires a fraction of their computing cost per frame. This makes it more suitable for deployment on devices with limited memory and processing power, such as edge servers near cameras. Experiments also show that longer gallery sequences, where the system sees more frames of each stored person, substantially improve recognition, though with a linear increase in processing cost. The authors argue that such compact, carefully designed architectures can deliver reliable person re-identification without the heavy price tag of today’s largest models.
What this means for everyday surveillance systems
In plain terms, this paper demonstrates that smart design can beat sheer size: by combining shallow image analysis, lightweight sequence modeling, and a two-level view of visual similarity, it is possible to track who is who across cameras with high reliability while keeping the model small and fast. For future systems that must run on many cameras, often with tight hardware and energy budgets, this kind of efficient, multi-level approach could help bring more capable and responsible video analytics into real-world use.
Citation: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
Keywords: person re-identification, video surveillance, Siamese neural networks, temporal modeling, efficient deep learning