Clear Sky Science · en
A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs
Turning Everyday Questions into Database Answers
Modern organizations are awash in data, but most people cannot speak the technical language needed to query it. This paper introduces TriSQL, a system that lets users ask questions in plain language and automatically turns them into precise database commands. By carefully managing how large language models handle complexity, the framework aims to make data access both more accurate and more reliable, even for the hardest questions.
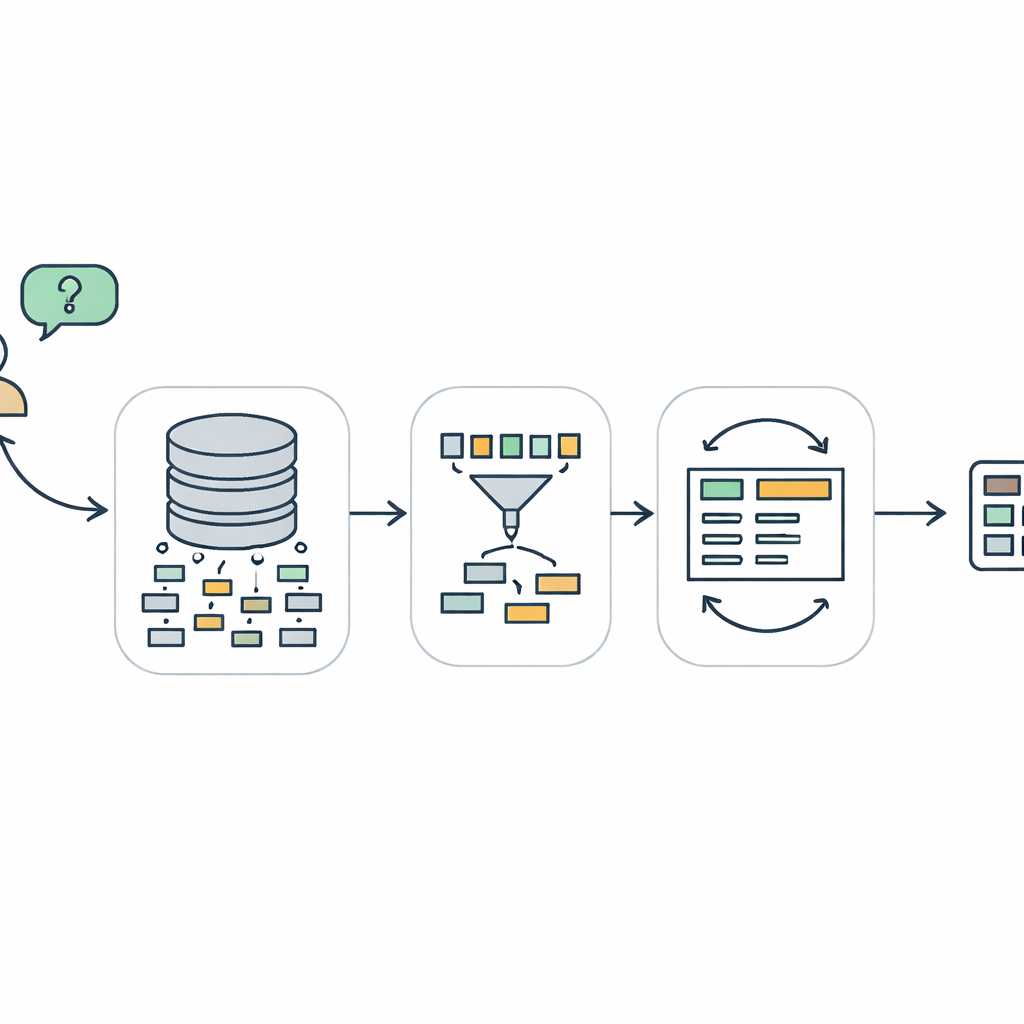
Why Talking to Databases Is So Hard
When someone types a question like “Which customers bought more than five products last month?” a computer must translate that into SQL, the specialized language used by most databases. This task, called text-to-SQL, sounds straightforward but is surprisingly difficult. The system has to understand what the user wants, find the right tables and columns inside a sometimes enormous and messy database, and then build a query that is both structurally valid and faithful to the original intent. Previous systems, including those powered by large language models, often break down when questions involve many tables, nested logic, or subtle conditions. They may produce queries that look similar to correct ones but fail to run or return wrong results once executed.
A Three-Step Path from Question to Query
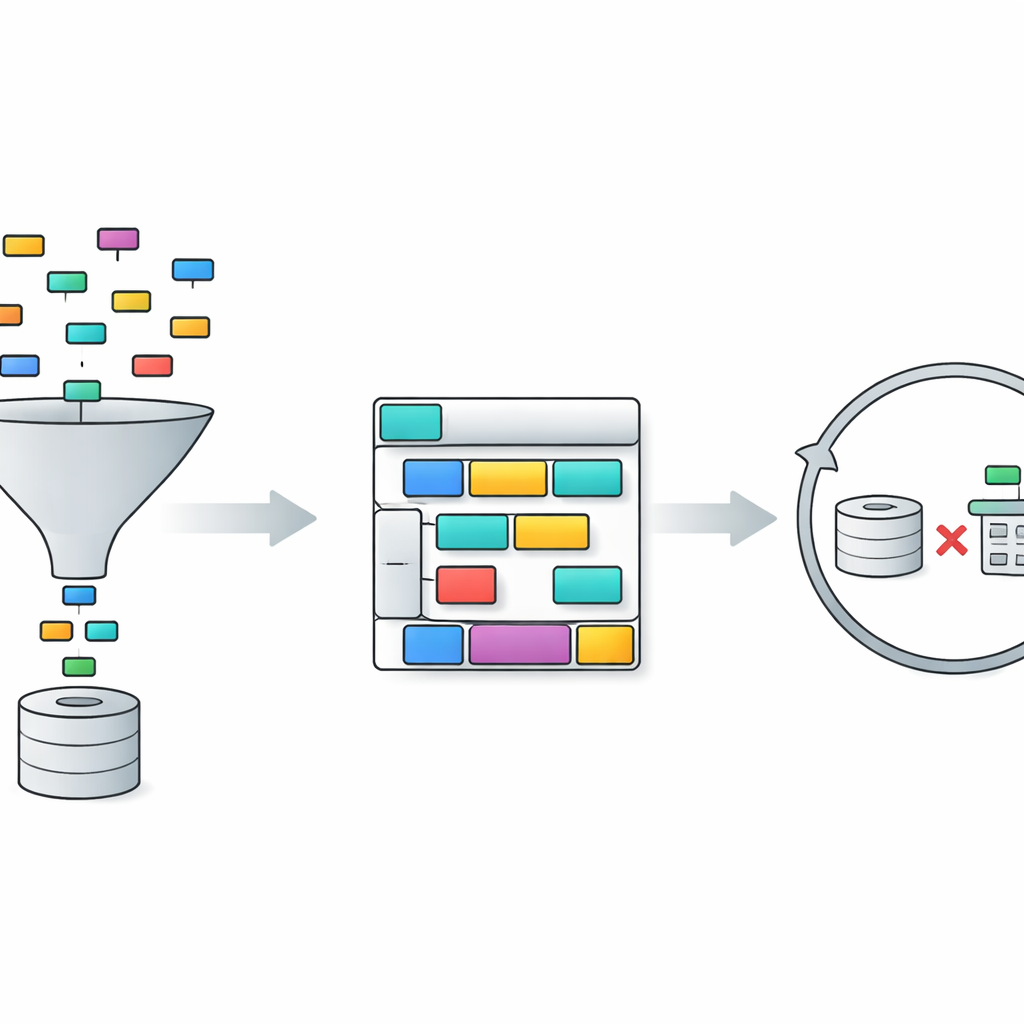
TriSQL tackles these problems with a three-stage pipeline. First, a question-guided selector looks at the user’s words and the full database structure and decides which tables and columns are actually relevant. Instead of blindly exposing the language model to the entire schema, it narrows the view to just the pieces that matter. Second, a structure-aware generator plans the shape of the SQL query before filling in details. It first sketches a high-level skeleton—what clauses are needed and how they fit together—and then inserts specific tables, joins, and conditions. This “structure first, content second” approach helps preserve the rigid grammar of SQL, especially for long and tangled queries. Finally, a complexity-aware refiner checks and improves the initial query, using different strategies depending on how difficult the question appears to be.
Adapting Effort to Question Difficulty
The refinement stage is where TriSQL makes especially novel use of large language models. The system scores how complex each question and draft query are, considering factors such as how many tables are joined, how deep any nesting goes, and what kinds of constraints are used. For simple cases, it applies only light corrections, such as fixing small syntax slips. For medium cases, it reorganizes clauses and ensures that the query lines up with the chosen schema. For the most demanding questions, it invokes the language model for deeper reasoning, sometimes decomposing the problem into subtasks and running alternative queries. Crucially, TriSQL then executes both the original and refined queries against the database and uses their behavior—whether they run, how long they take, and what they return—to decide which version to keep or whether to attempt another refinement round.
Putting the System to the Test
To see how well TriSQL works, the authors test it on a widely used benchmark called Spider, along with several tougher variants that introduce domain knowledge, unusual sentence patterns, and more realistic query structures. They measure two things: exact match, which checks whether the generated SQL string is identical to a human-written reference, and execution accuracy, which checks whether it actually produces the correct answer when run. Across these datasets, TriSQL achieves the highest execution accuracy reported so far while keeping exact match competitive with the best prior systems. It is also more robust: as questions move from easy to extremely hard, TriSQL’s performance drops much more gently than that of competing methods. Additional experiments on a real-world power-grid management dataset show that the same framework can handle not just data retrieval, but also insert, update, delete, and table-creation commands. Pilot adaptations to graph databases (Cypher) and MongoDB pipelines suggest that the three-stage design can extend beyond classic SQL.
What This Means for Everyday Data Use
In plain terms, this work moves us closer to a world where people can converse with complex databases as easily as they now chat with search engines. By carefully choosing which parts of the database to consider, by planning the structure of a query before filling in the details, and by adjusting the use of large language models to the difficulty of each question, TriSQL produces queries that are more likely to run correctly and return the intended results. While challenges remain—such as dealing with ambiguous questions and unseen databases—the study shows that a thoughtful, staged design can make natural-language interfaces to data both more powerful and more predictable for everyday users.
Citation: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
Keywords: text-to-SQL, natural language interfaces, database querying, large language models, query robustness