Clear Sky Science · en
An approach for handling imbalanced datasets using borderline shifting
Why rare cases matter in everyday data
From bank fraud and medical diagnosis to predicting customer churn, many of the decisions we ask computers to make hinge on spotting rare but crucial events. In most real datasets, these important cases are vastly outnumbered by ordinary ones. A model that mostly sees "business as usual" can become blind to the very situations we care about the most. This paper presents a new way to rebalance such skewed data so that learning algorithms pay proper attention to the rare, high‑impact cases.
The hidden trap of lopsided data
When one type of example greatly outnumbers another, standard machine‑learning methods tend to focus on the majority and quietly neglect the minority. A churn‑prediction system, for example, may label almost everyone as a loyal customer and still boast high accuracy, simply because actual churners are so few. Similar issues arise in accident detection, fraud monitoring, and medical screening, where positive cases are rare but costly to miss. Traditional ways to fix this fall into two camps: adjusting the learning algorithm to "care" more about the minority, or reshaping the data itself by either removing some majority cases (undersampling) or creating extra minority cases (oversampling). Popular oversampling tools such as SMOTE generate synthetic minority examples, but they can unintentionally clutter the delicate border region where the two classes meet.
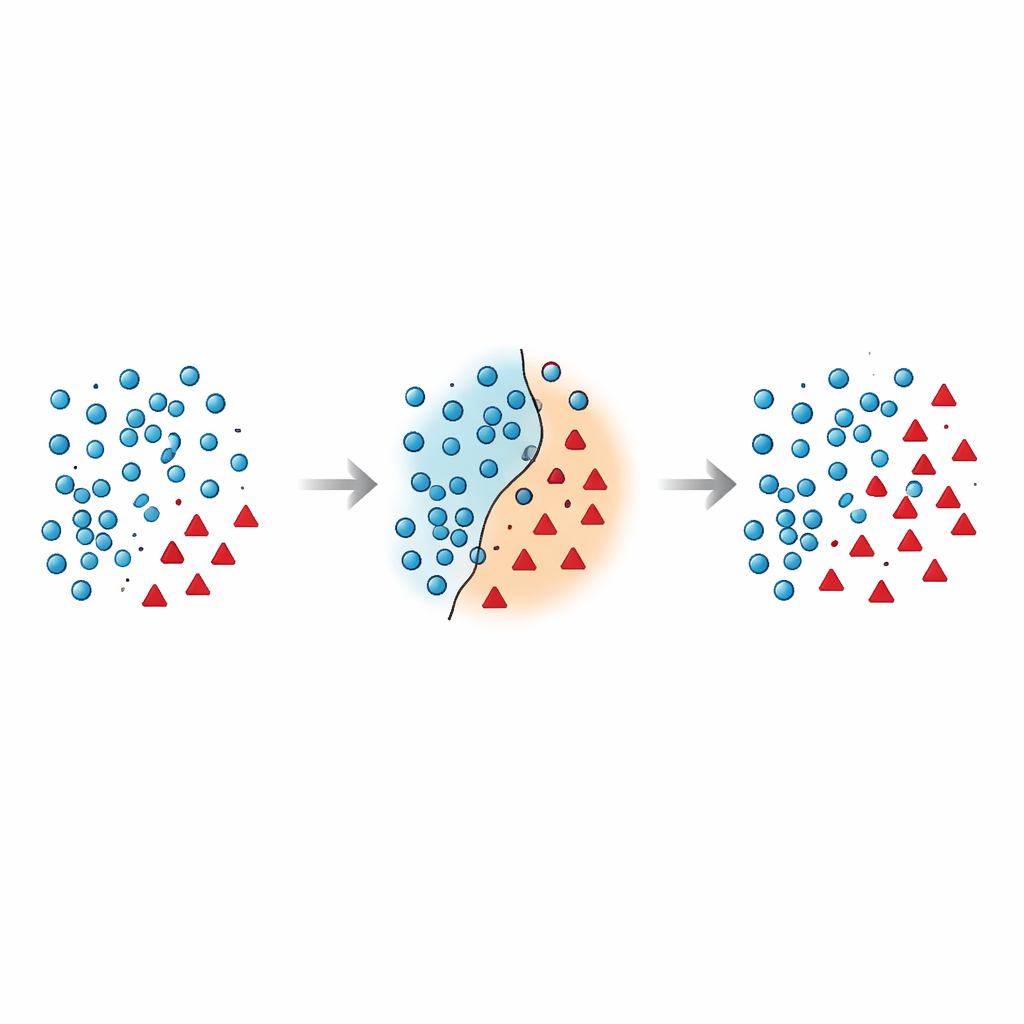
Why the boundary between groups is so fragile
The authors argue that the most dangerous mistakes happen near the decision boundary – the zone where majority and minority cases overlap in the feature space. Many existing techniques either add synthetic points in this risky region without cleaning it up, or they aggressively delete data and accidentally remove informative examples. Recent research has tried to tame this by using geometric constraints, local density estimates, or noise filters, yet most methods still treat minority points in place and rarely rethink how majority points near that boundary should be handled. This leaves a lingering problem: overlapping and noisy samples that confuse the classifier and lead to unstable predictions, especially on new data.
A two‑step way to tidy the border
The paper introduces Borderline Shifting Oversampling (BSO), a two‑phase data‑reshaping method that explicitly targets this problematic boundary region. First, it scans the neighborhood of each majority example to decide whether it lies in a safe zone, on the border, or in a clearly wrong place (noise). Majority points surrounded by minority neighbors are either reclassified toward the minority side or marked as noise and removed, effectively cleaning and shifting the boundary so that it better reflects the underlying pattern. In the second phase, the method generates new synthetic minority points using a SMOTE‑like interpolation, but only around minority samples near the refined boundary. By concentrating new data where it is most informative, and avoiding obviously noisy spots, BSO builds a training set that is both more balanced in size and cleaner in structure.
Putting the method to the test
To see how well this works in practice, the researchers evaluated BSO on 30 benchmark datasets with varying degrees of imbalance and overlap. They compared it with seven widely used alternatives, including Random Over‑ and Under‑Sampling, SMOTE, Borderline‑SMOTE, NearMiss, and two hybrid methods that mix oversampling with noise cleaning (SMOTE‑Tomek and SMOTE‑ENN). Three common classifiers – Support Vector Machines, Naïve Bayes, and Random Forests – were trained on each resampled dataset. Rather than relying on raw accuracy, the study used metrics that are more informative under imbalance, such as F1‑score, G‑mean, recall, precision, and the Area Under the ROC Curve (AUC). Across nearly all datasets and classifiers, BSO delivered higher or comparable scores while showing less variation, meaning its benefits were consistent rather than tied to a particular model or setting.
What this means for real‑world decisions
In everyday terms, the Borderline Shifting approach acts like a careful editor for messy data: it cleans up confusing examples near the dividing line between classes and then adds just enough realistic minority cases in the right places. The result is that learning algorithms become better at recognizing rare but important events without being misled by noisy overlaps. For applications like fraud detection, accident prediction, or medical triage—where missing a minority case can be costly—this method offers a practical way to make models fairer, more sensitive, and more reliable, all while adding only modest computational overhead.
Citation: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
Keywords: class imbalance, oversampling, decision boundary, anomaly detection, machine learning robustness