Clear Sky Science · en
DeCon-Net: decoupled hierarchical contrast for soccer object detection
Why spotting players and the ball is harder than it looks
Modern soccer broadcasts are filled with graphics, statistics, and instant replays, all driven by computer systems that must first answer a deceptively simple question: where are the players and the ball in every frame? This paper tackles why today’s leading artificial intelligence tools still struggle with that basic task in real matches—and introduces a new method, DeCon‑Net, that makes automatic detection of players and the ball much more reliable, especially in messy, crowded scenes.
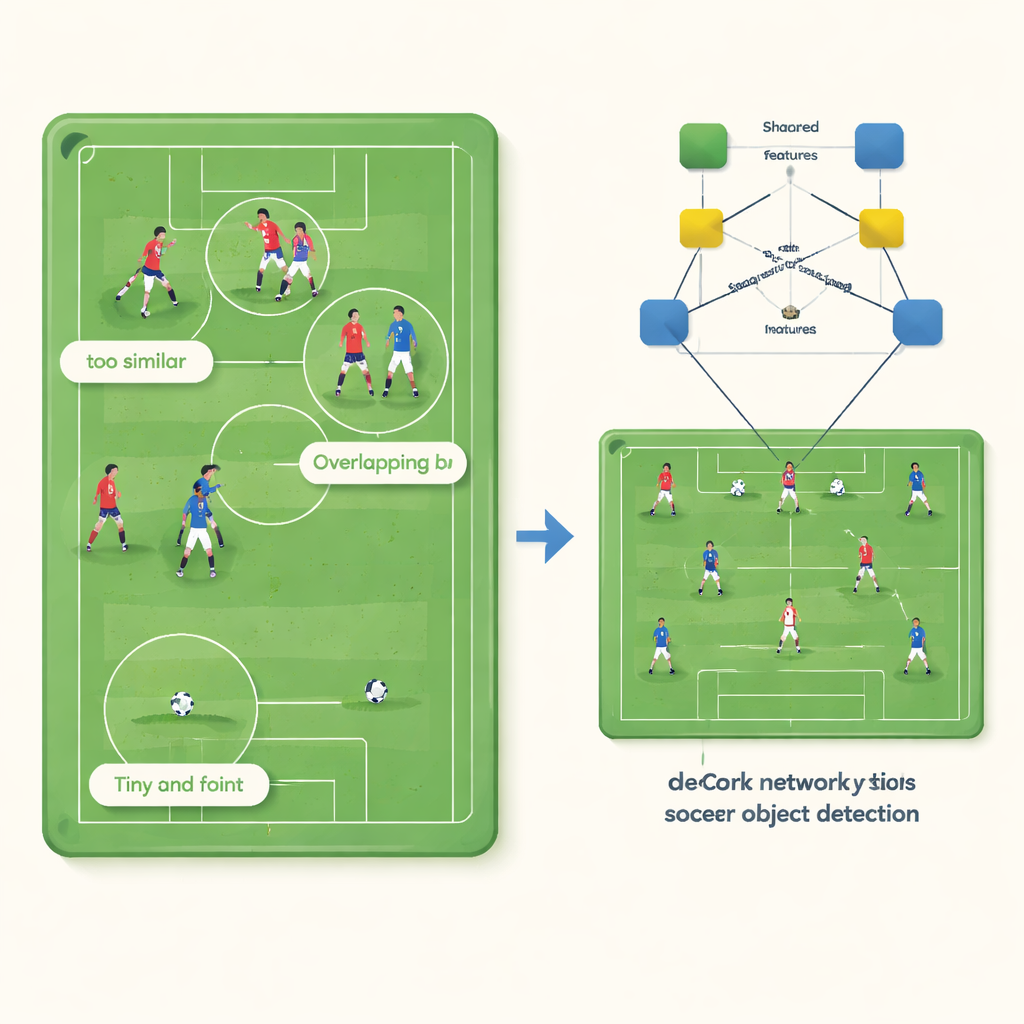
Three hidden problems in soccer videos
At first glance, detecting players and a ball seems straightforward: they move, have clear shapes, and stand out from the pitch. But the authors show that standard computer vision systems suffer from three intertwined problems. First, teammates wearing identical uniforms become almost indistinguishable to the algorithm, whose internal “feature” descriptions of them collapse into nearly identical points. Second, in crowded tussles, players overlap so much that detectors often draw one large bounding box around several people instead of separate boxes for each individual. Third, the ball is tiny—sometimes only a few dozen pixels—and its visual signal is so weak that it can be drowned out by grass texture and player motion, causing the system to miss it altogether.
Breaking apart what the network learns
DeCon‑Net addresses these issues by changing how a neural network represents what it sees in a frame. Instead of letting the model learn one blended description for each object, the authors split that description into two complementary parts. One stream captures what players on the same team share—such as jersey color—while the other stream focuses on what makes each individual unique, like body pose or exact position. A special training trick flips the gradient for the “individual” stream whenever the network tries to use team information there, effectively teaching it to ignore jersey color and concentrate on person‑specific cues. The two streams are then adaptively recombined, so the system can lean more on shared traits in simple scenes and more on individual traits when players crowd together.
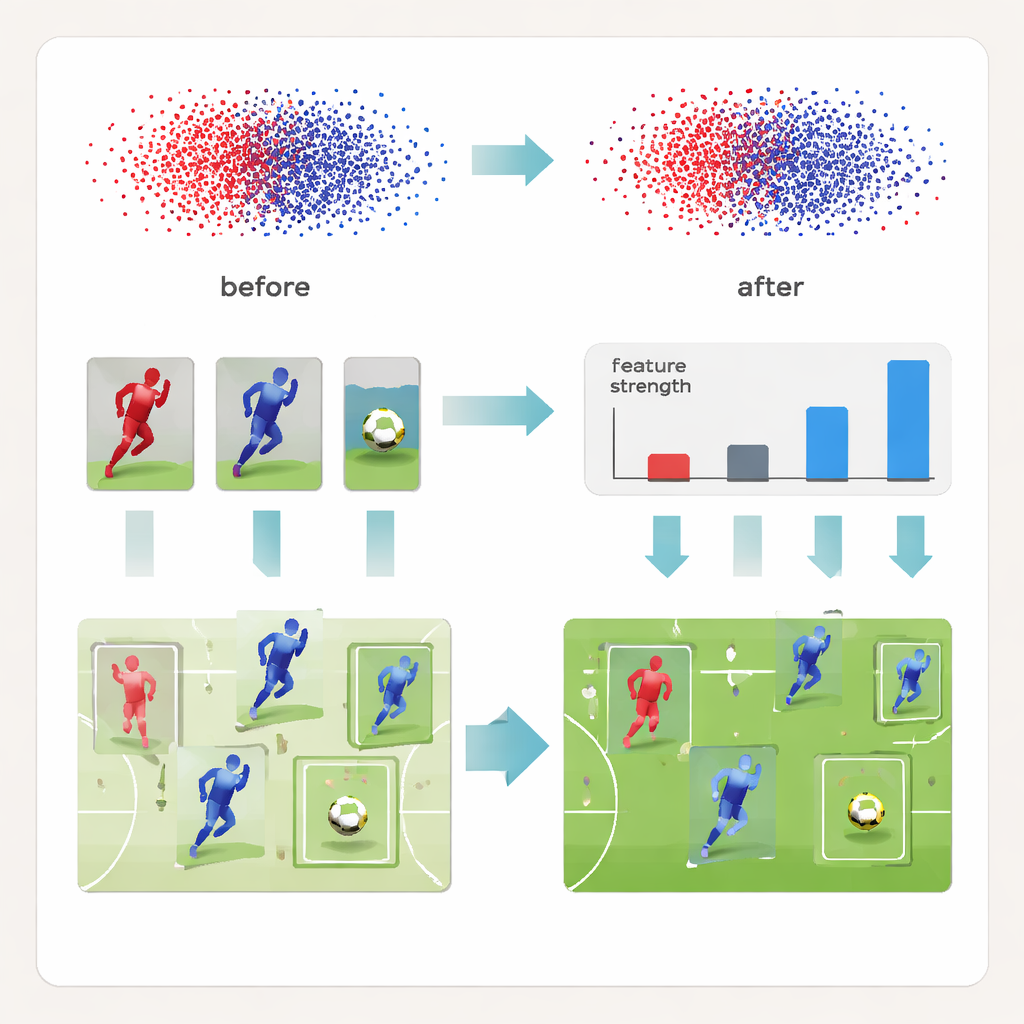
Teaching the model with comparisons, not just labels
Beyond this split representation, DeCon‑Net reshapes learning itself. The method adds a hierarchical “contrastive” training step that constantly compares pairs of detected objects. Pairs that are already clearly different are given gentle nudges, while pairs that look confusingly similar—like two teammates standing shoulder to shoulder—are trained more aggressively to move apart in the network’s internal space. This three‑level strategy starts with easy distinctions, then moves to subtler differences within a team, and finally to variations across different games and broadcast conditions. To rescue the tiny ball from being overlooked, the method also boosts the influence of very small objects during training, making the ball’s signal stand out instead of fading into background noise.
From lab benchmarks to real sports broadcasts
The researchers tested DeCon‑Net on two demanding datasets: SportsMOT, which includes soccer, basketball, and volleyball, and SoccerNet‑Tracking, built from real TV broadcasts with camera zooms, motion blur, and frequent occlusions. Across the board, DeCon‑Net detected both players and balls more accurately than widely used systems built on Faster R‑CNN, DETR, and recent tracking‑oriented methods. The gains were especially striking for the ball, with accuracy jumping by more than 40 percent relative to strong baselines. The system also held up better when applied to a different dataset than the one it was trained on, hinting that its split‑feature design captures more general, reusable cues about sports scenes.
What this means for the future of sports analysis
In everyday terms, the paper shows that many current AI systems “see” soccer in an oversimplified way: they lump same‑team players together and nearly ignore the ball when the action gets hectic. DeCon‑Net counters this by forcing the network to separately learn who belongs to which team and who is which individual, while giving extra attention to tiny, easy‑to‑miss objects. The result is a more precise, reliable map of every player and the ball on the field, frame by frame. That foundation can power better tactical analysis for coaches, richer graphics for broadcasters, and more accurate statistics for fans, bringing us closer to truly intelligent, automated understanding of the game.
Citation: Ouyang, Q., Du, T. & Li, Q. DeCon-Net: decoupled hierarchical contrast for soccer object detection. Sci Rep 16, 7571 (2026). https://doi.org/10.1038/s41598-026-39084-4
Keywords: soccer video analysis, object detection, sports analytics, computer vision, ball tracking