Clear Sky Science · en
RFGLNet for adverse weather domain-generalized semantic segmentation with frequency low-rank enhancement
Seeing the Road When the Weather Turns Bad
Autonomous cars and delivery robots promise safer, more efficient streets—but only if they can reliably “see” the world around them. Rain, fog, snow, and dark nights make that vision extremely hard, washing out contrast, adding specks of noise, and blurring the edges of people, cars, and curbs. This paper introduces RFGLNet, a new computer-vision system designed to keep machines’ understanding of the road sharp even when the weather is at its worst.

Why Bad Weather Blinds Machines
Today’s self-driving systems often rely on a process called semantic segmentation, in which an algorithm assigns a class—like road, car, pedestrian, or building—to every pixel in an image. Under clear daylight, modern neural networks do this remarkably well. Under heavy rain or dense fog, however, images lose brightness, gain noise, and develop fuzzy boundaries between objects. Collecting and labeling massive datasets for every nasty weather condition is prohibitively expensive, so most systems are trained mainly on normal, sunny images. When they face unseen storms or snow, performance drops sharply. Earlier fixes either tried to clean up images first and then segment them, or adapted models to specific target conditions. Both approaches tend to be brittle, slow, or too reliant on labeled bad-weather data.
A New Network Built for Tough Conditions
RFGLNet tackles this problem with a different strategy: it learns only from standard daytime city scenes, yet generalizes to a wide range of harsh conditions. The authors start from DINOv2, a large, pre-trained visual model known for capturing rich scene structure. Instead of retraining this heavyweight backbone from scratch, they freeze its parameters and add a lightweight set of modules on top. These modules act like smart adapters, reshaping the backbone’s internal representations so that they are less confused by visual clutter from snowflakes, raindrops, or darkness. The result is a system that uses only 4.32 million trainable parameters—tiny compared with typical vision models—while still learning to handle weather it has never seen during training.
How the Network Learns to Filter Weather
RFGLNet’s first innovation is a low-rank module that plugs into every layer of the frozen backbone. Before training, this module runs a mathematical procedure known as singular value decomposition on a simulated feature matrix. This gives it a set of compact components that roughly match the structure of DINOv2’s internal features from the start, instead of starting from random noise. During training, these components are adjusted, allowing the module to gently correct the backbone’s features for the new task without disturbing its core knowledge. The network then applies a Fourier-based attention block that shifts the features into the frequency domain. There, broad, slowly varying structures tend to represent meaningful objects, while sharp, erratic patterns often correspond to weather noise. By suppressing high-frequency clutter and amplifying smoother components, the system strengthens global scene understanding while toning down interference.
Sharpening Details Without Getting Distracted
Even with cleaner global features, tiny details such as lane markings, fence rails, and the outline of a distant pedestrian remain vulnerable to blur in bad weather. To address this, the authors introduce a grouped spatial attention module in the decoder portion of the network. Instead of treating all feature channels together, it divides them into groups and learns separate spatial weight maps for each group. Channels that carry important structure, like edges, can then be emphasized, while channels dominated by noise are damped. These group-specific maps are fused into a global spatial weighting that enhances fine details and sharpens object boundaries across multiple resolutions. In effect, RFGLNet learns where to look closely and where to ignore distracting specks of fog or rain.
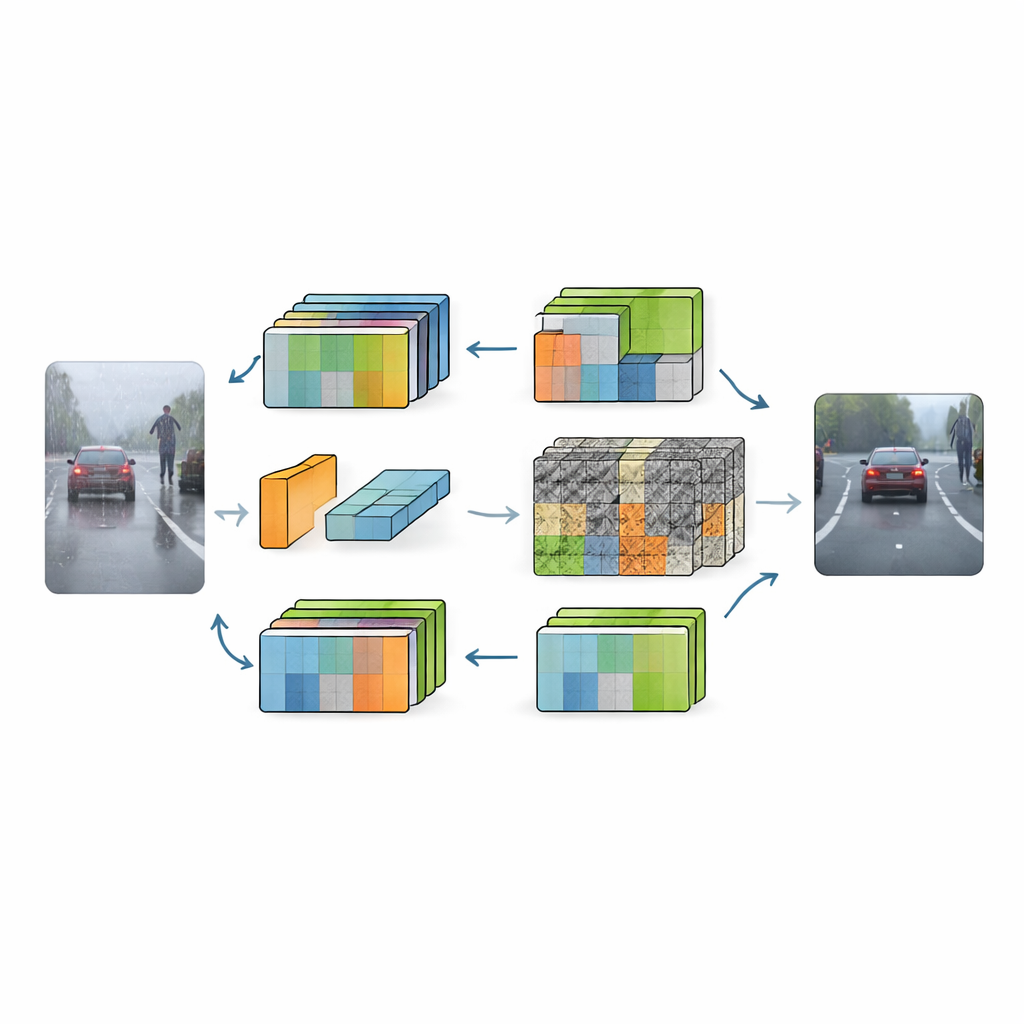
Real-World Payoff on Challenging Road Scenes
To test their approach, the researchers trained RFGLNet on the well-known Cityscapes dataset of clear daytime urban scenes, then evaluated it on the ACDC dataset, which focuses on rain, snow, fog, and nighttime driving. Without ever seeing ACDC labels during training, RFGLNet reached a mean intersection over union of 78.3 percent—outperforming several leading domain-generalization and adaptation methods, many of which are larger and more computationally demanding. It was especially strong at segmenting hard classes like walls and fences, whose edges are easily lost in adverse weather. At the same time, the model ran efficiently on a single consumer-grade GPU, processing dozens of images per second, a key requirement for real-time driving systems.
Clearer Vision for Safer Autonomy
For non-specialists, the takeaway is that RFGLNet shows how to upgrade existing vision backbones for safer autonomy without endless retraining on every possible storm. By combining compact low-rank tuning, frequency-based noise filtering, and grouped spatial attention, the system learns to keep essential scene structure intact while brushing away weather-related clutter. As such methods mature and are trained on broader collections of real-world conditions, they could help self-driving cars and robots maintain reliable situational awareness when the sky turns dark and the road ahead is anything but clear.
Citation: Ye, X., Shi, X. & Li, Y. RFGLNet for adverse weather domain-generalized semantic segmentation with frequency low-rank enhancement. Sci Rep 16, 8253 (2026). https://doi.org/10.1038/s41598-026-39052-y
Keywords: autonomous driving, adverse weather perception, semantic segmentation, computer vision robustness, domain generalization