Clear Sky Science · en
Large language models show Dunning-Kruger-like effects in multilingual fact-checking
Why smart fact-checking matters to everyone
Misinformation now spreads faster than ever, shaping what people believe about health, politics, science, and everyday life. Many platforms and newsrooms are starting to lean on artificial intelligence—especially large language models, or LLMs—to help check whether viral claims are true or false. This study asks a deceptively simple but crucial question: when we let these systems judge facts, how often are they right, how sure do they act, and does that change across different languages and regions of the world?
How the researchers tested AI against real-world rumors
Instead of inventing artificial examples, the authors built their tests from 5,000 genuine claims that professional fact-checking organizations around the world had already investigated. These claims covered 47 languages and came from both the Global North and the Global South, reflecting the messy, multicultural reality of online rumors. Only statements with clear "true" or "false" verdicts—agreed upon by multiple fact-checkers—were included, creating a strong ground truth for comparison.
They then ran nine widely used language models, from smaller open-source systems to advanced commercial ones, on every claim. To mirror how people actually talk to chatbots, most prompts were simple questions like “Is this true?” or “Is this false?”, written in the same language as the claim. A fourth, more professional-style setup used a detailed instruction in English that turned the model into a virtual fact-checker and asked for structured outputs. Human annotators carefully read the models’ answers and labeled them as saying the claim was true, false, or refusing to give a clear verdict.
Measuring not just right or wrong, but also when to say “I don’t know”
The team did more than tally hits and misses. They used three key measures to capture the models’ behavior. First, “selective accuracy” looked at how often a model was correct when it actually took a stand and declared a claim true or false. Second, “abstention-friendly accuracy” treated it as acceptable, even desirable, for the model to admit uncertainty instead of guessing, which is vital in sensitive areas like medicine or elections. Third, the “certainty rate” tracked how often a model gave a definite answer at all, serving as a rough stand-in for how confident it behaved.
The professional-style prompt, with its step-by-step guidance, consistently lifted accuracy across all models. But it also exposed a trade-off: smaller models often became more decisive without becoming more reliable, while larger models used the structure to give fewer, but better, answers. Everyday, chat-like prompts produced more cautious behavior, especially in weaker models, but also somewhat lowered their accuracy.
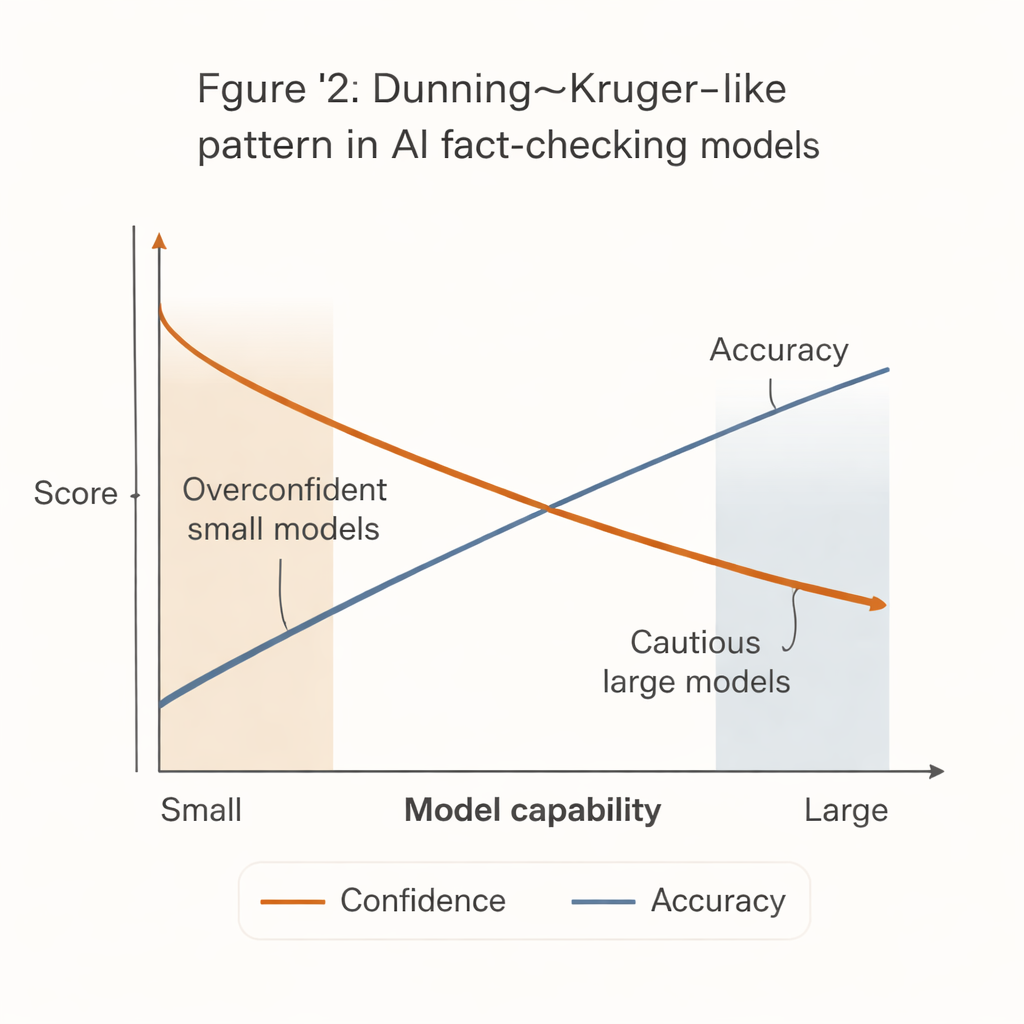
When less capable systems act more sure of themselves
A striking pattern emerged that mirrors the well-known Dunning–Kruger effect in human psychology: the least capable systems acted the most confident. Small, inexpensive models tended to issue firm verdicts on a large majority of claims, but with noticeably lower accuracy. In contrast, the strongest models—such as advanced GPT versions—were far more accurate when they did commit, yet much more likely to abstain, especially on difficult or ambiguous statements.
This “confidence–competence gap” has real-world consequences. Many cash-strapped newsrooms, civil-society groups, and local fact-checking outlets cannot afford the most powerful AI systems. They are more likely to adopt smaller, cheaper models that appear decisive but are more often wrong. If these tools are plugged into workflows or community-moderation systems without careful safeguards, they could actually amplify misinformation by producing confident but incorrect fact-checks.
Unequal performance across languages and regions
The study also reveals that these systems do not perform equally well for everyone. Across several major languages, models generally did best on English claims and slightly worse on Portuguese and Hindi. Larger models tended to respond more cautiously in non-English languages, but still outperformed smaller ones in accuracy. When the authors compared claims tied to the Global North and the Global South, most models stumbled more on the latter. Smaller systems often remained confident while slipping in accuracy, whereas large models showed bigger drops in certainty but smaller drops in correctness, suggesting that they sensed their own uncertainty and held back.
What this means for the future of trustworthy AI tools
For a non-specialist, the core message is clear: today’s AI fact-checkers are far from equal, and the most accessible ones can be the most misleading. Powerful models can be careful and accurate, but they are costly and sometimes overly hesitant. Weaker models are bold but more likely to be wrong, especially outside English and in stories from the Global South. The authors argue that AI should support, not replace, human fact-checkers, and that policy and design choices must push for better calibration—teaching systems when to stay silent—and fairer access to high-quality tools. Otherwise, the same technology built to fight misinformation could deepen the very information inequalities it aims to solve.
Citation: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
Keywords: misinformation, fact-checking, large language models, AI confidence, multilingual bias