Clear Sky Science · en
A hybrid LSTM-GRU framework for lung cancer classification using GWO-WOA algorithm for hyperparameter tuning and BPSO for feature selection
Why this matters for everyday health
Finding lung cancer early can save lives, but many people never get advanced scans until it is too late. This study explores whether simple question-based checkups—about age, smoking, symptoms, and daily habits—can be combined with modern artificial intelligence to spot people at high risk long before severe disease appears. By making the most of inexpensive questionnaires and smart computer models, the work points toward faster, more accessible screening tools that could someday support doctors and public health programs worldwide.
Turning simple questions into useful signals
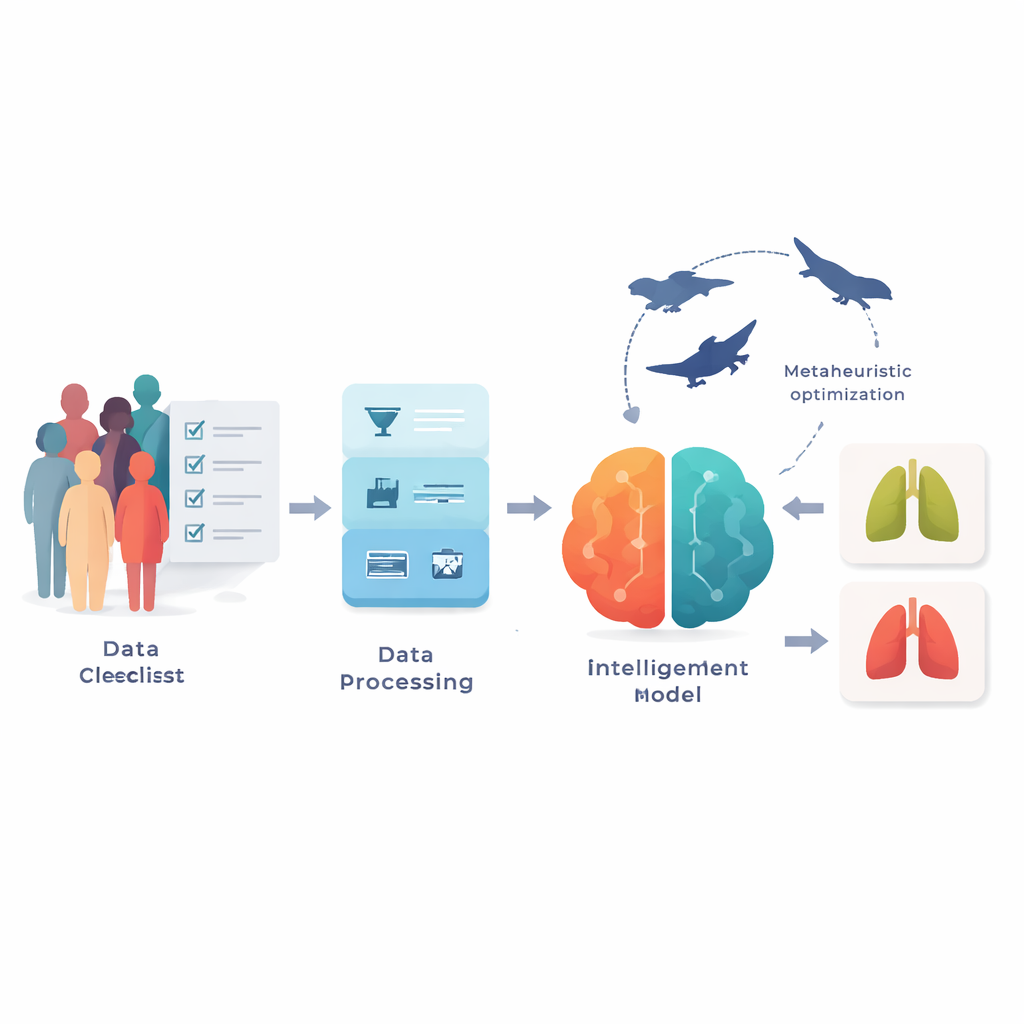
The researchers worked with two public datasets from the website Kaggle, together covering more than 3,300 people. Instead of medical images, each record contains 15 items you might see on a clinic form: age, sex, smoking status, yellowed fingers, coughing, shortness of breath, chest pain, and similar risk factors and symptoms, plus a label indicating whether lung cancer was present. Because real-world survey data are messy, the team first cleaned the information by fixing missing entries, removing duplicates, and aligning how answers were encoded across the two datasets. They also adjusted the numbers so that all features were on a similar scale and used a balancing method to correct a strong tilt toward cancer cases in the smaller dataset, helping the model avoid a bias toward predicting only the majority class.
Letting the computer choose the most telling questions
Not every question on a form is equally helpful for spotting disease, and using too many can actually confuse a model. To focus on what matters most, the authors used a swarm-inspired search strategy called Binary Particle Swarm Optimization. In simple terms, many candidate “question sets” are tested in parallel, and they move through the space of possibilities, copying and improving on the best performers. Over time, this process settled on compact sets of about seven key questions, repeatedly highlighting features such as smoking, yellow fingers, coughing, chest pain, wheezing, shortness of breath, and chronic disease. These focused sets improved accuracy by several percentage points compared with using all 15 questions, while also making the final model easier to interpret and faster to run.

A smarter engine for reading patterns in answers
To turn questionnaire answers into a yes-or-no cancer prediction, the team built a hybrid model that blends two related deep-learning units often used for sequences: Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU). Although survey answers are not time series like speech or video, groups of symptoms and habits still form patterns that can be treated as short sequences. The model first feeds the selected questions through LSTM layers that can store and forget information selectively, then through GRU layers that refine these patterns with fewer internal steps and lower computing cost. To avoid trial-and-error design, the authors tuned crucial settings—such as learning rate, number of hidden units, batch size, and dropout—using a second layer of nature-inspired search that mixes the broad exploration of “grey wolves” with the fine adjustments of “whales.” This joint optimizer searches for hyperparameter combinations that consistently yield high accuracy during cross-validation.
How well the system performed
After training, the hybrid LSTM–GRU model was tested against several strong baselines, including stand‑alone LSTM and GRU networks, a convolutional neural network, traditional support vector machines, and tree‑based methods like random forests and gradient boosting. On the smaller 309‑person dataset, the proposed system correctly classified every single case in the held‑out test split, reaching 100% accuracy, precision, recall, and F1‑score. On the larger 3,000‑person dataset, it stayed near perfect, with about 99.3% accuracy and similarly high scores across other measures, outperforming all rival deep‑learning and classical models. The authors also showed that their two‑stage strategy—first selecting questions with the swarm search, then tuning the hybrid network with the wolf‑and‑whale optimizer—gave more stable results across repeated cross‑validation runs than simpler setups.
What this means for future lung screening
In everyday terms, this work shows that a carefully designed AI system can read ordinary questionnaire answers and very accurately separate people with and without lung cancer in benchmark datasets. It does not replace scans, doctors, or clinical trials, and the authors stress that their data are limited and not yet ready for direct use in hospitals. Still, the approach demonstrates that combining smart question selection with finely tuned deep‑learning engines can turn low‑cost forms into powerful early‑warning tools. With further testing on larger, clinically curated populations and better explanation methods to show why the model flags a person as high risk, similar systems could one day help decide who should be referred for more detailed imaging, supporting earlier diagnosis while keeping screening affordable and non‑invasive.
Citation: Amrir, M.M.S., Ayid, Y.M., Elshewey, A.M. et al. A hybrid LSTM-GRU framework for lung cancer classification using GWO-WOA algorithm for hyperparameter tuning and BPSO for feature selection. Sci Rep 16, 8600 (2026). https://doi.org/10.1038/s41598-026-39020-6
Keywords: lung cancer screening, questionnaire data, deep learning, feature selection, medical AI