Clear Sky Science · en
A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region
Bridging the Communication Gap
For many deaf people, sign language is the main way to communicate, yet most computers, phones, and public services still cannot understand it. This paper presents a new artificial intelligence system that can watch continuous signing in video and turn it into written words more accurately. By paying attention not only to hand movements but also to head position and facial cues, the system aims to make technology-based communication more natural and accessible—especially for deaf communities in the Ha’il region of Saudi Arabia, where digital support is still limited. 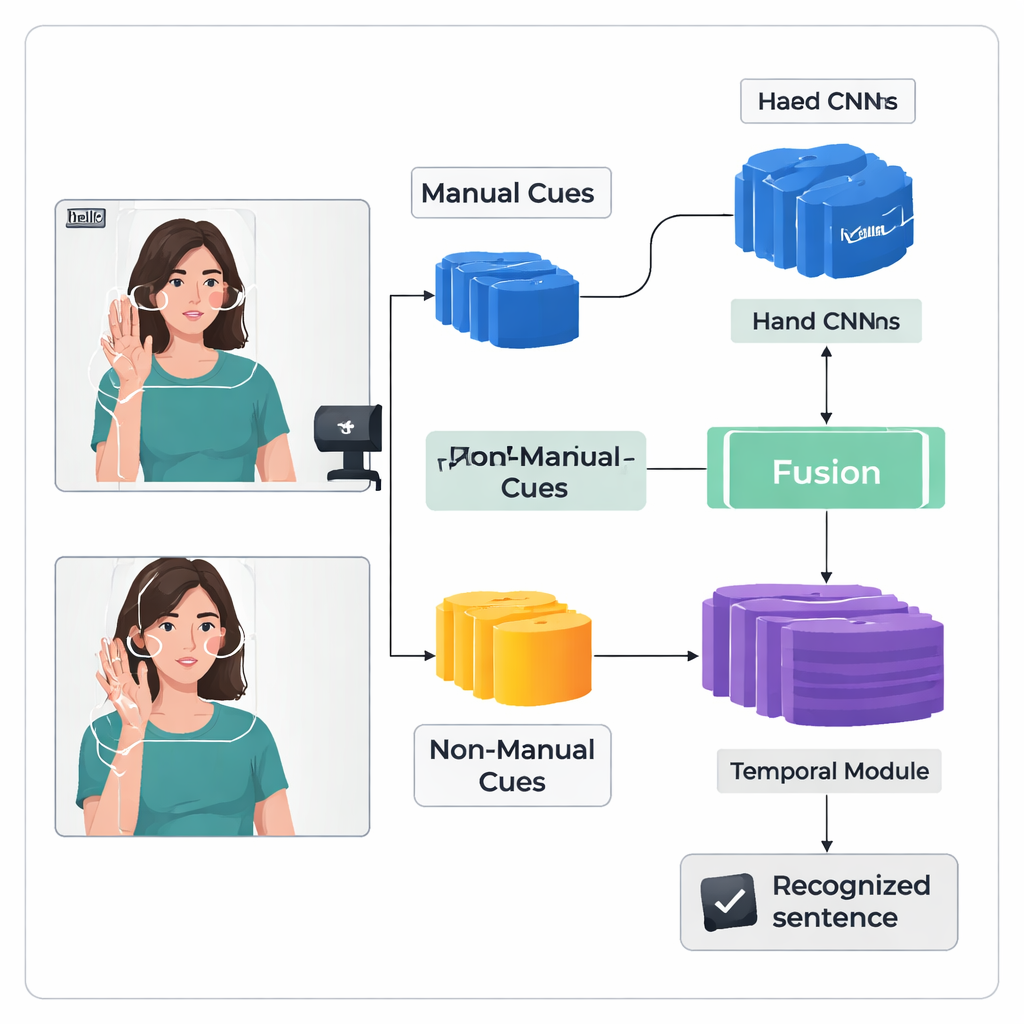
Why Hands Are Not Enough
Sign languages are rich, complex systems that use the whole upper body. Meaning comes not just from how the hands move, but also from facial expressions, where the signer is looking, and how the head tilts or nods. These non-hand signals can mark questions, negation, emphasis, or emotion. Humans read all of this effortlessly, but most computer systems for sign language recognition focus almost entirely on the hands. That shortcut makes training simpler but causes important clues to be lost, especially when signs flow together in rapid, continuous sentences rather than isolated words.
Two Streams Working in Parallel
The authors introduce a "dual-stream" deep learning framework called TS-CNN that processes hands and head separately, then brings them together. One stream focuses on cropped images of the signer’s hands, learning patterns of shape, motion, and position. The other stream receives a compact map of the face and head, derived from landmark points and head-pose estimates. Both streams use a standard type of vision network to turn each video frame into numerical features. The system then fuses these features frame by frame, respecting the fact that hand and head cues occur at the same time in real signing. A later temporal module looks across many frames to understand how signs unfold over time, and a recurrent layer produces a sequence of predicted sign units, or glosses.
Sharpening the System’s Memory of Signs
Recognizing continuous signing is hard because training data are limited and signs blur together without clear frame-by-frame labels. To tackle this, the authors add a Feature Enhancement Module that gives the network extra guidance during training. A widely used technique aligns the predicted gloss sequence with the video, producing probable positions for each gloss in time. The new module takes these alignment suggestions and uses them as direct supervision to refine the internal representation of gloss features. In simple terms, the system learns not only to output the right sequence, but also to build clearer, more consistent internal “memories” of what each sign looks like across different videos.
Putting the Approach to the Test
The team evaluates TS-CNN on two well-known sign language datasets: RWTH-PHOENIX-Weather 2014 for German Sign Language and CSL Split II for Chinese Sign Language. They measure performance using word error rate, a standard metric similar to that used in speech recognition. Compared with a baseline that only looks at hand movements, adding head-pose information cuts errors by around 4 percentage points on the German data and 3–4 points on the Chinese data. Adding the feature enhancement module brings still larger gains, reducing errors by roughly 10–14 percent overall on both datasets. The system also runs efficiently, reaching real-time speeds on a modern graphics processor, which is crucial if it is to be used in live interpretation or mobile tools. 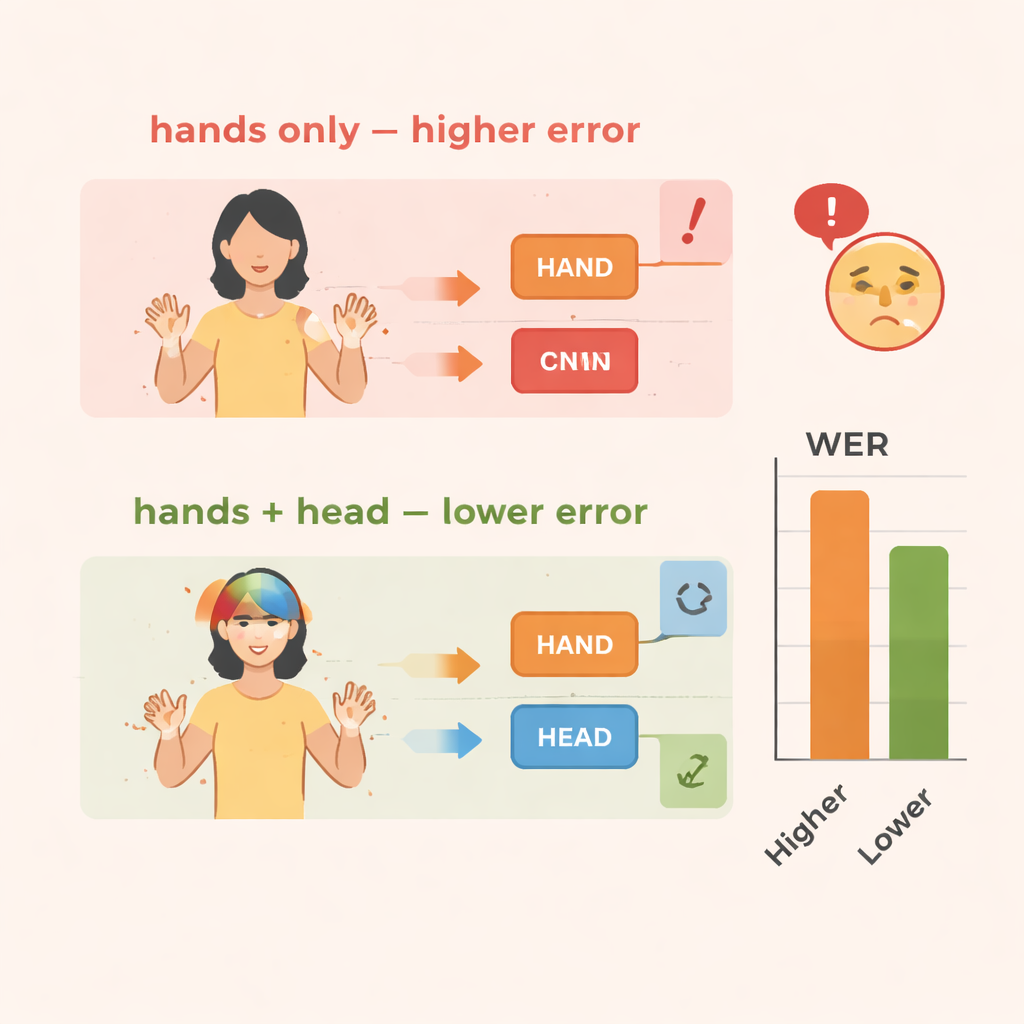
What This Means for Everyday Life
In everyday terms, this research shows that computers can understand sign language more reliably when they watch the whole signer, not just the hands. By modeling head movements and facial cues alongside hand motions, and by carefully refining how it learns from limited training data, the TS-CNN framework moves closer to practical systems that could assist deaf people in classrooms, hospitals, and public offices. For regions like Ha’il, where human interpreters are scarce and technology projects are still emerging, such a system could eventually support more inclusive communication—helping bridge the gap between signers and the hearing world without replacing the rich, human experience of signing itself.
Citation: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
Keywords: sign language recognition, deep learning, accessibility, computer vision, human–computer interaction